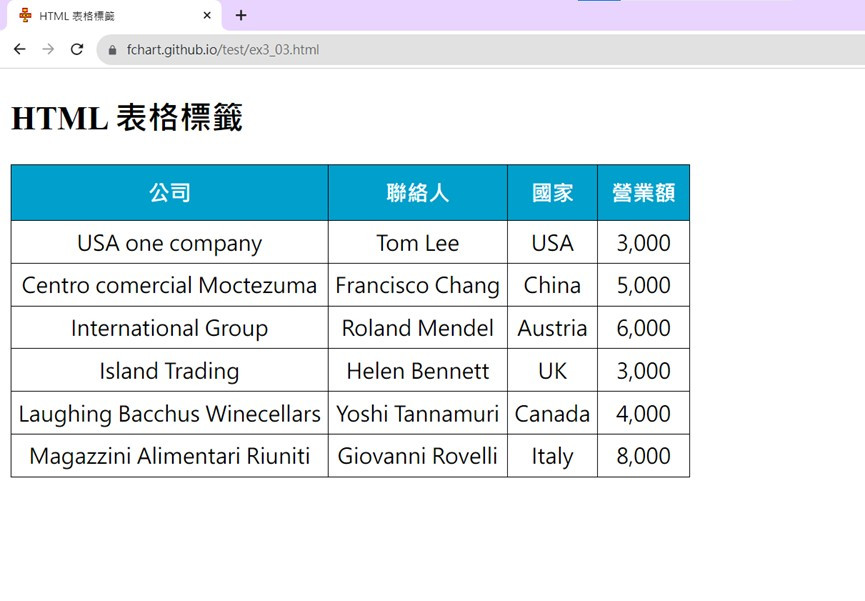
今天我們就來使用Web Scraper爬取<table>標籤吧!
本次練習網址為:https://fchart.github.io/test/ex3_03.html
按F12或是Ctrl+Shfit+I開啟開發人員工具,在開發工具中,可以看到<table>、<tr>和<td>標籤的階層結構。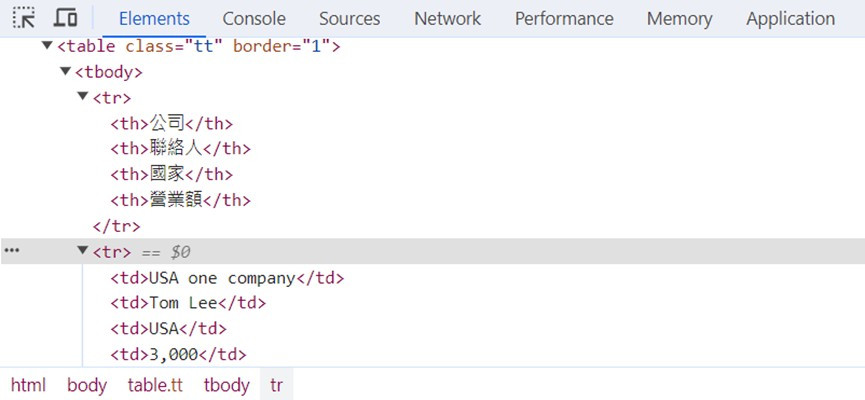
在Sitemap name輸入名稱,Strat URL欄輸入起始URL網址後按Create Sitemap新增網站地圖。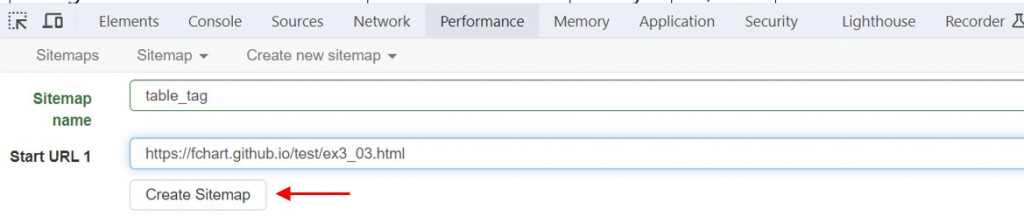
建好地圖專案後,就可以新增CSS選擇器,這次使用Table結點類型來擷取HTML表格標籤。
1.點選Add new Selector新增目前_root節點下的CSS選擇器,在Id欄位輸入名稱table_tag,Type欄選Table,在Selector欄點選Select。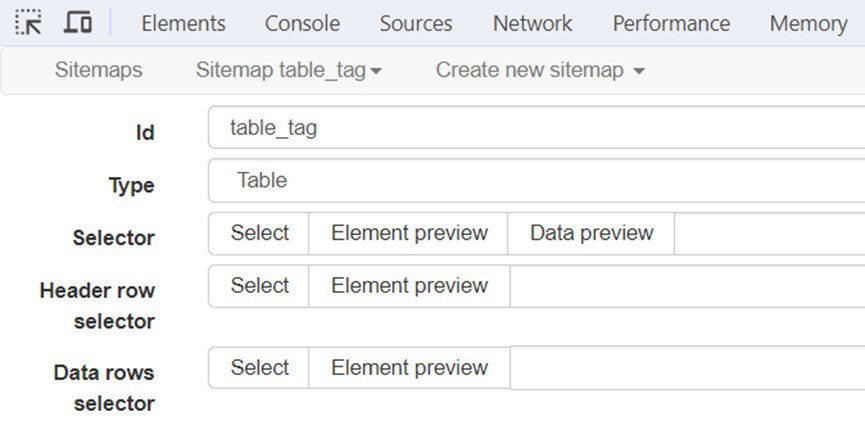
