讓我們從 Linked List 的資料結構下手,了解如何在 Multi-Thread 中維護一個 Linked List
參考 The Art of Multiprocessor Programming, Revised Reprint (English) 1st 版本 第九章的範例,以 C 語言進行改寫,但請注意程式碼是不可執行,或者說含有錯誤,比如說:我並沒有檢查指標是否為 NULL,只是示意邏輯長什麼樣子,所以也不探討要用 mutex、semaphore、spinlock 會有啥區別
PS:我覺得 C 語言的程式碼,我現在這種寫法的可讀性很低== Sorry
從資料結構的定義以及一個 add function,就能了解這個要怎麼去作 Lock,以下為幾種可能使用的方法
typedef struct __NODE {
int val;
struct __NODE *next;
} NODE;
typedef struct __NODE {
int val;
struct __NODE *next;
} NODE;
typedef struct {
NODE *head;
pthread_mutex_t mutex;
} LIST;
每次進行操作,都把整個 LIST 鎖起來,以下範例是假設 Linked List 中的數字由小到大排序
void add(NODE *head, int newVal) {
NODE *curr, *pred;
pthread_mutex_lock(mutex);// 在最外面鎖起來
pred = head;
curr = pred->next;
while(curr->val < newVal) {
pred = curr;
curr = curr->next;
}
NODE *new = malloc(sizeof(NODE));
new->val = newVal;
new->next = curr;
pred->next = new;
pthread_mutex_unlock(mutex);
}
typedef struct __NODE {
int val;
struct __NODE *next;
pthread_mutex_t mutex;
} NODE;
比起 Coarse-Grained 演算,Fine-Grained 明顯粒度變細,只需要在修改的節點上鎖就好,以下的程式碼就是同時有兩個 Lock ,這樣一直鎖過去
void add(NODE *head, int newVal) {
NODE *pred;
pred = head;
pthread_mutex_lock(head->mutex);// 鎖起來
Node *curr = pred->next;
pthread_mutex_lock(curr->mutex);// 連續鎖了兩個
while(curr->val < newVal) {
pthread_mutex_unlock(pred->mutex);// 馬上解放上一層
pred = curr;
curr = curr->next;
pthread_mutex_lock(curr->mutex);// 鎖住下一層
}
NODE *new = malloc(sizeof(NODE));
new->val = newVal;
new->next = curr;
pred->next = new;
pthread_mutex_unlock(pred->mutex);
}
雖然 Fine-Grained 對效能來說有所改善,但他實在有太多的 Lock 了,可能會產生很多問題,比如:有個 Thread 正在修改第二個 NODE,同時有另外一個 Thread 想要作搜尋,但因為第二個 NODE 已經被鎖住了,所以就無法繼續進行
所以就有了 Optimisic Synchronization 這樣方式產生,不需要每次都 Lock,因為你並沒有要更改他,等到要更改的時候,再一口氣 Lock 就好
// 確認是否還連在一起
int validate(NODE *head, NODE *pred, NODE *curr) {
NODE node = head;
while(node->val <= pred->val) {
if(node == pred)
return pred->next == curr;
node = node->next;
}
return 0;
}
void add(NODE *head, int newVal) {
while(true) {
NODE *pred = head;
NODE *curr = pred->next;
while(curr->val <= newVal) {
pred = curr; curr = curr->next;
}
// 先執行 while 搜尋後,才開始
pthread_mutex_lock(pred->mutex);
pthread_mutex_lock(curr->mutex);
if(validate(head, pred, curr)) {
NODE *new = malloc(sizeof(NODE));
new->val = newVal;
new->next = curr;
pred->next = new;
}
pthread_mutex_lock(pred->mutex);
pthread_mutex_lock(curr->mutex);
}
}
