以Yahoo電影網站為目標網址,用Beautiful Soup物件擷取出電影的中文名稱、英文名稱、上映日期、期待度與電影資訊連結並列印出來。
from bs4 import BeautifulSoup
import requests
def parseHtml(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
#使用css選擇器獲得class="release_list"的節點下面的所有li節點
for index,li in enumerate(soup.select(".release_list li")):
print('中文名:' + li.find(class_="release_movie_name").a.text.strip())
print('英文名:' + li.find(class_="en").a.text.strip())
date = li.find(class_="release_movie_time").text.strip()
date2 = date.replace("上映日期:", "").strip()
print('上映日期:' +date2)
print('期待度:' + li.find(class_="leveltext").span.text)
print('電影資訊連結:'+li.a['href'])
print('————————————————————————————————————————————')
def main():
page = [1, 2, 3, 4, 5]
for p in page:
url = "https://movies.yahoo.com.tw/movie_intheaters.html?page="+str(p)
print("————————————————————第"+str(p)+"頁————————————————————")
parseHtml(url)
if __name__ == '__main__':
main()
執行結果: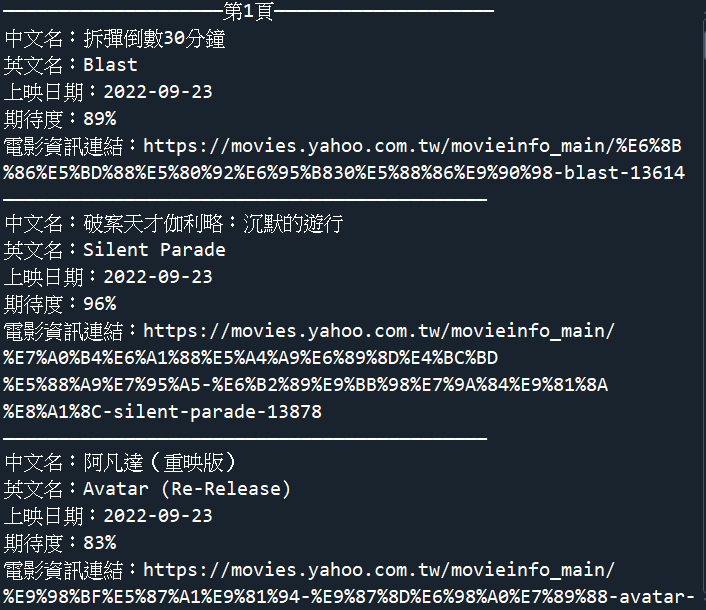


 iThome鐵人賽
iThome鐵人賽