在 day-03 我們建立了一個 .env-sample 的檔案,今天我們要用 狀態機 的方式來解析這個檔案。
# .env-sample file
# This is a comment
SECRET_KEY=YOURSECRETKEYGOESHERE # comment
SECRET_HASH="something-with-a-#-hash"
PRIVATE_KEY="-----BEGIN RSA PRIVATE KEY-----
...
Kh9NV...
...
#### 5678
-----END RSA PRIVATE KEY-----"
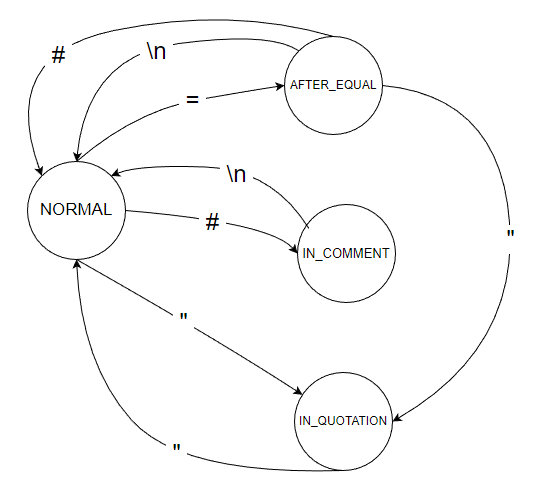
在之前的規則分析中,我們可以直觀的知道 3 個關鍵字元
= 切分 key 和 value# 設定註解" 多行處理其實還有第四個關鍵字元,換行 \n,當單行處理時,換行就是 value 的結束點。
所有狀態遇到非關鍵字元,如 a . b . @ . 空格 ...時,不改變狀態,將字元收集起來到 collected 變數中
NORMAL 狀態時遇到 = ,切換狀態為 AFTER_EQUAL,並將 collected 中的文字當作 key,然後清空 collected 變數內的文字
NORMAL 狀態時遇到 # ,切換狀態為 IN_COMMENT,如果 collected 變數有文字 ( ex: KEY#01=GG ),則抱錯 ( KEY01 中不能有 # )
NORMAL 狀態時遇到 " ,切換狀態為 IN_QUOTATION,如果 collected 變數有文字 ( ex: KEY"01=GG ),則抱錯 ( KEY01 中不能有 " )
NORMAL 狀態時遇到 \n ,不做處理,收集下個字元
IN_QUOTATION 狀態時遇到 = ,不做處理,收集下個字元
IN_QUOTATION 狀態時遇到 # ,不做處理,收集下個字元
IN_QUOTATION 狀態時遇到 " ,切換狀態為 NORMAL,並將收集的文字當作 value,然後清空 collected 變數內的文字
IN_QUOTATION 狀態時遇到 \n ,不做處理,收集下個字元
IN_COMMENT 狀態時遇到 = ,不做處理,收集下個字元
IN_COMMENT 狀態時遇到 # ,不做處理,收集下個字元
IN_COMMENT 狀態時遇到 " ,不做處理,收集下個字元
IN_COMMENT 狀態時遇到 \n ,切換狀態為 NORMAL,並將收集的文字當作 value,然後清空 collected 變數內的文字
AFTER_EQUAL 狀態時遇到 = , ( ex: KEY==GG ) 抱錯 ( 一行不能有兩個 = )
AFTER_EQUAL 狀態時遇到 # ,切換狀態為 NORMAL,並將 collected 中的文字當作 key,然後清空 collected 變數內的文字,如果 collected 變數沒有文字 ( ex: KEY01=#GG ),則抱錯 ( KEY01 沒有對應的 value )
AFTER_EQUAL 狀態時遇到 " ,切換狀態為 IN_QUOTATION,如果 collected 變數有文字 ( ex: KEY01=GG"GG ),則抱錯 ( = 後面的 " 之間不能有文字 )
AFTER_EQUAL 狀態時遇到 \n ,切換狀態為 NORMAL,並將收集的文字當作 value,然後清空 collected 變數內的文字
當你念完上面的 20 條咒語,你才能發動一個小型魔法叫做
Tokenizer
明天我們就根據今天的狀態圖來實作逐字分析的程式 ( •̀ ω •́ )✧
今天有邦友問我,整個系列,只有看到文字分析,搞不太懂這有什麼用處 ?
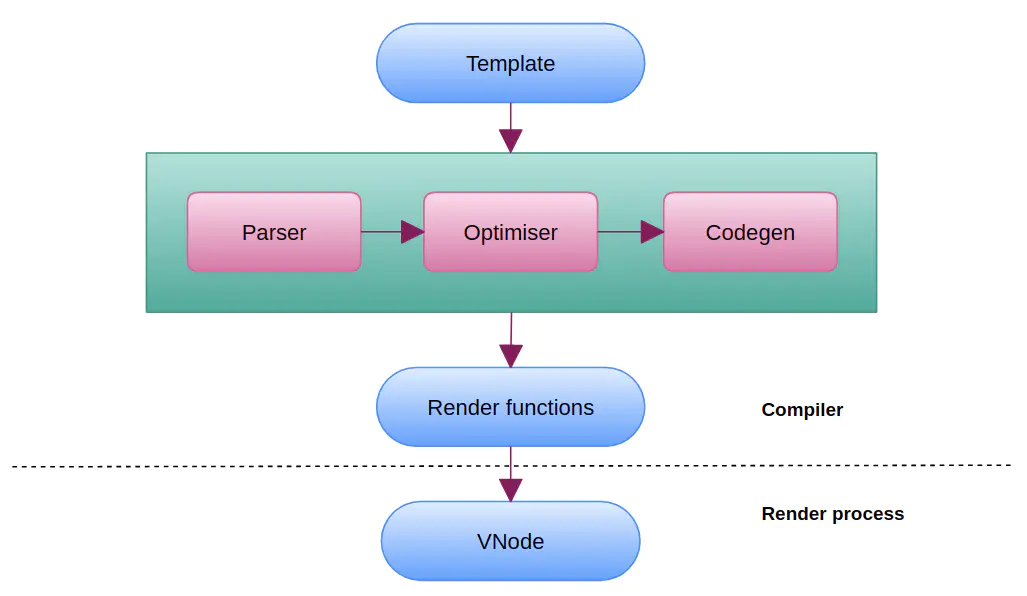
這邊我放一張 Vue 是如何將 中的 HTML 字串轉換成 HTML DOM 的圖,也許可以讓邦友更了解這個系列的用途。
也要跟邦友們說明,這個系列就是圍繞在 文字解析 上面,所以邦友們可能會看到 30 天的文字解析。
當然,我們的目標做出 Vue Parser,所以後面的文章當然會說明 HTML . CSS . JS 該如何做 簡單的文字解析。
附註:30 天不太可能說明完整的解析,特別是 JS 的解析,因為 JS 的規則會不斷地添加,所以我們只是說個概念,讓邦友們知道如何起頭。
另外在這也推薦一下 Stanford 的開放課程 - Compilers,你會了解更多文字解析在 計算機領域 中的更多應用。


 iThome鐵人賽
iThome鐵人賽