今天我們要來 demo primsa 中 schema 的使用方式,大家還記得以下的 code 嗎?我們在 day 5 介紹 DB adapter 的時候有提到,怎麼讓 prisma 兼容其他 DB driver,還沒看過的讀者建議先去看 Day 5 的內容在看本篇會比較好喔~
import { Pool } from 'pg'
import { PrismaPg } from '@prisma/adapter-pg'
import { PrismaClient } from '@prisma/client'
const connectionString = `${process.env.DATABASE_URL}`
const pool = new Pool({ connectionString })
const adapter = new PrismaPg(pool)
const prisma = new PrismaClient({ adapter })
const main = async () => {
const data = await prisma.users.findMany({})
console.log(data)
}
然後筆者在文章中埋下一個伏筆是 prisma 其實支援 postgresql 的 schema 的功能,那經過昨天介紹 schema 用法後大家是不是有大概的概念了呢~接下來的篇幅將會說明在 prisma 中如何使用 schema 。
const adapter = new PrismaPg(pool, {
schema: 'myPostgresSchema'
})
開始之前我們要先確定我們的 SQL URL 是可以連上的,大家可以先到 zeabur 起一個 postgresql 的 DB server~
> psql "postgresql://YOUR_URL/zeabur"
進去之後我們先查看 DB 的 table ,那因為筆者是採用有在使用的 DB 所以目前才會有以下的 table ~
>zeabur=# \dt;
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+-------
public | Authenticator | table | root
public | _prisma_migrations | table | root
public | accounts | table | root
public | sessions | table | root
public | users | table | root
public | verificationtokens | table | root
(6 rows)
如果讀者沒有可以直接下 SQL 指令簡單的 create 一個 table
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
);
之後我們回到專案把你的 SQL URL 放到 DB
// .env
DATABASE_URL="YOUR_URL"
大家應該還記得我們需要同步 DB 到 prisma 所以要執行 pull 的動作
>npx prisma db pull
pull 成功後他會跟你說已經同步到你的 prisma 的 schema 了
>npx prisma db pull
Prisma schema loaded from prisma/schema.prisma
Environment variables loaded from .env
Datasource "db": PostgreSQL database "zeabur", schema "public" at "sfo1.xxx.zeabur.com:31437"
✔ Introspected 5 models and wrote them into prisma/schema.prisma in 4.55s
Run prisma generate to generate Prisma Client.
此時你查看一下 schema.prisma 真的確實有剛剛 create 的 table~
// schema.prisma
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model employees {
id String @id
name String
}
不過我們再仔細看一下剛剛 pull 的 log ,你會發現他會要你在執行一下 prisma generate ,原因是 db pull 不像執行 migration 一樣,會自動幫你 generate prisma client 需要的東西,包含 type 等等,所以每當你 pull 一次 DB 記得要再手動執行 generate
✔ Introspected 5 models and wrote them into prisma/schema.prisma in 4.55s
Run prisma generate to generate Prisma Client.
當你跑完 generate 並出現以下的 log 時候,這樣你的 DB pull 才算結束~
>npx prisma generate
Environment variables loaded from .env
Prisma schema loaded from prisma/schema.prisma
✔ Generated Prisma Client (v5.19.1) to ./node_modules/@prisma/client in 69ms
Start by importing your Prisma Client (See: http://pris.ly/d/importing-client)
Tip: Need your database queries to be 1000x faster? Accelerate offers you that and more: https://pris.ly/tip-2-accelerate
那因為我們目前的 table 是剛 create ,大家記得先去 prisma studio 先添加一筆資料,不然等下 data 會是空的
>npx prisma studio

之後我們簡單 get 一下 data
>tsx watch index.ts
//index.ts
const main = async () => {
const data = await prisma.users.findMany({})
console.log(data)
}
main()
現在我們終於拿到資料了~
[
{
id: '1',
name: 'Danny',
email: 'hiunji64@gmail.com',
emailVerified: null,
image: null,
createdAt: 2024-09-15T05:40:48.404Z,
updatedAt: 1970-01-01T00:00:00.000Z
}
]
大家應該還記得 schema 的概念很像是一個新的工作區,所有的 table 跟 data 都是獨立的,然後我們回到 SQL 去改一下我們的 schema 內容。
先 create schema
>zeabur=# CREATE SCHEMA test;
CREATE SCHEMA
成功 create
>zeabur=# \dn;
List of schemas
Name | Owner
--------+-------
public | root
test | root
(2 rows)
SET schema
>zeabur=# SET SEARCH_PATH=test;
SET
查看當前的 schema ,這樣我們就成功在另外一個 schema 工作了~
>zeabur=# SELECT CURRENT_SCHEMA;
current_schema
----------------
test
(1 row)
因為是新的 schema 所以也不會有任何 table
>zeabur=# \dt;
Did not find any relations.
