今天來試著把一位作者所有作品的連結給抓出來
首先先挑一位作者的頁面打開,並打開網路頁籤看一下我們get到了什麼東西。
可以從json檔開始找找看,有時候會找到驚喜。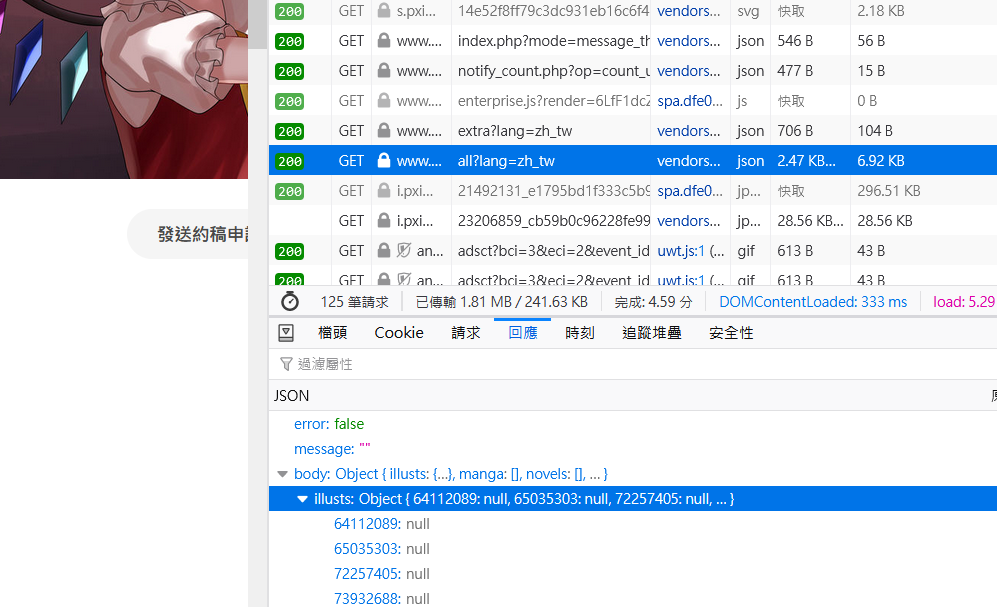
像這裡我們就找到了一個json檔有包含了作者所有的作品ID。
我們可以利用他生成所有作品的連結。
可以看到我們的請求長這樣,所以我們現在試著把Filenames接在Host後面組起來並打開來看看。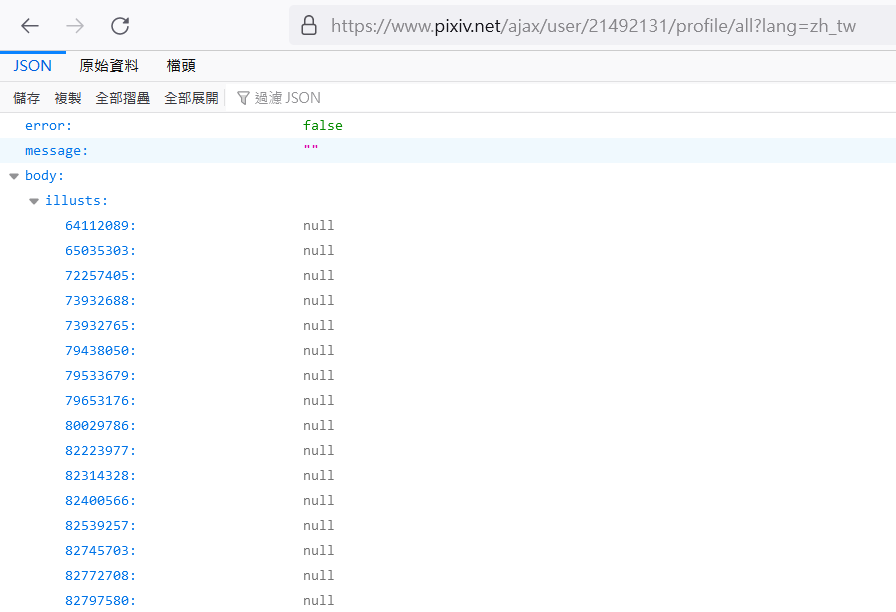
看起來沒問題,我們繼續。
這裡firefox有個小坑,因為用selenium是模擬實際使用的狀況所以打開json檔時firefox會自動幫你轉成上圖那樣易讀的模式。
但這反而會造成我們的麻煩,因為抓下來後會發現資料被分割並塞在一堆HTML裡面,所以要想辦法關掉。
解決方法是先設定並在開driver時把設定塞進去。
brower_options = webdriver.FirefoxOptions()
brower_profile = webdriver.FirefoxProfile()
brower_profile.set_preference('devtools.jsonview.enabled', False)
