今天稍早的時候與同事聊天時提及到了 mdf、ndf 以及 ldf 之間的關係
讓我想起之前遇到 ldf 檔案大小爆炸級別的成長時
深感對這方面的知識量不足
因此特地借閱了 Pro SQL Server Internals 來進行閱讀
想了想後 乾脆把這些筆記貼出來
也方便我未來時方便進行查閱
以下正文內容皆是我閱讀時所記錄下來的
如果有任何錯誤也麻煩在留言區告訴我一聲
我會立即進行修改的
以下節錄至 Pro SQL Server Internals Chapter 1
每個資料庫中都含有一個或多個 Transaction Log File 以及 一個或多個 Data Files
而 Transaction Log File 主要的功用便是記錄下所有Session下所有資料修改的交易紀錄
以便在遇到問題時進行 Transaction Rollback 或 Redo
每個資料庫只會有一個 Primary Data File 預設副檔名為 .mdf
而資料庫也可以擁有 Secondary Data File 預設副檔名為 .ndf
所有資料庫檔案都將被 group 到 Filegroup 中以便資料庫管理
根據經驗法則(Rule of thumb)習慣上設定4 Data File 與 16 logical CPU 運作, 而在此之後則保持檔案數量與邏輯CPU的比率為1:8
在 File 成長的部分 MSSQL 分成 AUTOGROW_SINGLE_FILE 及 AUTOGROW_ALL_FILES
AUTOGROW_SINGLE_FILE 將只針對 Filegroup 底下的單獨 File 進行增長
AUTOGROW_ALL_FILES 則針對 Filegroup 底下的所有 File 進行增長
SQL Server 預設會對Transaction Log File 進行校正歸零的行為
而透過 Instant File Initialization 的啟用或關閉則可加速資料庫的創建或修復
SQL Server 主要有三種方式去進行資料存取
SQL Server 提供了多元的資料型態
而這些資料型態分為
1. 固定長度
2. 可變長度
在固定長度下,儲存空間為固定大小就算裡頭的值為 NULL 也是同樣 (int: 4 Bytes, nchar(10): 20 Bytes)
而可變長度下在通常狀況下 則為原先大小加上 2 額外的 Bytes
例如 nvarchar(4000) 去存放一個 5 字元的資料 則會使用 12 Bytes 去儲存
而通常情況下則使用 2 Bytes 去存放 NULL
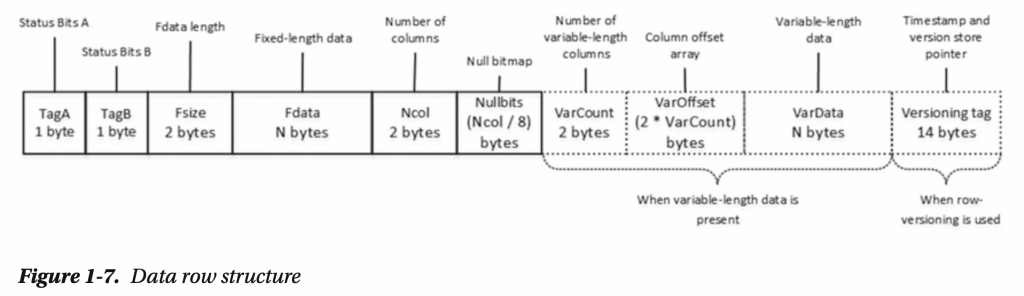
上面這邊為 SQL Server Data Row 的架構圖
透過 DBCC IND 可取得 Page 分配空間的相關詳細資訊
在固定長度Column的Table上 會有最大限制Bytes (8,060)
而在動態長度Column的Table上則會透過 Row-overflow data 的方式去存取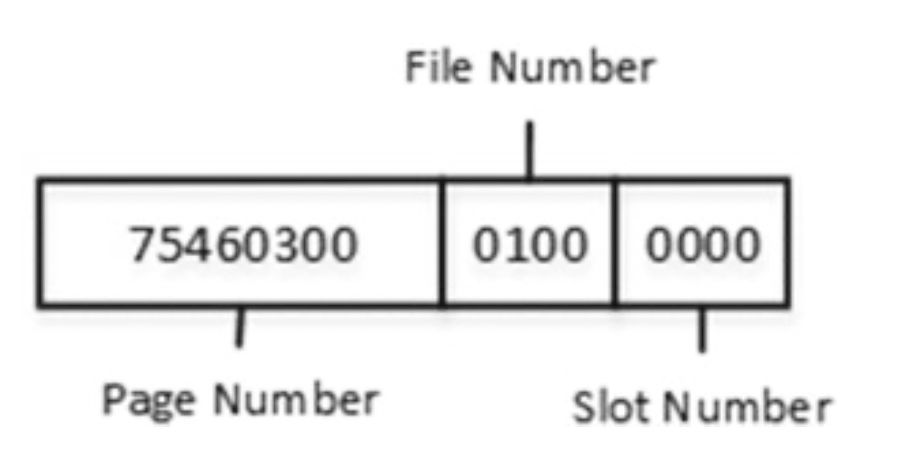
在超過的資料中會透過圖中的方式去紀錄
並且對應位置的Page 從一開始就會是資料內容
在 Text 、 nText 或 image這些資料型態中,SQL Server 會透過特殊的Page (LOB Data Pages) 去進行存放
■ Note
You can control this behavior to a degree by using the “text in row” table option.
