小弟我在去年有分享了
Distributed Tracing 分布式鏈路追蹤簡介
主要講到Distributed Tracing出現的緣由,
跟Distributed System Observability(可觀測性)的三大基石
當業務系統簡單可能就單純對MVC+DB時, 或者是初期流量或數據吞吐量都很少時, 大概都是以單體式架構的形式,
快速開發完成後上線.
在單體式架構上, 查找Log我們通常是直接Login server, 用head、tail、less等命令查看, 也能搭配其幾天介紹的grep、awk、sed 來對Log這類的文字進行處理跟分析.
但是在Distributed System, 面對佈署在數十數百台機器上,
往往為了快速查找問題, 還是需要一個Log收集、處理、存放、查詢的系統.
從之前到現在, 主流的還是ELK, 其中的角色滿足上面的處理流程.
Logstah負責收集跟處理,
ElaticSearch負責存放JSON跟Index,
Kibana負責查詢跟數據展示.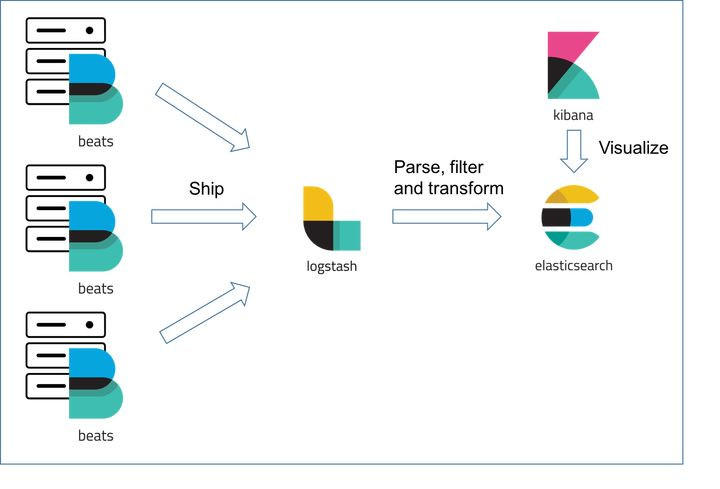
但Elatic並不滿足於Log領域,
而後又出現有了Beats家族中的MetricsBeat來負責監控數據的收集.
Elasstic APM負責Distributed Tracing鏈路追蹤的數據收集.
所以Elastic系統已經是一套整合Distributed System Observability三大基石的服務了.
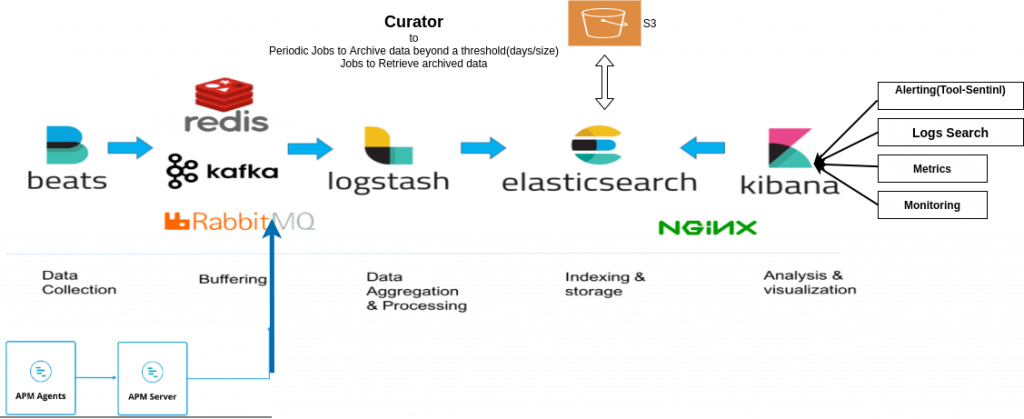
但ElaticSearch的查詢與處理, 非常依賴Index, 且ES使用倒序索引來支持全文檢索,
這特性有時在監控體系下顯得有點殺雞用牛刀了
後來Docker與Kubernetes出現後, Distributed System的設計幾乎是常態了.
Kubernetes主要使用另一組服務Fluent-bit來替代Logstash的腳色, 來收集Log.
且ELK的一些功能要收費之外, 吃的資源也相對較重, 在任何資源都需要持續收費的雲端服務上,
就會想能省則省.
剛好CNCF的Observability and Analysis的列表中
Grafana家族在Monitor有Grafana, 在Logging有Loki, 在Tracing有Tempo
跟Prometheus來整合, 達成Observability三大基石.
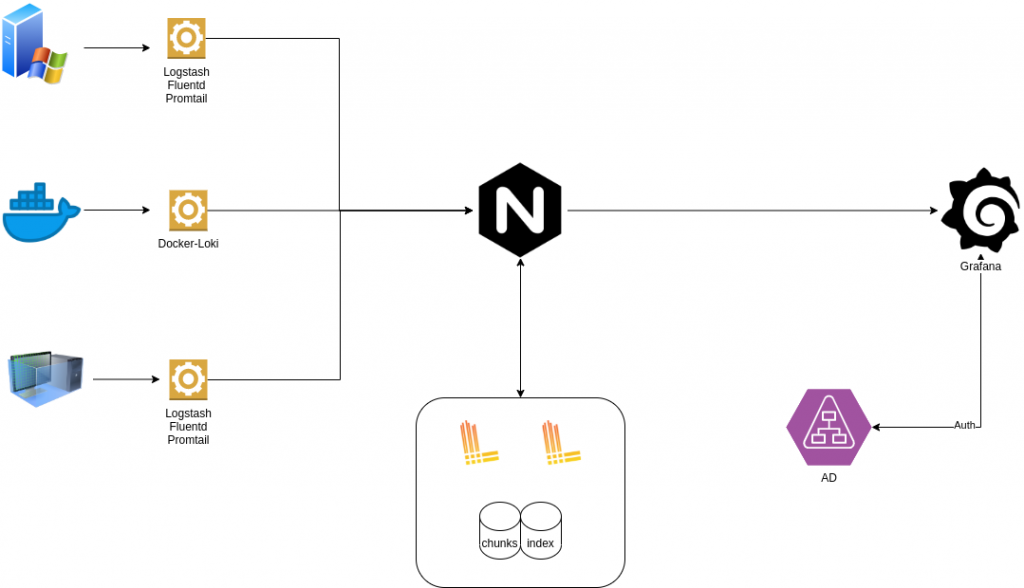
其實2組架構差異不大, 最大差別在Loki, 它並非使用Index與全文檢索的機制在提供查詢.
而是採用原始的chunk, 只對時間和特定的Label標籤做Index.
這聽起來跟Prometheus很像?
沒錯, 就是基於Prometheus的概念出來的.
只是Prometheus強調在Metrics
而Loki則是強調在Logging.
明天來介紹一下Structured Log
後日繼續從Metrics與Tracing來介紹.
----參考來源
The Three Pillars of Observability

