參考資料
https://medium.com/marketingdatascience/%E9%80%8F%E9%81%8E%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92%E9%A0%90%E6%B8%AC%E8%82%A1%E5%B8%82%E6%BC%B2%E8%B7%8C-%E9%80%B2%E9%9A%8E%E8%B3%87%E6%96%99%E8%99%95%E7%90%86-%E9%99%84python%E7%A8%8B%E5%BC%8F%E7%A2%BC-51b78718c82e
前情提要
消息面對投資者來說可謂重中之重,任何一微小的風吹草動皆不能放過。無奈的是,大部分投資者無法花費大量時間瀏覽所有可能帶來價格影響的新聞。有鑑於此,我希望能透過機器學習以資料科學的角度掌握新聞標題對大盤的走向。以下將使用Reddit World News當日前25名熱門的新聞標題作為示範處理資料。
縮寫字詞的處理
針對原始資料某些字詞以縮寫形式呈現,如 United States 簡寫為 U.S. 之情形,我們必需將這些縮寫還原回其原本型態才能在後續建立模型階段取得更好的表現。
片語 & 連續出現時產生特殊含義之詞彙的處理
針對此類情況,這邊用 n-gram 作為解決方式。
n-gram 是一種在進行 nlp (自然語言處理)時經常使用到的處理方法。簡單來說,n-gram 是一種將句子以不同長度切分為各個字詞的方法,n 即代表每次的切分長度。例如 「我喜歡資料科學」 在 n = 1 的情形下會切分為 「我」 ,「喜」,「歡」,「你」……以一個字為單位的形式; 假設 n = 2 ,即會切分為「我喜」,「喜歡」,「歡你」,……的形式,以此類推。除此之外,一般在進行資料分析時,遇到如「我喜歡你」 此種因順序不同而具不同意義之句子時往往無法判讀其真實語意,而運用 n-gram 即可透過 「我喜」,「喜歡」 等不同欄位來釐清原句語意。往後我們遇到原始資料中有四字成語、三字聯詞或兩字片語的情形,也可以分別利用 4-gram 、3-gram、2-gram 將這些詞彙切分出來,如下圖所示。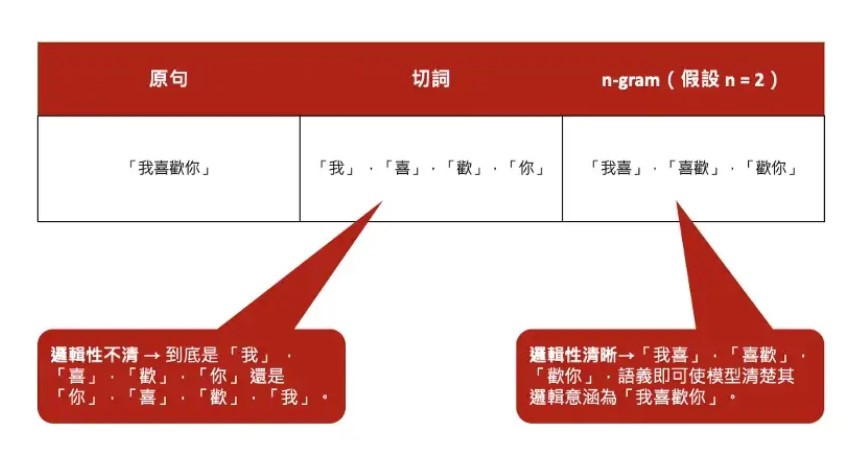
ngram比較表
TfidfVectorizer套件
上述我們已完成建立機器學習模型前所需之資料清洗。接下來,我們必須從原始資料中所切分之所有字詞挑選出較具有顯著意義的字詞,減輕一些過於氾濫或過於稀少的字詞權重,並加強具顯著意義字詞的權重以試圖增益機器學習模型的預測準確性。此處我們使用 Scikit-learn 套件底下之TfidfVectorizer 函數為我們進行字詞權重的分配。TfidfVectorizer 是一個基於 Tfidf 指標所開發出的字詞處理函數; 而 Tfidf 則是一種考量各字詞在原始資料中的密度、稀少性、頻率後將字詞給予權重評分的一個指標,具體公式如下圖。
TfidfVectorizer 能讓我們輕鬆將原始資料進行 Tfidf 指標評分。好消息是,TfidfVectorizer 除卻能夠調配 Tfidf 權重過高或過低之字詞,也支援一併進行 n-gram 處理。因此我們只要使用 TfidfVectorizer 即可將原始資料以快速地將原始資料進行 n-gram 處理並給予各字詞 Tfidf 的權重分數。
程式碼:
TfidfVectorizer(max_df,min_df,max_feature,ngram_range)
1.max_df:過濾超過比例的詞語
2.min_df:過濾低於比例的詞語
3.max_feature:限制特徵
4.ngram_range:建立詞語組合
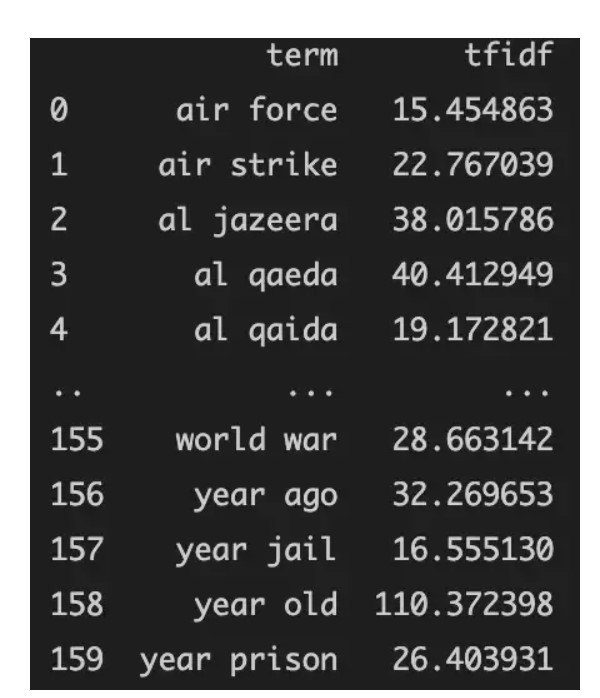
步驟完成後就可以將上圖變成下圖
 408262105
408262105
