
這篇文章會介紹 Elastic Machine Learning 中的名詞、相關流程與案例介紹。
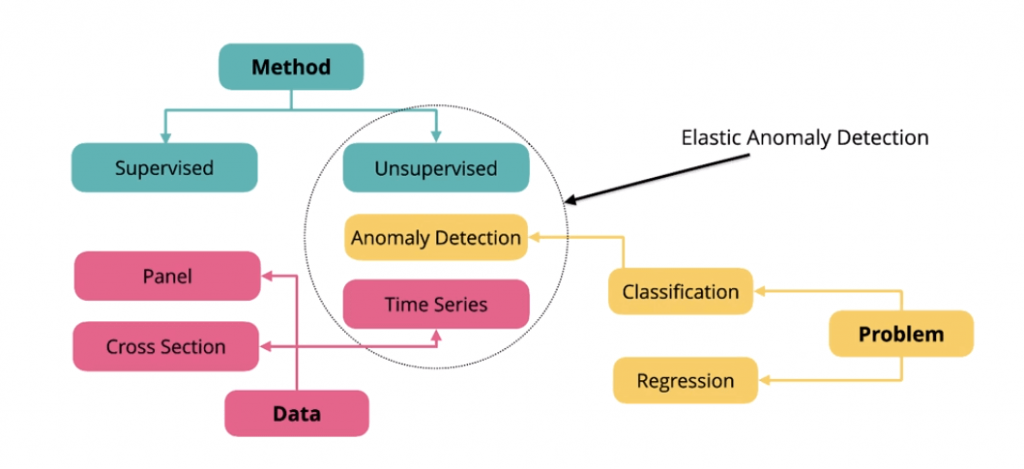
機器學習解決問題主要分兩種
機器學習使用的方法:
資料:
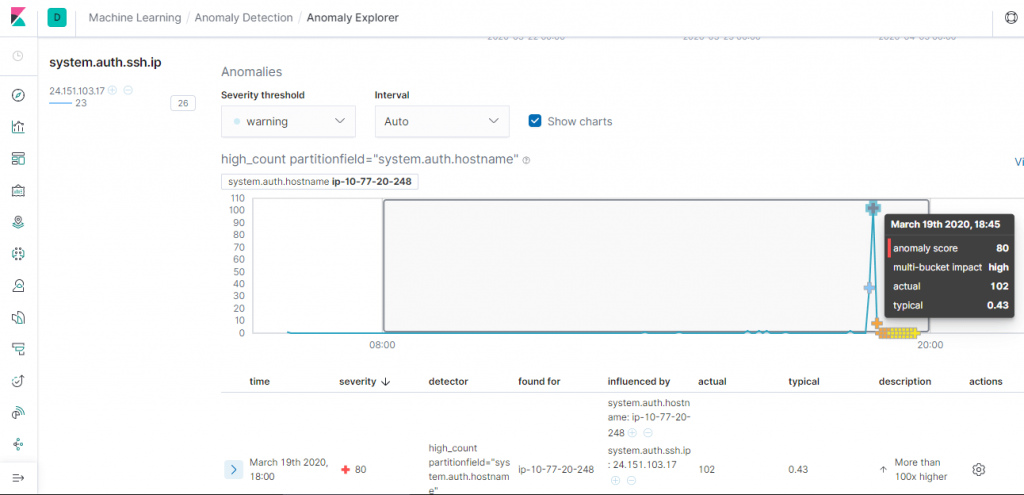
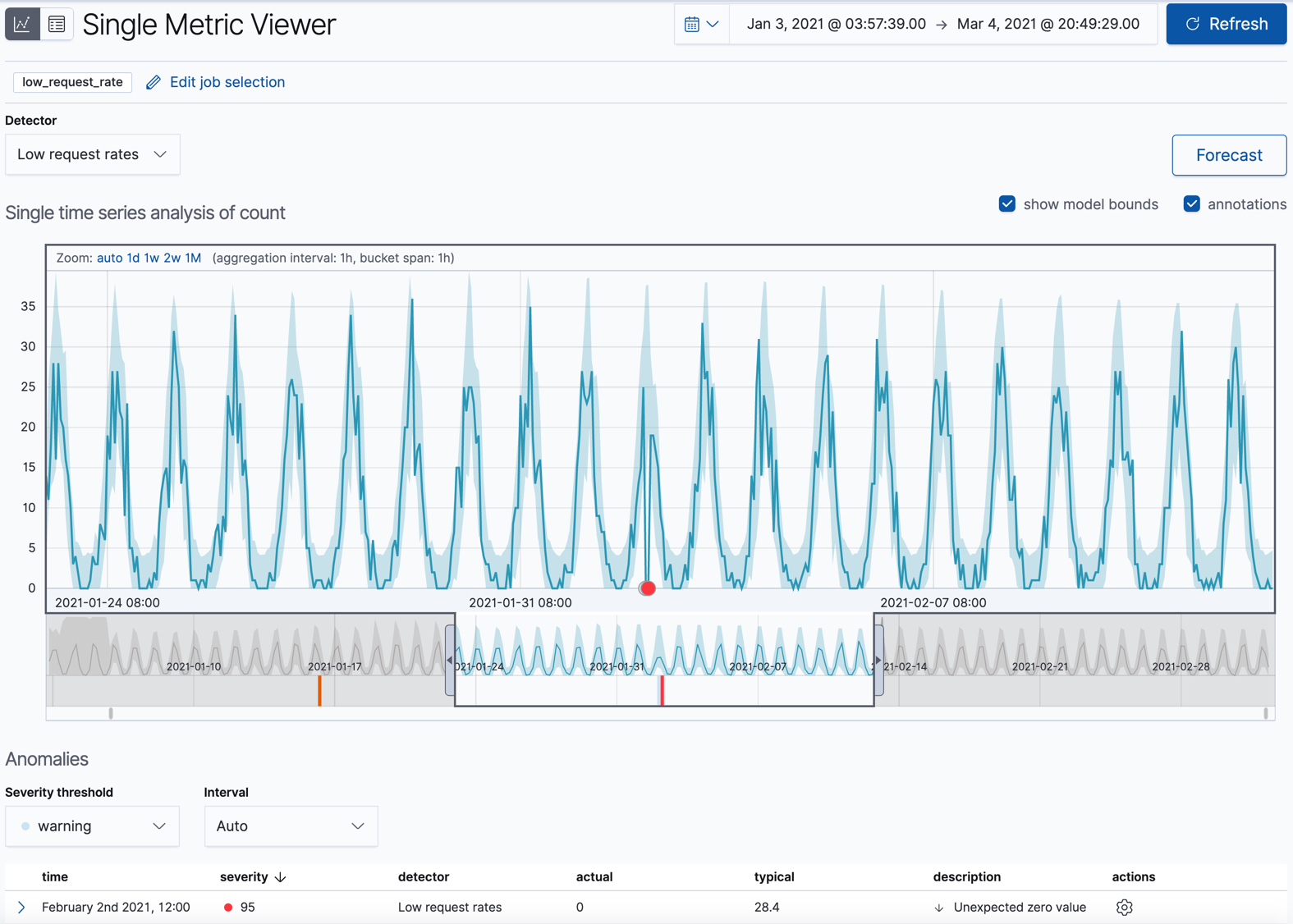
Elastic Machine Learning 中的資料異常偵測是透過非監督學習來分類時間序列的資料,可以回答像是下面的問題