brower_options.profile = brower_profile
driver = webdriver.Firefox(options=brower_options)
這樣執行雖然會產生類似底下的錯誤DeprecationWarning: firefox_profile has been deprecated, please use an Options object brower_profile = webdriver.FirefoxProfile()
但因為還是能動我就先忽視了。
寫完後再get一次該網址可以發現他正常了。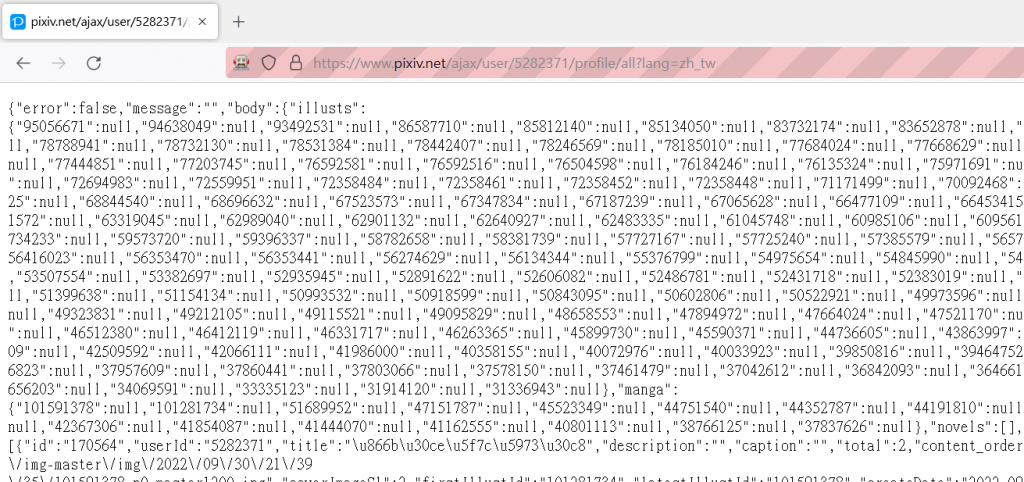
雖然還是會塞在html裡但只要用一行lxml+稍微修整就可以拿出json資料了。
tree = etree.HTML(driver.page_source)
illu_json = json.loads(str(tree.xpath('/html/body/pre/text()'))[2:-2])
執行並print出來後可以發現資料成功拿到了,如下圖。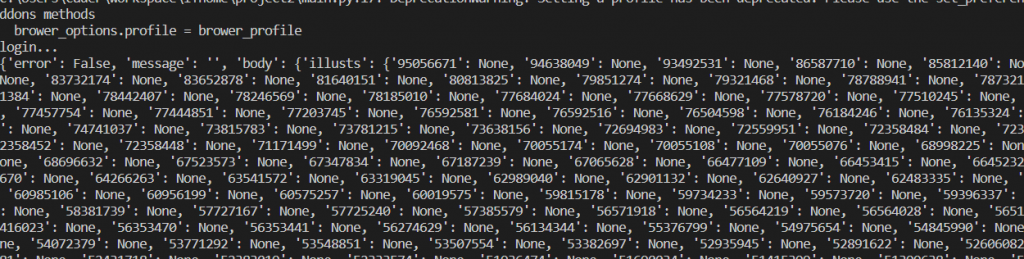
明天繼續講爬下各作品。

 iThome鐵人賽
iThome鐵人賽