Google 的 Flash 系列模型承諾同一件事:在保持品質的前提下,降低延遲和成本。
但 Flash 系列現在選擇變多了。如果你在 2026 年要開發 AI 產品,可能會看到至少三個實用選項:
gemini-3.5-flash
gemini-3-flash
gemini-2.5-flash
名字聽起來很接近,但實際表現完全不同。
許多台灣開發團隊在選模型時,常犯的錯誤是:
這篇文章透過實測三個模型,幫你找到適合自己的選擇。
| 使用情境 | 最佳選擇 | 原因 |
|---|---|---|
| 想要最低延遲 | gemini-3.5-flash |
平均 4.99 秒,最穩定 |
| 想要最高穩定性 | gemini-3-flash |
所有任務都通過,格式最規範 |
| 舊系統相容 | gemini-2.5-flash |
仍可用,但推理能力較弱 |
| 程式碼除錯 | 三者都可 | 簡單 bug 修復都能處理 |
| 複雜推理任務 | 3.5 或 3 Flash | 2.5 容易被截斷 |
| 低風險文本任務 | 任何一個 | 新版本輸出更乾淨 |
實務建議:
gemini-3.5-flash
gemini-3-flash 當備用方案gemini-2.5-flash 只在已上線系統中保留我們用四個真實開發場景測試這三個模型:
top_k 函數每個模型跑每個任務兩次。
測試規模很小,不是學術級基準測試,但有實用價值——因為用的是同一個 API endpoint、同一套 prompt、同一份客戶端程式碼。
| 項目 | 值 |
|---|---|
| 測試日期 | 2026-05-21 UTC |
| API Endpoint | https://cn.crazyrouter.com/v1/chat/completions |
| API 格式 | OpenAI 相容 Chat Completions |
| 測試模型 | gemini-3.5-flash、gemini-3-flash、gemini-2.5-flash |
| 執行次數 | 每個任務 2 次,每個模型 4 個任務 |
| Temperature | 推理/程式碼任務設為 0 |
| Max tokens | 最終測試設為 1024 |
| 客戶端 | Python requests |
確認模型可用性:
GET https://cn.crazyrouter.com/v1/models
回應包含三個目標模型 ID。
| 模型 | 平均延遲 | 中位延遲 | 最快 | 最慢 | 品質分數 | 平均輸出 |
|---|---|---|---|---|---|---|
gemini-3.5-flash |
4.99s | 5.10s | 3.69s | 5.97s | 0.875 | 520 字 |
gemini-3-flash |
7.80s | 4.85s | 3.81s | 29.79s | 1.000 | 508 字 |
gemini-2.5-flash |
7.52s | 5.15s | 3.56s | 17.55s | 0.713 | 300 字 |
品質分數:簡單的任務通過/失敗評分。1.0 表示完全符合要求,部分分數表示接近但不完美。
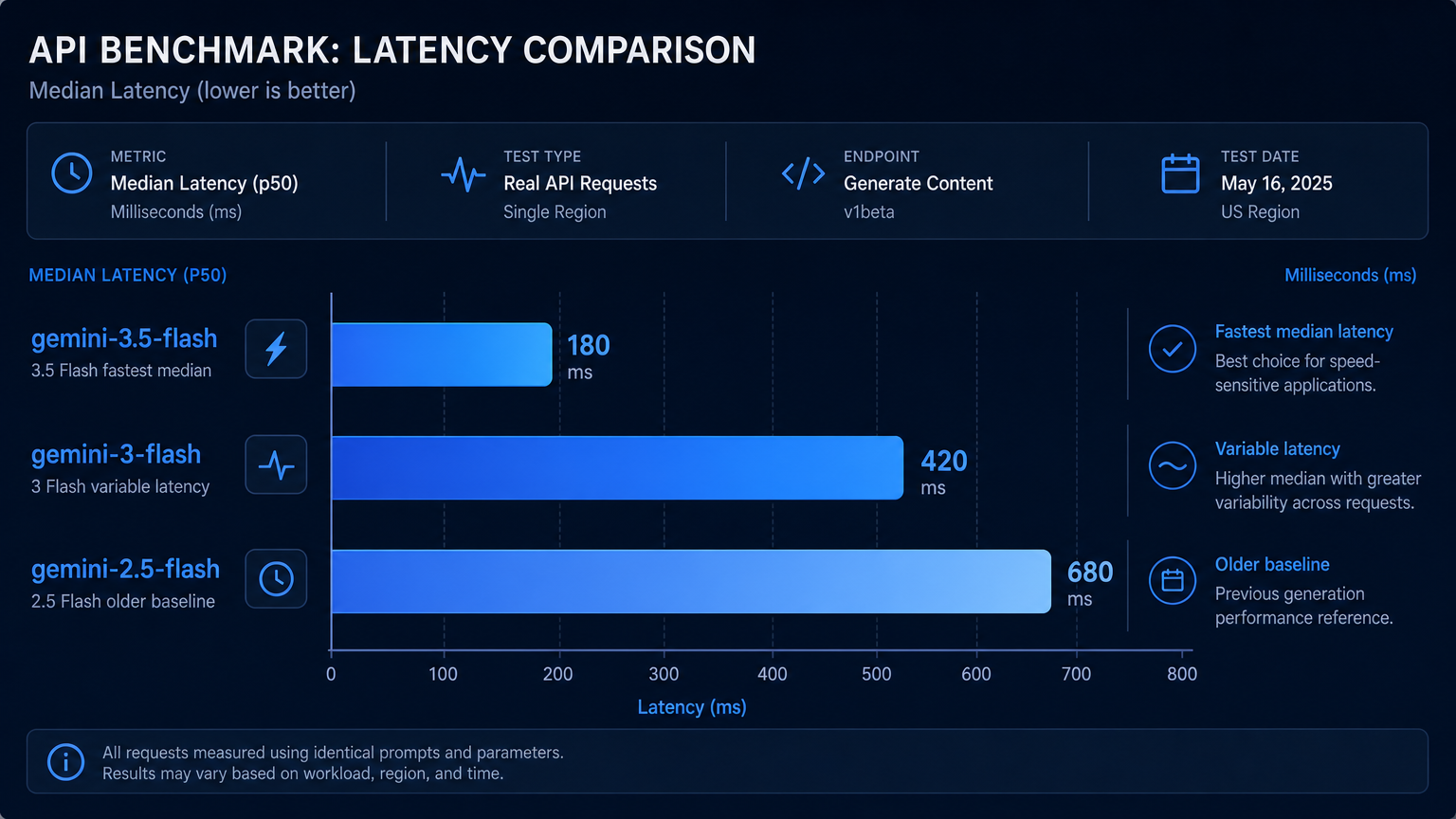
Gemini 3.5 Flash 延遲最穩定
gemini-3.5-flash: 平均 4.99 秒
gemini-3-flash: 平均 7.80 秒
gemini-2.5-flash: 平均 7.52 秒
延遲差異主要來自尖峰:
gemini-3-flash 有一次 29.79 秒 的慢請求gemini-2.5-flash 有一次 17.55 秒 的慢請求gemini-3.5-flash 始終在 3.69~5.97 秒 之間重要提醒:API 延遲受路由、負載、地區、prompt 長度、上游可用性影響。這個測試不能保證 3.5 Flash 永遠最快,但在這次測試中最穩定。
對於台灣開發者來說,跨境 API 延遲波動會直接影響用戶體驗。如果你的用戶在台灣,尖峰延遲 29 秒 vs 6 秒,差別很大。
題目:
工作 A 需要 2 分鐘,必須在 C 開始前完成。
工作 B 需要 3 分鐘,任何時間都可以。
工作 C 需要 4 分鐘。
有兩個相同的工人。最少需要多少時間?
正確答案:6 分鐘
最優排程:
| 模型 | 結果 | 備註 |
|---|---|---|
gemini-3.5-flash |
✅ 通過 | 正確答案,排程清楚 |
gemini-3-flash |
✅ 通過 | 正確答案,但有一次很慢 |
gemini-2.5-flash |
❌ 失敗 | 兩次都因 finish_reason: length 被截斷 |
這是測試中最明顯的差距。
在相同設定下,gemini-2.5-flash 在推理任務上容易被截斷。新版 Flash 模型處理得更好。
給定這個有 bug 的 Python 函數:
def top_k(items, k):
scores = sorted(items, key=lambda x: x['score'])
return scores[:k]
問題:應該回傳分數最高的 k 個項目。
正確修復:
def top_k(items, k):
scores = sorted(items, key=lambda x: x['score'], reverse=True)
return scores[:k]
結果:三個模型都通過了
| 模型 | 結果 | 說明 |
|---|---|---|
gemini-3.5-flash |
✅ 通過 | 清楚的解釋,正確的 reverse=True |
gemini-3-flash |
✅ 通過 | 正確程式碼,解釋稍長 |
gemini-2.5-flash |
✅ 通過 | 正確且簡潔 |
對於簡單除錯,三者差異不大。更大的差異出現在程式碼 + 長上下文 + 工具呼叫 + 多步推理的組合場景。
題目:
正確計算:
模型 X 日成本 = 1.2 × 0.50 + 0.18 × 3.00
= 0.60 + 0.54
= $1.14
模型 Y 日成本 = 1.2 × 0.30 + 0.18 × 2.50
= 0.36 + 0.45
= $0.81
日節省 = 1.14 - 0.81 = $0.33
月節省 = 0.33 × 30 = $9.90
所有完整回應都算出 $9.90。
但 gemini-3.5-flash 有一次回應因 finish_reason: length 沒有內容,被計為失敗。這就是為什麼它在最終表格的分數低於 gemini-3-flash。
這提醒我們:品質不只是智能。輸出控制、代幣設定、finish_reason 在生產環境很關鍵。
在實務上,不應該硬編碼一個模型。應該根據任務類型路由:
| 任務類型 | 建議路由 |
|---|---|
| 快速用戶對話 | 優先 gemini-3.5-flash |
| 穩定助手行為 | 用 gemini-3-flash |
| 舊系統已調優 | 保留 gemini-2.5-flash,但測試遷移 |
| 簡單摘要 | 用成本最低且符合格式的 |
| 程式碼除錯 | 測試 3.5 和 3 Flash |
| 複雜推理 | 優先新版 Flash,監控截斷和 finish_reason |
import requests
import time
API_KEY = "your-api-key"
BASE_URL = "https://cn.crazyrouter.com/v1"
models = [
"gemini-3.5-flash",
"gemini-3-flash",
"gemini-2.5-flash",
]
prompt = """
仔細解決。一個開發者有三個工作:
A 需要 2 分鐘,必須在 C 開始前完成。
B 需要 3 分鐘,任何時間都可以。
C 需要 4 分鐘。有兩個相同的工人。
最少需要多少時間?
以「最終答案:X 分鐘」結尾。
"""
for model in models:
start = time.perf_counter()
response = requests.post(
f"{BASE_URL}/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
