
不~~ 怎麼剛下水就迷航了?
圖片來源:Docker (@Docker) / Twitter
這篇是 Trobleshooting 用來搜集 安裝和建立 cluster 出現的問題
(關於 CNI 的問題會寫在後幾天的 CNI 篇章)
在 /etc/docker/daemon.json 設定 Docker,重新啟動 Docker sudo systemctl restart docker 出現錯誤
Job for docker.service failed because the control process exited with error code.
See "systemctl status docker.service" and "journalctl -xe" for details.
照著建議方法...
systemctl status docker.service
output... 看不出什麼問題
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Mon 2022-09-19 07:33:12 UTC; 1min 48s ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Process: 1114396 ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock (code=exited, status=1/FAILURE)
Main PID: 1114396 (code=exited, status=1/FAILURE)
Sep 19 07:33:12 whale3 systemd[1]: docker.service: Scheduled restart job, restart counter is at 3.
Sep 19 07:33:12 whale3 systemd[1]: Stopped Docker Application Container Engine.
Sep 19 07:33:12 whale3 systemd[1]: docker.service: Start request repeated too quickly.
Sep 19 07:33:12 whale3 systemd[1]: docker.service: Failed with result 'exit-code'.
Sep 19 07:33:12 whale3 systemd[1]: Failed to start Docker Application Container Engine.
journalctl -xe _SYSTEMD_UNIT=docker.service | tail
output...
Sep 19 07:33:05 whale3 dockerd[1114372]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character 'e' looking for beginning of object key string
Sep 19 07:33:07 whale3 dockerd[1114390]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character 'e' looking for beginning of object key string
Sep 19 07:33:09 whale3 dockerd[1114396]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character 'e' looking for beginning of object key string
/etc/docker/daemon.json JSON 格式錯誤,如圖 key 少了一個 "
sudo vim /etc/docker/daemon.json
我的 terminal 有直接把錯誤的地方標記成紅色
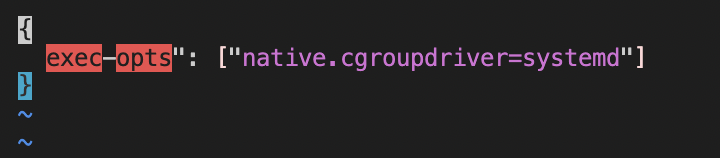
確認 /etc/docker/daemon.json 格式
sudo bash -c "cat > /etc/docker/daemon.json <<EOF
{
\"exec-opts\": [\"native.cgroupdriver=systemd\"]
}
EOF
"
sudo systemctl restart docker
確認狀態
sudo systemctl status docker
output... 成功!
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-09-19 07:45:22 UTC; 6s ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 1115054 (dockerd)
Tasks: 21
Memory: 35.0M
CGroup: /system.slice/docker.service
└─1115054 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
Sep 19 07:45:21 node3 dockerd[1115054]: time="2022-09-19T07:45:21.198150213Z" level=info msg="Removing stale sandbox b250b20c4ec774a2eb86ed814d8f97b7>
Sep 19 07:45:21 node3 dockerd[1115054]: time="2022-09-19T07:45:21.297211538Z" level=warning msg="Error (Unable to complete atomic operation, key modi>
Sep 19 07:45:21 node3 dockerd[1115054]: time="2022-09-19T07:45:21.534319590Z" level=info msg="Removing stale sandbox be2b6adc18e566d885707ac54c8528ad>
Sep 19 07:45:21 node3 dockerd[1115054]: time="2022-09-19T07:45:21.615713332Z" level=warning msg="Error (Unable to complete atomic operation, key modi>
Sep 19 07:45:21 node3 dockerd[1115054]: time="2022-09-19T07:45:21.944897336Z" level=info msg="Default bridge (docker0) is assigned with an IP address>
Sep 19 07:45:22 node3 dockerd[1115054]: time="2022-09-19T07:45:22.168399348Z" level=info msg="Loading containers: done."
Sep 19 07:45:22 node3 dockerd[1115054]: time="2022-09-19T07:45:22.231718203Z" level=info msg="Docker daemon" commit=e42327a graphdriver(s)=overlay2 v>
Sep 19 07:45:22 node3 dockerd[1115054]: time="2022-09-19T07:45:22.231848404Z" level=info msg="Daemon has completed initialization"
Sep 19 07:45:22 node3 systemd[1]: Started Docker Application Container Engine.
Sep 19 07:45:22 node3 dockerd[1115054]: time="2022-09-19T07:45:22.319620012Z" level=info msg="API listen on /run/docker.sock"
在 /etc/docker/daemon.json 設定 Docker,重新啟動 Docker,確認 docker info 正常,但使用 kubeadm init/join 後卻還原回初始設定
當初在安裝 Ubuntu 時使用內建的 snap 套件工具安裝 Docker,詳細怎麼複寫得沒辦法追蹤,我的情況是 Docker 用 snap 安裝、Kubernetes 手動安裝出現的
什麼是用 snap 安裝的 Docker?
