完成網站地圖後,我們可以使用樹狀結構圖形來掩飾CSS選擇器節點的地圖,執行Sitemap title_tag → Selector graph
最初只有顯示_root節點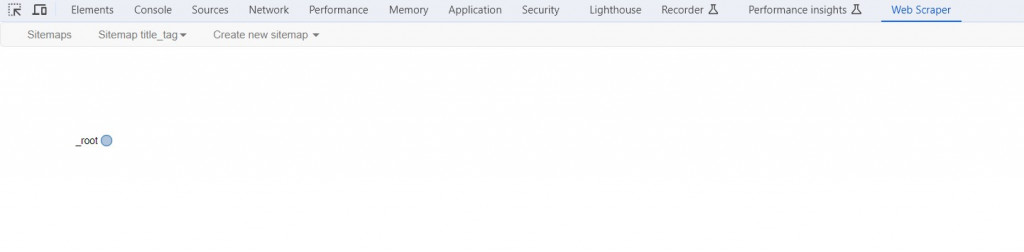
點選後就會顯示下一層的三個CSS選擇器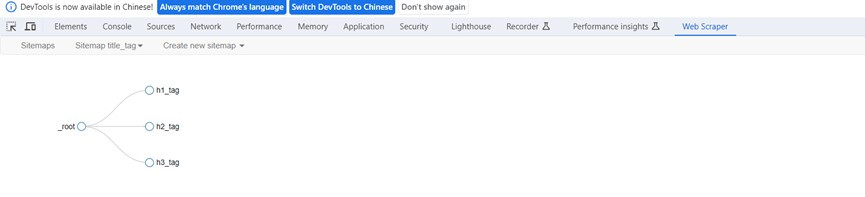
成功建立擷取資料的Web Scraper網站地圖後,就可以開始爬取資料了。
1.點選Sitemap title_tag → Scrape 擷取資料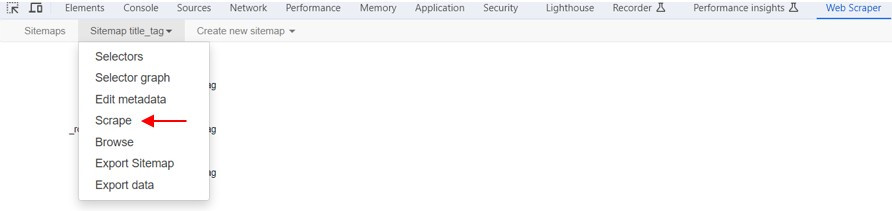
2.輸入送出HTTP請求的間隔時間和載入網頁的延遲時間,預設值是2000毫秒(2秒),點選Start scraping爬取資料。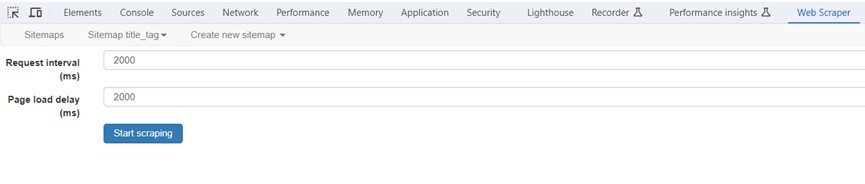
3.看到執行完成的彈出式視窗代表已經爬完資料,點選refresh重新載入資料。
這樣子就能看到<h1>、<h2>和<h3>三個標題文字標籤的內容了!
表格由左至右的欄位分別是Web Scraper擴充功能執行爬蟲的編號、起始URL網址和HTML網頁擷取的資料,而同一層CSS選擇器是屬於同一筆資料的欄位。
以上就是這一次的標題文字標籤爬取練習,今天的分享就先到這邊啦!我們明天見~
參考書籍資料:文科生也可以輕鬆學習網路爬蟲