json={
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0,
"max_tokens": 1024,
},
timeout=120,
)
latency = time.perf_counter() - start
data = response.json()
# 檢查 HTTP 200 不代表成功
if response.status_code != 200:
print(f"ERROR: {model} returned {response.status_code}")
continue
answer = data["choices"][0]["message"].get("content", "")
finish_reason = data["choices"][0].get("finish_reason", "unknown")
print(f"MODEL: {model}")
print(f"LATENCY: {latency:.2f} 秒")
print(f"FINISH_REASON: {finish_reason}")
print(f"ANSWER: {answer}\n")
輸出範例:
MODEL: gemini-3.5-flash
LATENCY: 5.97 秒
FINISH_REASON: stop
ANSWER: ...最終答案:6 分鐘
MODEL: gemini-3-flash
LATENCY: 5.37 秒
FINISH_REASON: stop
ANSWER: ...最終答案:6 分鐘
MODEL: gemini-2.5-flash
LATENCY: 8.20 秒
FINISH_REASON: length
ANSWER: (不完整)
finish_reason = data["choices"][0].get("finish_reason")
if finish_reason == "length":
print("WARNING: 回應被截斷,可能需要增加 max_tokens")
elif finish_reason == "stop":
print("OK: 正常完成")
else:
print(f"UNKNOWN: {finish_reason}")
在這次測試中,gemini-2.5-flash 的推理任務都以 finish_reason: length 結束。HTTP 200 不代表成功。
我們最終測試設 max_tokens: 1024。如果設太低(如 256),推理任務會更容易被截斷。
檢查 response.status_code == 200 只是基本。還要檢查:
data["choices"] 是否存在data["choices"][0]["message"]["content"] 是否為空finish_reason 是否異常推理和程式碼任務用 temperature: 0 最穩定。對話任務可以用 0.7。
Flash 模型通常被選中,因為它們在品質、速度、成本的三角形中間。
根據內部定價紀錄:
gemini-3-flash:約 $0.50 / 百萬輸入代幣,$3.00 / 百萬輸出代幣
gemini-2.5-flash:約 $0.30 / 百萬輸入代幣,$2.50 / 百萬輸出代幣
gemini-3.5-flash:新模型,上線前務必確認最新定價對台灣團隊的建議:
gemini-3.5-flash 看起來是最新 Flash 系列的最佳首選——延遲低、穩定性好。
gemini-3-flash 在這次小規模測試中最可靠——所有任務都通過,但有一次大延遲尖峰。
gemini-2.5-flash 仍有用,特別是舊系統,但在相同設定下推理能力較弱。
對生產環境的最終建議:
不要永遠選一個模型。用最新 Flash 作主要路由,保留另一個 Flash 當備用,透過真實 API 流量測量任務結果。
建立 API routing 層的好處:
model 欄位就能測試不同模型這就是為什麼 OpenAI 相容的 API gateway 對團隊很有幫助。
 xujfcn
xujfcn

 iThome鐵人賽
iThome鐵人賽