可以看到上面的Table選擇器類型有三個CSS選擇器:
<table>標籤。2.在網頁移動游標,點選HTML標格的<table>標籤,會看到CSS選擇器是table,點選Done selecting完成選擇。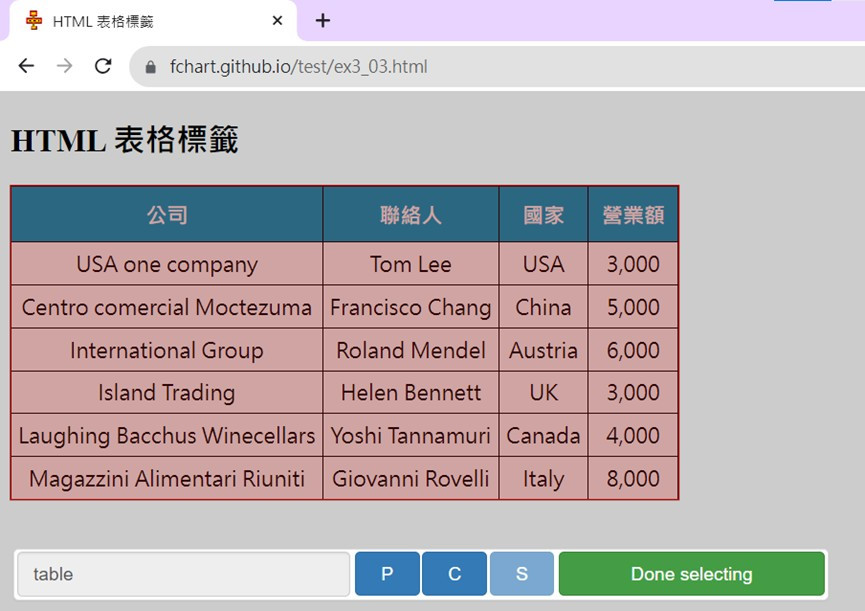
3.這時會看到自動填入標題列和資料列的CSS選擇器,Selector欄是table;Header row selector欄是tr:nth-of-type(1),即第一列;Data row selector欄是tr:nth-of-type(n+2),即第一列之後的所有列。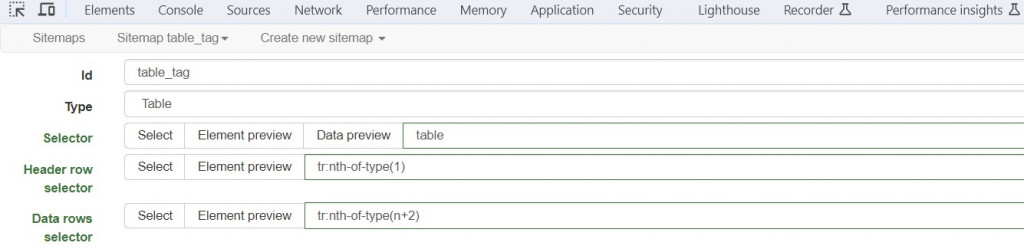
4.在下方列出的自動取得欄位清單,可在Include into result欄勾選擷取那些欄位,由於表格資料列有多列,請勾選Multiple,(沒有勾選的話,只會擷取第一列資料列);Result key名稱必須是英文字母開頭,所以將欄的中文都改成英文名稱company、contact、country和sales,點選Save selector紐。
