不知不覺,已經來到第20天了!
前面已經了解LangChain基本語法與如何跟Vector DB串接起來
接下來要討論的就是如何去檢索到資料囉!
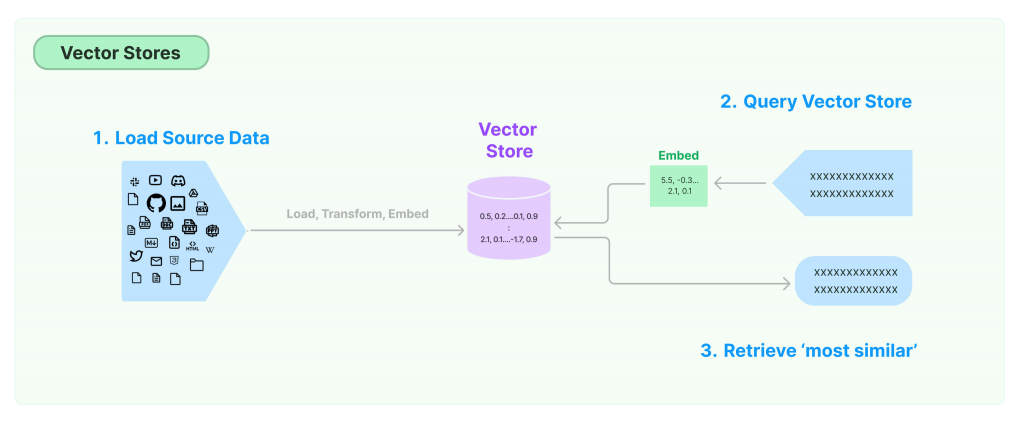
傳統上,Naive RAG的做法都是根據user query轉成embedding後,
進入到 Vector DB 後,去匹配出相關的top k個chunk,再連同user query一同餵給LLM來去生成出回答。
那我們現在要如何根據user query去找到存在vector DB中相關的chunk呢
就要透過我們LangChain框架中的retriever啦!
但在我們創建一個retriever前,我們必須要先知道這個東西是甚麼!
負責嵌入embedding和vector search,常作為retriever的骨幹,通常都是透過vector store去使用裡面的retriever,所以我們必須先設定好vector store。
vector_store = MongoDBAtlasVectorSearch(
collection=collection,
embedding=aoai_embeddings,
index_name=vector_search_index,
text_key="content" #這裡需要指定document文字的key。經過similarity找到相似的document後,會返回這個key的值
)
注意:
接受字串 query 作為input,並傳回 Document 清單作為output
而官方提供了許多 retriever 的方法
下一回將詳細介紹這些retriever的使用方法與意義!


 iThome鐵人賽
iThome鐵人賽