Elastic Machine Learning 異常偵測
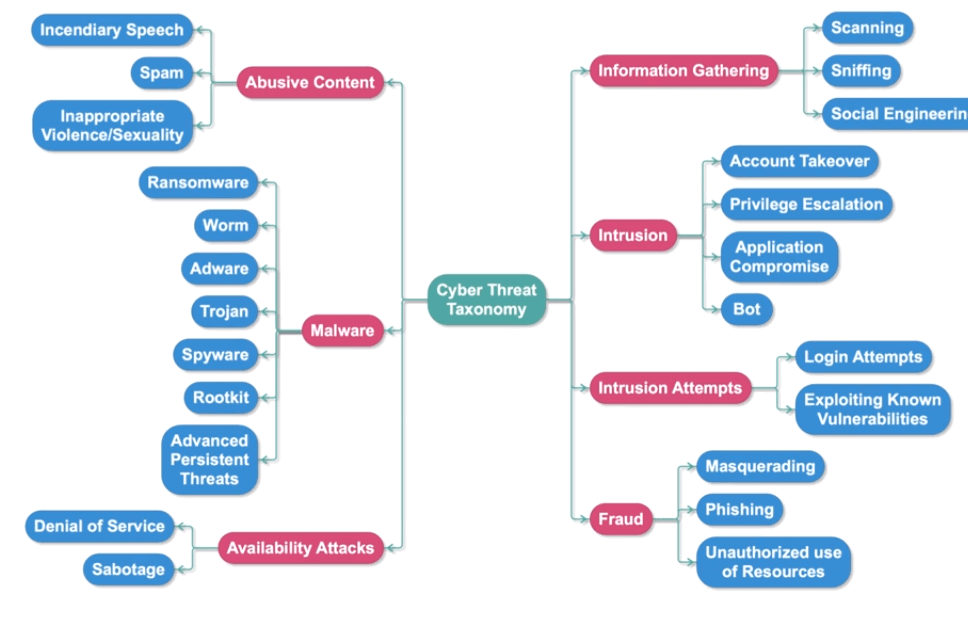
現在的系統、網路架構越來越複雜,攻擊行為也越來越多樣,難以透過設定規則、資料標記來逐一處理,所以透過收集相關紀錄後分析也許是一個比較好的解決方式,網路安全主要蒐集以下資訊
SSH logs 可以透過 Filebeat 紀錄
DNS Traffic
Elastic Machine Learning 透過非監督學習來分類時間序列的資料後,其實可以大致分出項基本的決策樹
