Ohara 的 Pipeline 資料流系統主要是由 Apache Kafka 的 Connector 和 StreamApp 組合而成的。
Ohara 官方有實作一些 Kafka 的 Connector,像是 JDBC Source Connector、FTP Source Connector、HDFS Sink Connector 和 FTP Sink Connector…等等,JDBC Source Connector 是一個 Connector 的程式,會使用 JDBC Driver 連到資料庫裡面去撈資料並把資料寫入到 Kafka 的 Topic 裡,FTP Source Connector 是使用 FTP 的 API 到 FTP Server 撈資料並把資料寫入到 Kafka 的 Topic 裡, HDFS Sink Connector 是把 Kafka Topic 裡的資料寫入到 HDFS Storage 裡,FTP Sink Connector 是把 Kafka Topic 裡的資料寫入到 FTP 的檔案系統裡。簡單的說 source connector 是一個資料來源的程式會把資料寫入到 Kafka Topic 裡,sink connector 是一 個從 Kafka Topic 去讀取資料,然後把資料寫入到某一個目的端裡。
Ohara 實作這些 Connector 的目的主要就是可以盡量讓使用者可以不用撰寫 Connector 程式就可以把資料寫入到 Kafka Topic 裡,或是從 Kafka Topic 裡面去讀取資料並寫入到目的的存儲系統裡。Ohara 最大的目標就是要讓使用者可以不用懂 Apache Kafka 就可以根據需求建立自已想要的 Pipeline,把資料寫入到一個目的端的儲存系統,像是 Ftp、HDFS... 等等的儲存系統,下圖是常見的使用情境: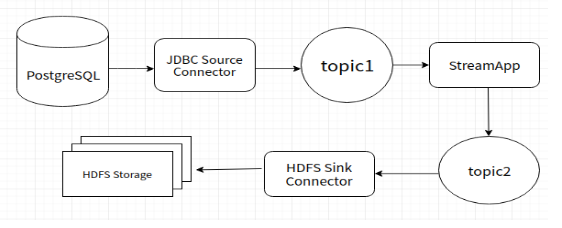
上圖的使用情境,主要的目的是要把資料庫的資料存到 HDFS Storage 裡。在 JDBC Source Connector 就會使用 JDBC Driver 連到資料庫並使用 SQL 語法把 ResultSet 的資料寫入到 topic1,之後有一個 StreamApp 程式去做資料的過濾或是 Aggregate 像是 count、sum、max、min... 等等,可以根據需求去實作相對應的 StreamApp 程式,之後再把 StreamApp 算出來的結果寫到 topic2,最後再使用 HDFS Sink Connector 把資料最終的結果寫入到 HDFS Storage。以上 Pipeline 的流程就可以把資料做解耦合,放入 topic 裡的資料可以給不同的 Connector 或是 StreamApp 使用,增加資料的重覆使用性,如果有不同的查詢或是運算需求就可以不用重新到 Database 去查詢資料,直接透過 StreamApp 程式或是 Connector 程式從 topic 裡去取得資料,就可以減少資料庫做查詢和運算的負擔。
另外如果官方實作的 Connector 無法達成需求,也可以另外來實作 Ohara 提供的 Connector API, 主要的好處是,在實作上比實作 Apache Kafka 簡單很多,因為把很多設定和實作封裝起來,因此開發者只要簡單的實作幾個方法,就可以做到 source connector 或是 sink connector,關於 Ohara Connector 的實作在之後會再做介紹。


 iThome鐵人賽
iThome鐵人賽