上一章談完模型命名的重要,足以讓我們不看 sql code 就知道模型裡面寫了什麼。接著來談談模型內容的命名。
首先是欄位的部分,最基本的是統一格式,提一些實用的案例:
where is_correct就很直觀,不需要加上 is true,絕對不是因為懶得打字。命名必須統一!以上是我們實作完的部分,都已經搬運完了才想到要來調整,為了改個名字還要把一堆增量更新(incremental) 的資料全部重新跑一遍,還去檢查了所有下游服務在使用的儀表板,耗費了一些不必要的成本,應該要在一開始就決定並實施的。
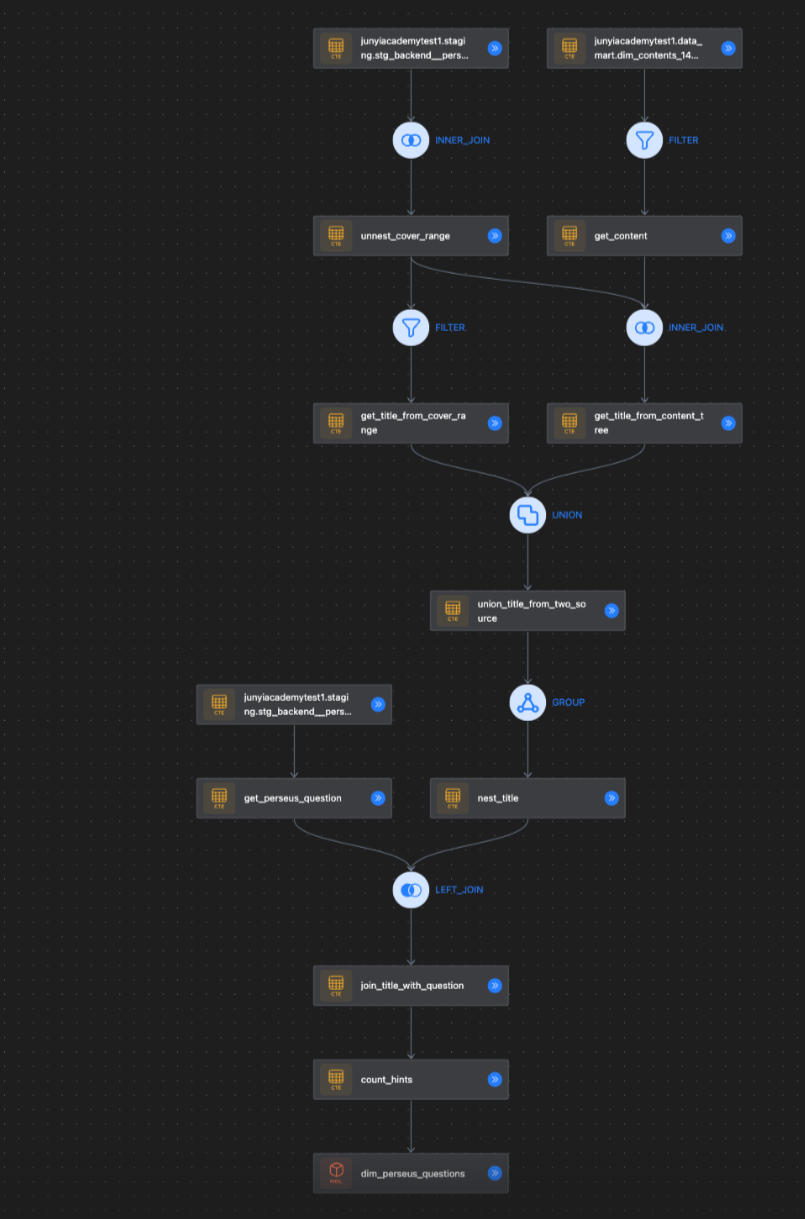
以下來提一個近期才發現 dbt power user 的新功能 - Visualize SQL,可以把模型中的資料來源、經過了哪些 cte、是透過什麼樣的 join,還是 filter/ group 的,關於模型間或模型內 cte 的血緣後續再多做說明,這邊想提一下這個新功能是在思考,若能統一 cte 的命名規則,在 code review 時就更輕鬆了!看一下模型名稱、看一下 cte 之間的血緣,基本上就可以對內容有八九成的肯定,可惜 cte 所進行的操作更多更雜,每個人心中出現的字彙都不相同,這時候就有點後悔英文學得不夠好,要在這種地方查翻譯查很久,沒辦法速速達成共識,希望之後有機會能實現。
補充:之前使用 BigQuery 時也是有陸續看到相關功能的推進,不過上次查看時,仍然只有剛執行完的內容可以看到這個血緣圖,而寫標註的還不是 cte 的名稱,而是 S00, S01 等等的,根本不知道對應 sql code 中的哪一段轉換。