Elastic Machine Learning 異常行為決策樹
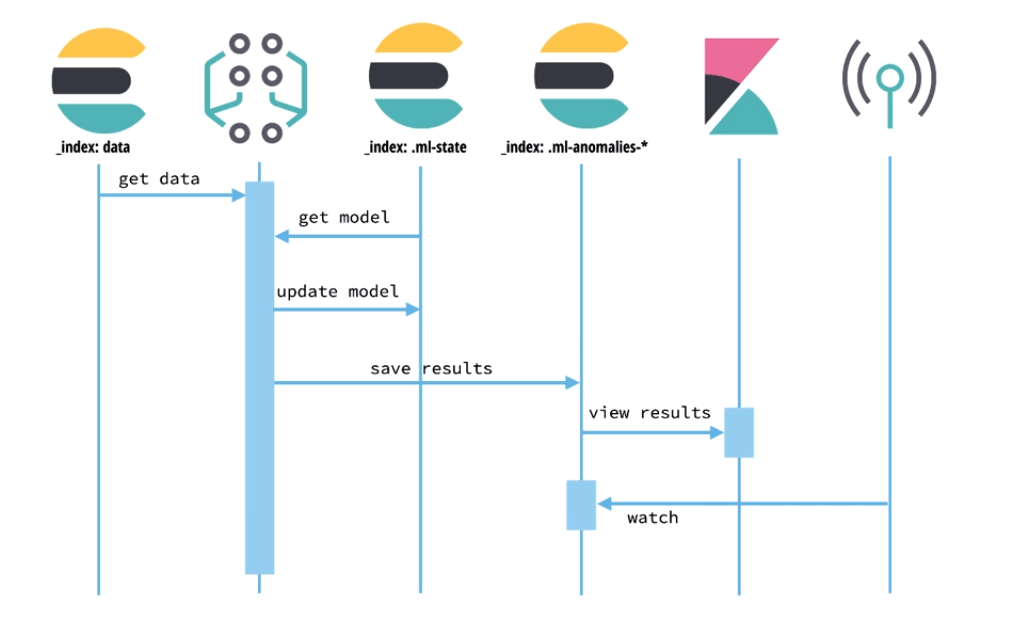
偵測異常的行為流程大致如下
異常行為偵測流程
使用上,需要先準備資料,資料部分則可以分析 Elasticsearch 中的或是額外透過 API 餵進來。
有資料後需要建立任務,任務可以透過 API 或是 Kibana UI 建立,一個機器學習任務包含配置資訊及所需的 Metadata,配置流程大致如下
Bucket 中的最大值
透過機率預測數據應該會出現在哪裏

 iThome鐵人賽
iThome鐵人賽