For example,
exec sp_table_option dbo.MyTable, 'text in row', 200
forces SQL Server to store LOB data less than or equal to 200 bytes in-row.
LOB data greater than 200 bytes would be stored in LOB pages.
如果有需要透過in-row page 的方式去存放text 的資料的話
可透過上述原文提及到的方式限制在多少長度以下透過 in-row 存放,超過則透過 LOB Data Page 存放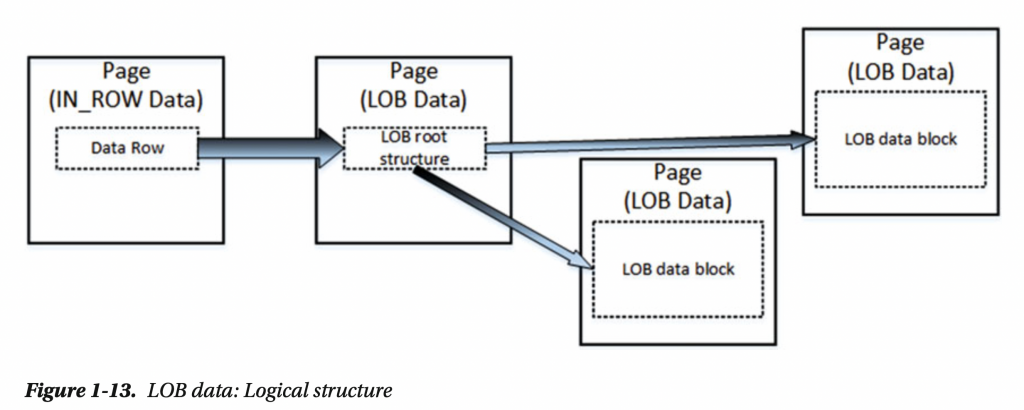
在撈取資料時,要注意不要透過 * 來進行撈取
會造成效率上問題 尤其資料是在具有 LOB 或 Row-overflow 的 Page時
每8個Page組成一個 extents
而Extents 主要分成兩種
mixed extents
uniform extents
在物件新創立時會將前 8 Page建立成混合區
而後接續的Page則會透過統一區儲存
SQL Server主要使用 Allocation Map 來進行儲存
而 Allocation Map 主要分為
在 SQL Server 2016 則提供 MIXED_PAGE_ALLOCATION 選項
通常 tempdb 會disable 而其餘的 user database 預設會是 enabled
第一個 GAM 會出現在 data file 的第三頁,第一個 SGAM 則會出現在 data file 的第四頁
接下來兩者皆會每隔511,230 pages 出現一次
在追蹤不同類型(In-Row、Row Overflow、LOB)的 page 時,會透過 index allocation map (IAM) 來進行
每個 Table 或 Index 都擁有自己的 IAM
而這些 IAM page 會組成一個 linked list 而被稱為 IAM chains
■ Tip
You can reduce the size of the data row by creating tables in a manner in which
variable-length columns, which usually store null values, are defined as the last
ones in the CREATE TABLE statement. This is the only case in which the order of
columns in the CREATE TABLE statement matters.