在 Optimistic Synchronization 中,其實會浪費很多時間在查找比較,可以用空間換取時間,也大幅減少 Lock ,比如說只是想要查找 Linked List 中是否有存在這個節點,也不需要特別 Lock ,可以透過 marked 參數來來作判斷
typedef struct __NODE {
int val;
int marked;
struct __NODE *next;
pthread_mutex_t mutex;
} NODE;
int validate(NODE *pred, NODE *curr) {
return !pred->marked && !curr->marked && pred->next==curr;
}
void add(NODE *head, int newVal) {
while(true) {
NODE *pred = head;
NODE *curr = pred->next;
while(curr->val <= newVal) {
pred = curr; curr = curr->next;
}
// 先執行 while 搜尋後,才開始
pthread_mutex_lock(pred->mutex);
pthread_mutex_lock(curr->mutex);
if(validate(pred, curr)) {
NODE *new = malloc(sizeof(NODE));
new->marked = 0;
new->val = newVal;
new->next = curr;
pred->next = new;
}
pthread_mutex_lock(pred->mutex);
pthread_mutex_lock(curr->mutex);
}
}
專案參考 sysprog21/mergesort-concurrent
看看一般實做上會如何管理 Thread,通常會實作一個 Thread Pool 來管理,整體的架構如下圖所示,有一個 Thread Pool 物件在管理每個 Worker Thread,他們之間透過 Queue 來作溝通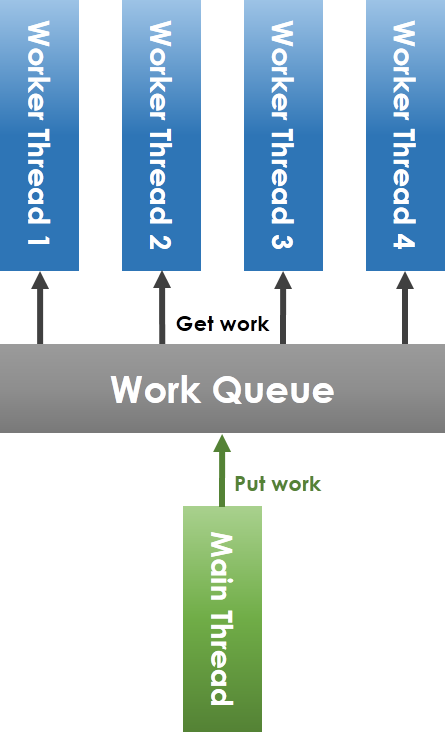
typedef struct _task {
void (*func)(void *); /**< Pointer to task function */
void *arg; /**< Pointer to the arguments passed to _func_ */
struct _task *next; /**< Pointer to the next task */
} task_t;
typedef struct {
task_t *head; /**< Pointer to the fist _task\_t_ in queue */
task_t *tail; /**< Pointer to the last _task\_t_ in queue */
pthread_mutex_t mutex; /**< The mutex lock of this queue */
pthread_cond_t cond; /**< The conitional variable of this queue */
uint32_t size; /**< The size of the queue */
uint32_t num_of_consumed; /**< The number of consumed tasks */
} tqueue_t;
typedef struct {
pthread_t *threads; /**< Pointer to the array of threads */
uint32_t count; /**< Number of working threads */
tqueue_t *queue; /**< Pointer to the task queue */
} tpool_t;
定義了三種資料結構
task_t
function pointer 用來指示要呼叫什麼 function
void* 用來存取任意型態的參數
next 指向下一個 task 形成一個 Queue
tqueue_t
與一般的 Queue 相比,多了 mutex lock 以及 conditional variable
conditional variable 比較特別一點,是用來通知其他 thread 要幹麻之類的,但這個專案目前還沒有使用到
tpool_t
threads 記錄全部的 Worker
queue 為任務列表
這邊使用到的 count ,都是使用 uint32_t 進行宣告,是為了要使用 <stdint.h> 裡透過 typedef 重新定義的 int,因為不同的機器架構中,WORD 的長度不太一樣,使用透過 typedef 的 int,程式碼會比較容易維護
在 Queue 方面,只有進行修改時要 Lock,所以不在此多作琢磨,比較值得一提的點在於「如何把 Queue 中的任務分派出去,又是如何收回」,基本上都是透過 Queue 來作溝通,如果有收回結果的需求,就需要在另外宣告一個 Queue 用作 Output 使用,至於要如何對應到哪一個任務完成了,這要在資料結構中新增個 Label 或是 TaskType 之類的,來加以辨識
以目前這個專案來說,因為是要實作 mergesort,他們是直接去對原始的資料進行操作,就沒有另外宣告
明天就來看以上那份專案,是該如何實做成 Concurrent 的形式,如果我改不出來的話,題目就改成單純介紹 Concurrent Linked List 如何實作@@

