接下來我們根據之前的步驟來分析 HTML ,想辦法生成它的 Tokenizer 跟 Parser 吧 ~
狀態圖
與 .env-sample 分析時相同,我們先來看看 HTML 的輸入文字 & 預期的輸出 Tokens . AST 吧 ~
<div>
<p>Vue</p>
<p>Template</p>
</div>
const tokens = [
{ "type": "tagStart", "name": "div" },
{ "type": "tagStart", "name": "p" },
{ "type": "text", "content": "Vue" },
{ "type": "tagEnd", "name": "p" },
{ "type": "tagStart", "name": "p" },
{ "type": "text", "content": "Template" },
{ "type": "tagEnd", "name": "p" },
{ "type": "tagEnd", "name": "div" },
]
const AST = {
type: 'root',
children: [
{
"type": "div",
"children": [
{
"type": "p",
"children": [
{
"type": "text",
"content": "Vue"
}
]
},
{
"type": "p",
"children": [
{
"type": "text",
"content": "Template"
}
]
}
]
}
]
}
也就是再次分析 HTML 並且製造出 Tokenizer 跟 Parser
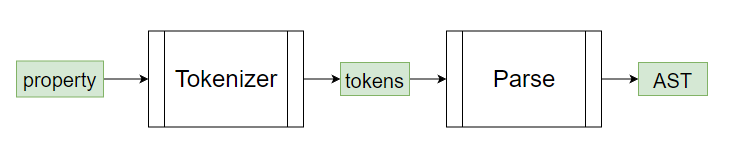
明天我們來分析 HTML 的狀態圖,之後利於我們建立 Tokenizer q(≧▽≦q)

 iThome鐵人賽
iThome鐵人賽