可以在創建資料表的最後加上一個可變動長度的Column用來存放NULL
這樣比起在前面創建可以更節省空間
這是唯一一個創建資料表順序上會影響的部分
■Tip.
1 Page( 8 KB ), 1 extents = 8 Page = 16 KB
extents 分成 統一區 跟 混合區
當資料要進行修改時,
SQL Server 會先從 Data File 將所需的 Page 讀進 Buffer Pool,
並且同步寫入該交易的 Log 紀錄
在這之後才會將資料進行修改
此時修改所需的還原紀錄便會被記錄在 Transaction Log 中
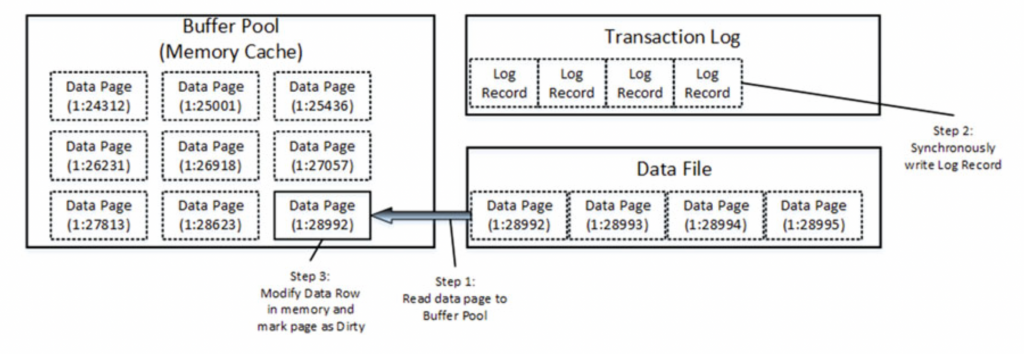
最後 SQL Server 會將 Buffer Pool 中標記為 dirty 的 Data Page 重新以非同步的方式寫回 Data File 中並且紀錄一個特殊的 Transaction Log
而這部分是透過 Check Point 這個程序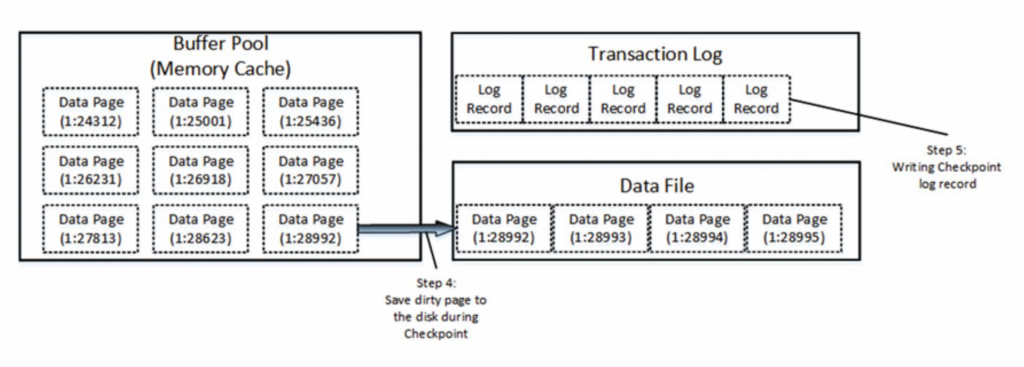
而在插入步棸中也是相同
會先將所需的 Extents 或 Page 讀取進入 Buffer Pool
而後會進行 Transaction Log 紀錄,並以非同步的方式寫入 Data File
而在刪除中,則會透過 Ghosted 的方式進行處理而非直接進行物理刪除
因此可以快速的刪除及恢復原先狀態及資料
而 SQL Server 有提供一種叫 lazy writer
這個 Writer 會將資料寫入 Data File 並從記憶體將其移除
First, when SQL Server processes DML queries (SELECT, INSERT, UPDATE, DELETE, and
MERGE), it never works with the data without first loading the data pages into the
buffer pool. Second, when you modify the data, SQL Server synchronously writes log
records to the transaction log. The modified data pages are saved to the data files
asynchronously in the background.
