昨天提到MapReduce可以讀取HDFS上的檔案,然後根據檔案的Block數量,產生對應的Map數,接著再透過Reduce輸出到HDFS上。
前面可以知道HDFS基本上會把檔案切成好幾塊,每塊都有對應的副本數,那HDFS是怎麼運作了呢?
如何確保檔案不會遺失?今天就來介紹HDFS吧~
HDFS全名為Hadoop Distributed File System,是Hadoop 分散式檔案系統,
主要由NameNode與DataNode組成,也就是MapReduce會使用的jobtracker與tasktracker。
在正常沒有的HA的架構下,NameNode與DataNode是屬於一對多的關係,NameNode上會記錄所有檔案的MetaData以及這些檔案的Block分別存放到那些DataNode上。
NameNode上所存放的MetaData非常重要,基本上MetaData遺失或損毀,資料是很難救回來了。
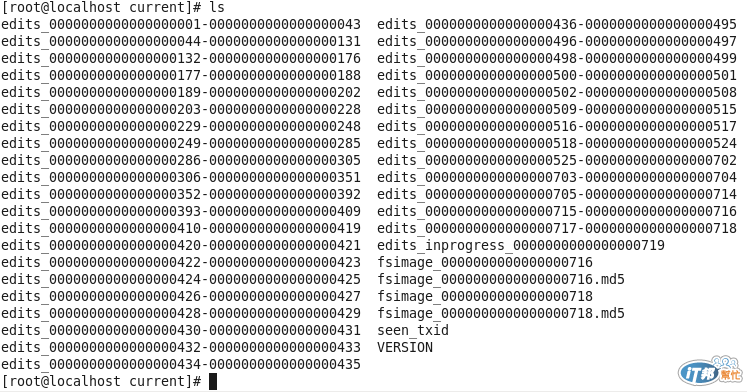
從NameNode的MetaData存放目錄下可以看到有幾個檔案,
分別是edits_*、edits_inprogress_*、fsimage_*還有seen_txid,
fsimage所存放的是所有目錄與檔案索引,NameNode會將實體的檢覈資訊儲存在這邊。
當HDFS的檔案目錄有異動的時候,會先寫在edit_inprogress_*,一定時間後namenode會將edit_inprogress_* rolling為edits_*。
當hdfs重啟的時候,fsimage會載入到namenode的記憶體中,並且再將edit_*的操作步驟執行一次,接著比對是否和現行的檔案目錄結構一樣。
seen_txid非常重要,它代表的是namenode裡面edits_* 的尾數,namenode重啟的時候,會按照seen_txid的數字,循序從頭跑edits_0000001~到seen_txid的數字。
所以當你的hdfs發生異常重啟的時候,一定要比對seen_txid內的數字是不是你edits最後的尾數,不然會發生建置namenode時metaData的資料有缺少,導致誤刪Datanode上多餘Block的資訊。




 iThome鐵人賽
iThome鐵人賽