在灌 Ubuntu 的時候會有一步驟是 snap 安裝套件,如下圖
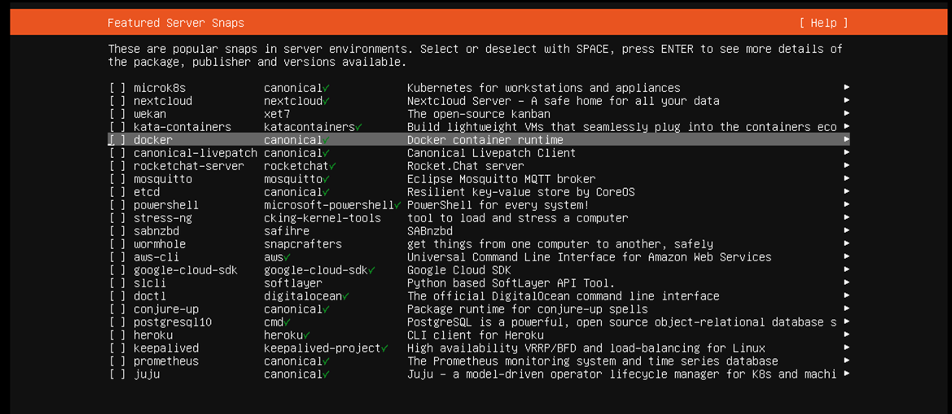
刪除 snap 版的 Docker,參考 Day 2 重新安裝 Docker
sudo snap remove docker
sudo reboot
執行 docker info 最後顯示警告
WARNING: No swap limit support
Docker 沒有設定限制 container 使用的 swap
修改 Grub 設定
sudo vim /etc/default/grub
修改參數
GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1"
重啟 grub
sudo update-grub
有可能需要重啟機器
sudo reboot
使用 kubeadm init 後出現錯誤,顯示 ERROR NumCPU
[init] Using Kubernetes version: v1.25.1
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
time="2022-09-16T18:41:14Z" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
每個 node 上的 CPU 至少需要 2 core
the number of available CPUs 1 is less than the required 2
若是使用 vm 請調整 vm 的 CPU
環境使用 Docker + Kubernetes,執行 kubeadm init 發生錯誤 ERROR CRI
[init] Using Kubernetes version: v1.25.1
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: E0916 18:44:59.852087 1667 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
time="2022-09-16T18:44:59Z" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
目前新版 Kubernetes 預設使用的 cri 只支援 containerd, cri-o,使用 Docker 需要額外安裝 cri-dockerd
Container Runtimes | Kubernetes
自行安裝 cri-dockerd,細節可以參考 Day 3
請注意:安裝檔跟 OS 有關,我的 OS 為 Ubuntu 20.04.3 (Focal)
安裝 cri-dockerd
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.2.5/cri-dockerd_0.2.5.3-0.ubuntu-focal_amd64.deb
sudo dpkg -i cri-dockerd_0.2.5.3-0.ubuntu-focal_amd64.deb
重新啟動 service
sudo systemctl daemon-reload
sudo systemctl enable cri-docker.service
sudo systemctl enable --now cri-docker.socket
kubeadm init (kubeadm join) 補上 cri-socket
kubeadm init ...
--cri-socket /var/run/cri-dockerd.sock
# or
kubeadm join ...
--cri-socket /var/run/cri-dockerd.sock
執行 kubeadm init 發生錯誤
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
To see the stack trace of this error execute with --v=5 or higher
在 kubeadm init 或 kubeadm join 沒有指定使用的 crt
kubeadm init (kubeadm join) 補上 cri-socket
kubeadm init ...
--cri-socket /var/run/cri-dockerd.sock
# or
kubeadm join ...
--cri-socket /var/run/cri-dockerd.sock
若是已經在運行的 cluster 想將 cri 改成 cri-dockerd 需要改設定檔
sudo systemctl stop kubelet
/var/lib/kubelet/kubeadm-flags.env,將 --container-runtime-endpoint 改成 unix:///var/run/cri-dockerd.sock,如下
KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --pod-infra-container-image=registry.k8s.io/pause:3.8"
sudo systemctl start kubelet
kubectl get node -o custom-columns="NODENAME":".metadata.name","CRI-SOCKET":".metadata.annotations.kubeadm\.alpha\.kubernetes\.io/cri-socket"
執行 kubeadm init 發生錯誤
kubelet cgroup driver: "cgroupfs" is different from docker cgroup driver: "systemd"
Docker 和 Kubernetes 需要用同一個 cgroup
我是將 Docker cgroup 改為 systemd 細節可以參考 Day 3
sudo bash -c "cat > /etc/docker/daemon.json <<EOF
{
\"exec-opts\": ["native.cgroupdriver=systemd"]
}
EOF
"
sudo systemctl restart docker
建立 cluster 後執行 kubectl 指令顯示憑證錯誤,x509: certificate signed by unknown authority... (verify candidate authority certificate "kubernetes")
kubectl get nodes
output...
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
使用者少做了 non-root user 的步驟設定 config
將 config 重新複製一份到自己的 home 目錄
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
建立 Pod 失敗
透過 describe Por 查看顯示
Warning FailedScheduling 4m34s default-scheduler 0/1 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
scheduler 沒辦法將 Pod 部署在 control plane 上
一般不會將 Pod 部署在 control plane 上,在 control plane 上的 node 會有 taint kubectl taint nodes whale1 node-role.kubernetes.io/control-plane:NoSchedule
執行指令移除 taint
kubectl taint nodes whale1 node-role.kubernetes.io/control-plane-
希望這篇能少一點用到~祝大家安裝順利、完全沒有 bug 出現~ 

