這題要我在一個字串 s 中,找到所有起始索引,讓從這些索引開始的子字串,剛好是 words 中所有字串的排列組合串連而成,困難點在於,怎樣有效的找到所有可能的子字串,檢查它們是不適符合條件。
想法:
理解題目要的是找到所有起始位置,讓這些位置的子字串能完美匹配 words 的所有字串,這表示每個子字串的長度等於 words 的總長,且須包含 words 中的所有字串(順序可以不同)。
滑動視窗:由於 words 的所有字串長度相同,我可以用一個固定長度的滑動視窗(每次檢查的子字串長度等於 words 的所有字串總長)遍歷字串 s,檢查每個子字串是不是 words 中字串的排列組合。
計數詞頻:為檢查某個子字串是不是 words 中字串的排列組合,可以用哈希表來記錄 words 中每個字串的詞頻,然後遍歷每個子字串,把它切成跟 words 中字串同長度的小片段,檢查這些片段的詞頻是否匹配。
多指針跟優化:因為這題的數據範圍蠻大的(最多可處理長度為 10^4 的字串),一個暴力解法的時間複雜度過高,所以我需要用滑動視窗和哈希表來優化,同時,如果在某個窗口範圍內詞頻不匹配,可以提早跳過不可能的起始位置,減少不必要的計算。
步驟:
先檢查基礎條件,如果 s 的長度小於 words 的總長,就不可能存在這樣的子字串,直接返回空結果,算子字串長度,算 words 裡所有字串的總長度 substring_length,用一個哈希表 word_count 來記錄 words 中每個字串的出現次數,滑動視窗檢查子字串,從 s 中每個可能的起始位置 i 開始(從 0 到 len(s) - substring_length),每次取長度為 substring_length 的子字串,把這個子字串切割成跟 words 裡字串一樣長的小段,然後檢查這些小段是否匹配 word_count 中的記錄就如果某個子字串匹配,則把它的起始索引記錄下來,返回所有符合條件的起始索引。
困難:
最大的困難就是時間複雜度因為數據量很大,如果不用滑動視窗或哈希表來優化,時間複雜度會過高,邊界條件,要仔細處理 s 長度小於 words 的總長度、words 中有重複字串等等邊界情況。
初始化參數:
先算每個子字串的總長,就是 len(words) * len(words[0])。
創一個哈希表 word_count 來記錄 words 中每個字串出現的次數,用滑動視窗來遍歷字串 s,從 0 開始,檢查每個長度是substring_length 的子字串是不是 words 中字串的排列組合,遍歷過程中,把提出來的子字串分成等長的小段(長度為 len(words[0])),檢查這些段的出現次數是不適和 words 中的字串相匹配。
問題:
需要仔細處理重複字串的情況,邊界條件,像 s 長度小於 words 總長時,要直接返回空列表,優化性能,免去不必要的重複計算。
心得:
這題的難點在怎麼有效率的檢查字串中是不是存在符合條件的子字串,用滑動視窗技術可以幫我避免重複檢查每個字元,且透過哈希表來記錄 words 中字串的出現次數,可以大大提高處理效率。
在想的的過程中,我遇到的最大問題是怎麼正確處理字串的詞頻問題,尤其是有重複字串時,要非常謹慎,解決這個問題的關鍵就在,利用兩個哈希表來比較,這樣就能確保每次的視窗檢查都能準確匹配到目標字串,同時這題也強化了我對滑動視窗和哈希表的理解,在處理大量數據時非常有用。
完整程式碼:
class Solution(object):
def findSubstring(self, s, words):
"""
:type s: str
:type words: List[str]
:rtype: List[int]
"""
#如果 s 或 words 為空,直接返回空列表
if not s or not words:
return []
word_length = len(words[0]) # 每個字串的長度
total_words = len(words) # words 中字串的總數
substring_length = word_length * total_words # 所有字串組合的總長度
word_count = {} # 記錄 words 中每個字串的出現次數
#初始化 word_count
for word in words:
word_count[word] = word_count.get(word, 0) + 1
result = [] # 存儲結果的列表
#開始遍歷 s,每次考慮一個長度為 substring_length 的子字串
