如上篇所說, 這系列會著重在 水平擴展, 就需要用到一些分散式系統的知識
由於分散式系統也是值得 6 學分的課, 這裡僅介紹基本原則, 有興趣深入請自行查閱
(題外話: 原本想附個線上課程的參考連結像是交大 OCW 之類的, 結果竟然找不到@@)
今日內容
可以由 每個節點的責任 來區別
就像前面提到的, 每個節點有自己的工作, 所以存取資料只需要和對應的節點互動即可
優點是是好維護, 流量小的時候存取速度快 (相較於分散式系統)
缺點是流量大的時候容易遇到 Bottleneck, 前面有提過就不贅述
本系列不會介紹 去中心化系統, 基本概念是 沒有主要的控制節點, 所有節點的功能是相同的
所以系統中的任何節點都能夠存取資料
優點是資料共享, 效能瓶頸取決於 "系統整體資源的上限", 且天然就有資料備份的特性
缺點是由於沒有 Single Source of Truth (SSOT, 單一事實來源), 需要透過 共識演算法 (Consensus Algorithm) 達成一致性如 Raft, PoW, PoS 等, 有興趣請自行查閱~
分散式系統 和 去中心化系統 乍看之下有點像, 但 分散式系統的節點仍然有主次之分
好處是提升了系統的 Availability (可用性), Partition Tolerance (分區容錯) 和 資料的 Durability (持久性)
缺點是相較於中心化系統更高的 Latency (延遲), 較低的 Maintainability (可維護性), Consistency (一致性)
CAP (Consistency, Availability, Partition Tolerance) Theorem 是由 Eric Brewer 提出的理論, 作者表示 "任何分散式儲存的資料最多只能保證 CAP 中的兩種特性"
... any distributed data store can provide only two of the following three guarantees.
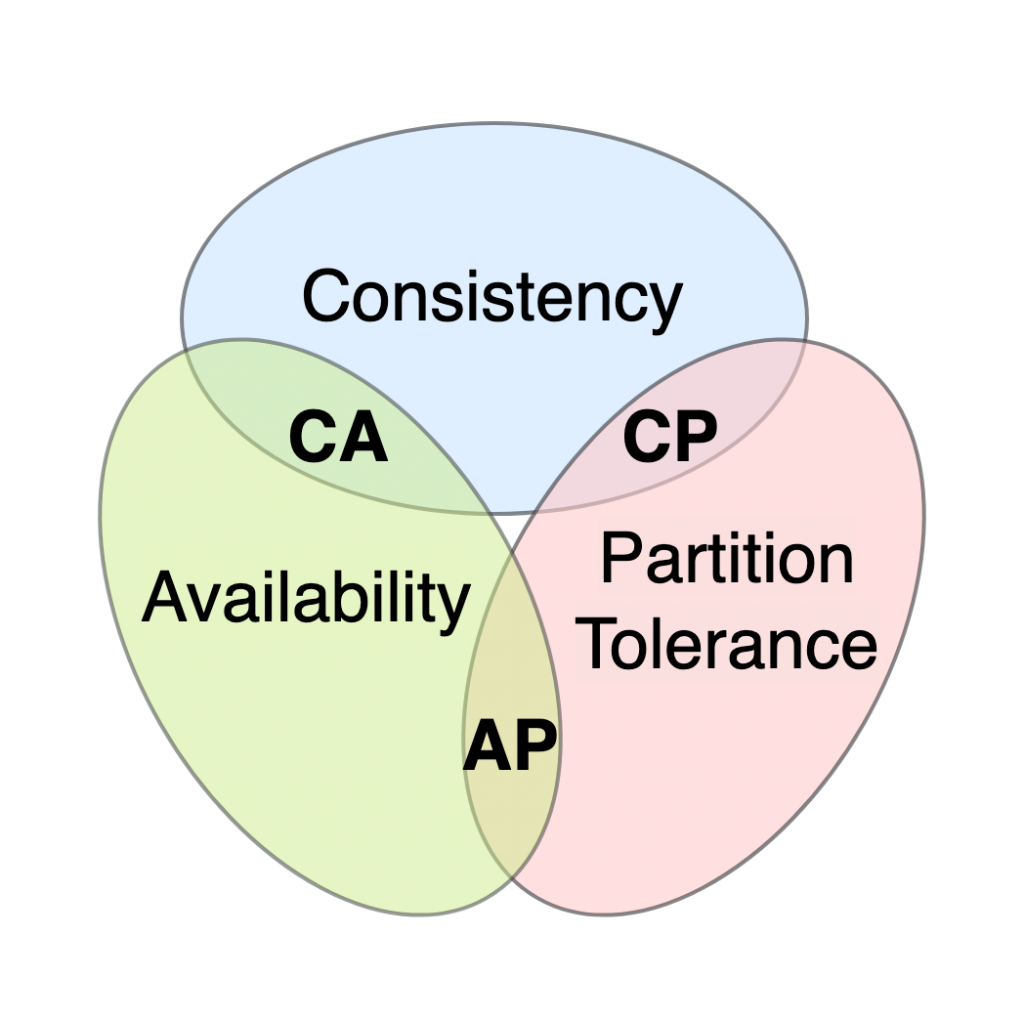
下面介紹一下 CAP 代表的意義
即資料的一致性, 假設分散式系統中, 我們將資料 "分散儲存在多個節點上"
當需要跨節點的操作時, 系統需要確保節點間資料的一致性
有點抽象, 明天會用以訂房系統為例說明 (太多寫不完...)
注意並不是所有分散式儲存的資料都會遇到一致性問題, 比如當系統是依照使用者 ID 作為 sharding (切片) key
將使用者資料分別儲存在不同的節點上, 那麼針對 "單一使用者的操作" 就不會有一致性問題
除非是 "跨節點的操作", 如明天會講的訂房系統的例子
需要強調一下, 在分散式系統中, 一致性是一種 "選擇", 而不是 "缺點", 所以某些情境中 "短時間的不一致" 是可以允許的
(題外話: 如果不需要一致性的話改用 NoSQL "可能" 比較適合, 因為更好擴展)
所以一致性又可以分為 強一致性 和 最終一致性
就如同明天會介紹的訂房系統, 若我們 "每次的讀寫操作都檢查並同步系統間的資料"
就可以確保 "使用者每次得到的都是最新的資料", 所以就是 強一致性
發現問題了嗎? 若資料分散在幾百個節點上, 每次使用者讀取都要先同步所有節點的資料, 時間複雜度就是 O(n)
就像是使用者每次查看自己訂單, 都需要等百倍於 最終一次性 需要的時間
如果請求太多的話, 我們的系統就會像是當機一樣永遠同步不完了...
這就犧牲了 Availability
常見做法有 2PC (Two-Phase Commit)
在某些情境下, 我們只要確保資料 "最終會達成一致" 就好, 中間會有一段資料不同步的時間, 而這是 "可以被接受的"
比如明天介紹的訂房系統, 我們只需要確定每個步驟的 transaction 能夠完成即可
常見的作法有 Saga Pattern


 iThome鐵人賽
iThome鐵人賽