那一樣我們 create 一個新的 table 並查看有沒有成功
>zeabur=# CREATE TABLE test(
id SERIAL PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE
>zeabur=# \dt;
List of relations
Schema | Name | Type | Owner
--------+------+-------+-------
test | test | table | root
(1 row)
改好後我們的 connect URL 記得加上 schema 這個 query 到 DB URL 上
//.env
DATABASE_URL="postgresql://***.***/zeabur?schema=test"
並執行 DB pull
>npx prisma db pull
你會發現我們的 schema 換成 test 這個 shcmea 有的 table 了,是不是很神奇~
// prisma.schema
model test {
id Int @id @default(autoincrement())
name String? @db.VarChar(50)
}
但這時你如果執行 generate 你會發現
>npx prisma generate
prisma 根本不知道你的 schema 有更動,prisma 還以為你在 public 這個 schema
>npx prisma generate
PrismaClientKnownRequestError:
Invalid `prisma.test.findMany()` invocation:
The table `public.test` does not exist in the current database.
於是我們調整一下我們 adapter 的 schema 這樣你才可以成功 generate prisma client
const adapter = new PrismaPg(pool, {
schema: 'test'
})
但 generate 後你會發現,剛剛 get users 的 code 有問題了,原因是我們目前的 prisma client 已經是新的 schema 的內容,自然也不會有 public 的 table
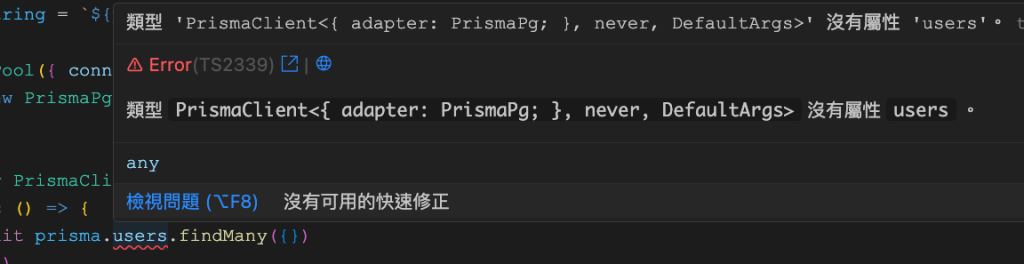
於是我們調整成新的 test table
const main = async () => {
const data = await prisma.test.findMany({})
console.log(data)
}
最後我們在執行一下 index.ts 如次我們就成功替換不同的 schema 了
>tsx watch index.ts
[]
經過這幾天介紹 schema 的功能後相信大家對 shcmea 應該印象更加深刻了,筆者認為, schema 的使用情境會是當你有不同的 project 需要共同同一個 DB 時,不希望彼此的 table 或是 data 被污染到,才會需要用 schema ,使用上是蠻方便的,如果讀者喜歡的話或許可以用在自己的 project 上~好了今天內容先到這感謝大家耐心的閱讀,我們明天見~
✅ 前端社群 :
https://lihi3.cc/kBe0Y