5.執行Sitemaplist_tag → Selector graph命令,一開始只有_root節點,點擊即可顯示下一層的CSS選擇器table_tag。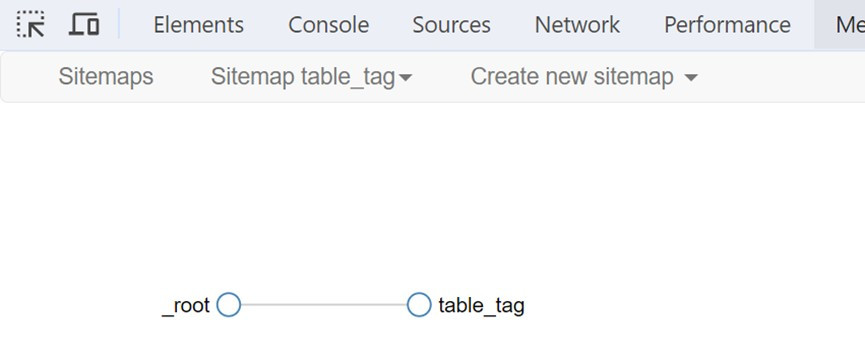
1.執行Sitemap title_tag → Scrape 命令執行網路爬蟲,輸入送出HTTP請求的間隔時間和載入網頁的延遲時間,預設值是2000毫秒(2秒),點選Start scraping爬取資料。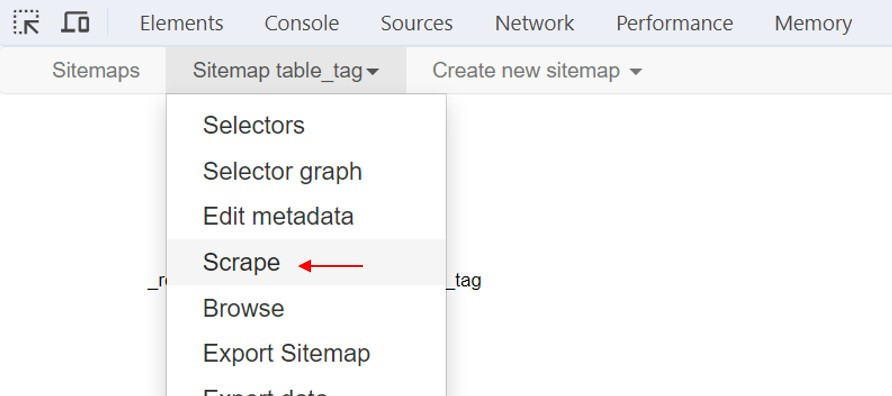
2.爬完後點選refresh重新載入資料即可看到擷取的表格資料。
接著我們一樣將爬取資料匯成CSV檔案
點選Sitemap title_tag → Export data → Download as .CSV,匯出爬取資料成為CSV檔案。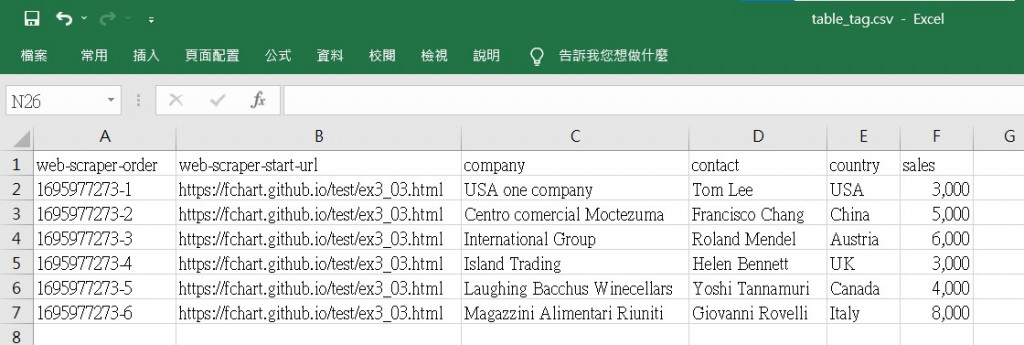
這樣子就完成啦!
今天的分享就先到這邊,我們明天見~ 
參考書籍資料:文科生也可以輕鬆學習網路爬蟲
資料爬取練習來源同書籍

