先補這一篇的債
如果當你發現BeautfisulSoup解析出來的數據為亂碼時,先檢查requests的內容是否也是亂碼
具體作法我們來測試一個網址
從中央氣象局取得一周內的預報資料:
(http://www.cwb.gov.tw/V7/forecast/week/week.htm )
from bs4 import BeautifulSoup
pageRequest = requests.get('http://www.cwb.gov.tw/V7/forecast/week/week.htm')
print(pageRequest.text)
當我們使用從requests返回來的方法.text時我們會發現他的中文變成了亂碼
你可以先看一下response的content
print(pageRequest.content)
如果正常的話那在requests的時候最好增加一個我們要用什麼樣的編碼來處理這個response
避免出現這樣的狀況
print(pageRequest.encoding)
當我們查看requests回傳的編碼的時候,發現他是ISO-8859-1並非是UTF-8
我們可以用以下方是改成utf-8
soup = BeautifulSoup(pageRequest.content, 'html.parser')
soup.encoding = 'utf-8'
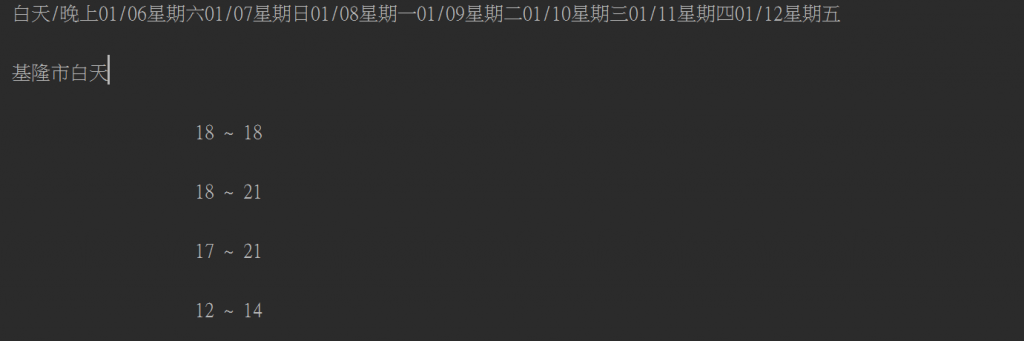
weather = soup.find(attrs={"class":"BoxTableInside"}).text
print(weather)
soup.encoding可以定義要用何種方式做編碼解析
這樣一來我們的文字就是正常的中文了
如下圖:



 iThome鐵人賽
iThome鐵人賽