上述兩點重點
當一個 Query 的 IO 操作越多,
則越多的 Data Page 需要被寫入 Buffer
也因此速度就會越慢
而當 Data Row 的 Size 太大時,
則代表在搜尋時要經過多個 Pages
因此速度會比較慢
除此之外也會花費較多的 Buffer 記憶體空間去存取
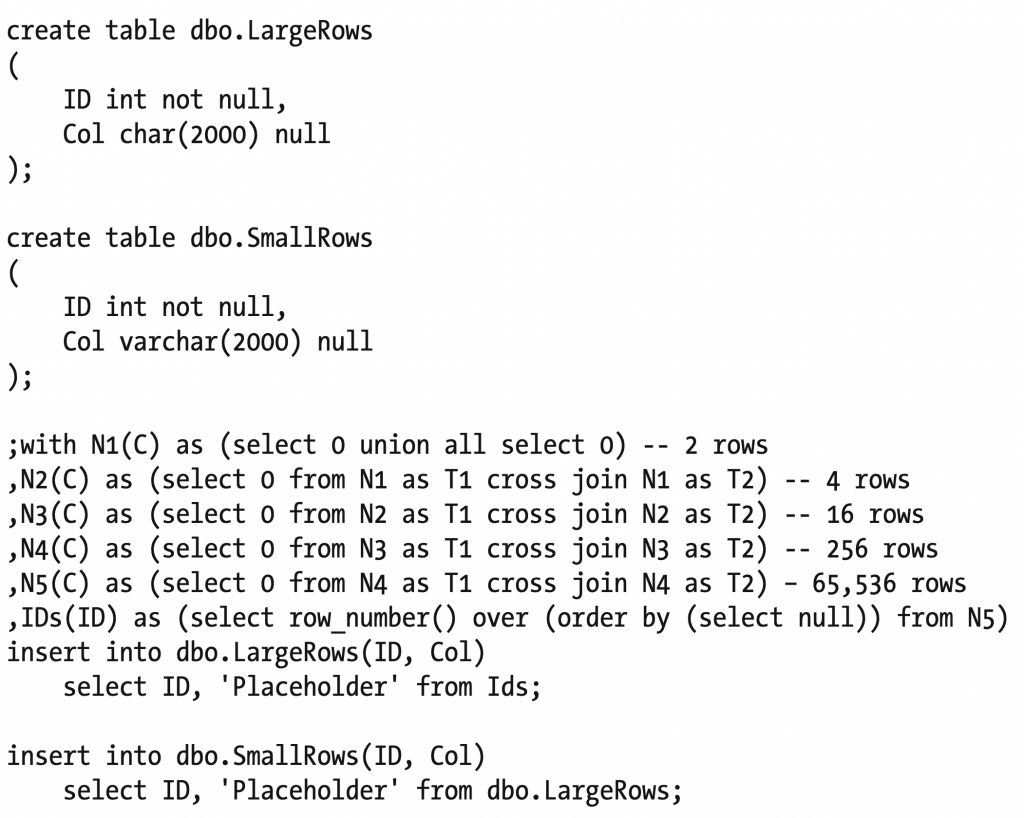
這邊舉了一個例子來讓我們知道儲存型別大小所帶來的影響
由於 LargeRows 宣告固定長度字串因此相較於 SmallRows 的動態長度字串空間花的比較多
也因此在搜尋時,LargeRows 讀寫速度遠小於 SmallRows
因此這邊作者提出一些實用建議

雖然在目前比較只少 18 bytes
但在資料筆數一增長時便會帶來明顯的差異
並且由於單筆資料 Size 增加
會使得網路頻寬、記憶體使用量、備份檔案大小
而若沒考慮到這些則會在雲服務盛行的現代為公司帶來不少的成本浪費
而在資料庫設計中
資料表若原先沒考慮到後續變更後果
則會為後續造成更大的成本
Ex . smallint to int
SQL Server 有三種 Table Alteration 情境
data file 可以透過 filegroup 去劃分
在這邊建議建立多個 data file 去儲存資訊,並且將各項需劃分的資料透過 filegroup 分割開來,來隔離保護資料
以上內容為 Pro SQL Server 閱讀後做下來的筆記
有興趣的讀者務必參閱
 OuJiaHao
OuJiaHao

 iThome鐵人賽
iThome鐵人賽