for i in range(len(s) - substring_length + 1):
seen_words = {} # 記錄當前視窗內出現的字串
for j in range(total_words):
# 提出當前的單字串
word_start = i + j * word_length
word = s[word_start:word_start + word_length]
#檢查這個字串是不是在 word_count 中
if word in word_count:
seen_words[word] = seen_words.get(word, 0) + 1
#如果這個字串出現次數超過了在 word_count 中的次數,跳出
if seen_words[word] > word_count[word]:
break
else:
break
else:
# 如果所有字串都符合條件,把起始索引加入結果
result.append(i)
return result
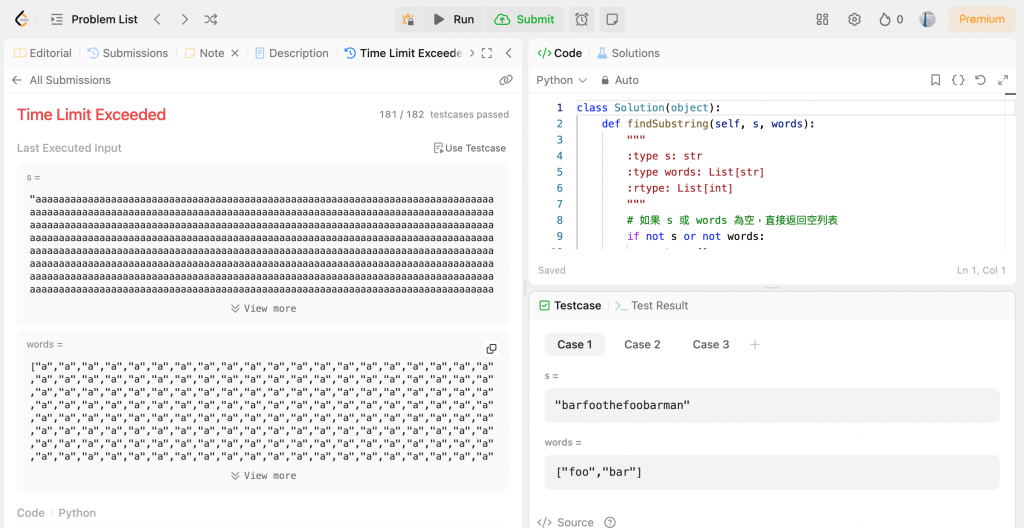
當我以為我成功了,資料是跑得出來,結果也顯示accepted但我要繳交因為效率太低,它不讓我上傳,我只好再次改進,每次寫程式最討厭遇到的狀況就是,以為自己成功了,結果又冒出一個不知哪來的問題。
更改後程式碼:
class Solution(object):
def findSubstring(self, s, words):
"""
:type s: str
:type words: List[str]
:rtype: List[int]
"""
if not s or not words:
return []
word_length = len(words[0]) # 每個字串的長度
total_words = len(words) # words 中字串的總數
substring_length = word_length * total_words # 所有字串組合的總長度
word_count = {} # 記錄 words 中每個字串的出現次數
#初始化 word_count
for word in words:
word_count[word] = word_count.get(word, 0) + 1
result = []
**#這個迴圈保證從不同的起點開始遍歷,避免漏掉可能的解**
for i in range(word_length):
left = i # 視窗的左邊界
current_count = {} # 記錄當前視窗內的字串出現次數
count = 0 # 當前匹配的字串數量
#以步長 word_length 遍歷
for right in range(i, len(s) - word_length + 1, word_length):
word = s[right:right + word_length] # 提取當前字串
if word in word_count:
current_count[word] = current_count.get(word, 0) + 1
count += 1
#如果當前字串出現次數過多,移動左邊界來維持視窗
while current_count[word] > word_count[word]:
left_word = s[left:left + word_length]
current_count[left_word] -= 1
count -= 1
left += word_length
#如果匹配字串數量等於總字串數,記錄當前左邊界
if count == total_words:
result.append(left)
else:
# 如果當前字串不在 word_count 中,重置視窗
current_count.clear()
count = 0
left = right + word_length
return result
這個方法會依次嘗試從不同的起點開始,對 s 進行切片處理,以此實現類似於滑動視窗的效果
解釋:
不同起點處理,這段程式碼用了從不同位置開始遍歷字串 s 的方式,免除錯過可能的匹配,在每次循環中,從 i 開始遍歷,逐步從每個步長為 word_length 的位置來進行檢查。
哈希表與滑動視窗,通過用兩個哈希表,一個用來記錄 words 的字串頻率,另一個用來算目前視窗裡的字串頻率,確保可以及時檢查字串有沒有符合條件,如果有多餘的字串進入視窗,就會不斷調整左邊界來維持視窗大小,效率提升,這個方法避免逐個字元移動,且直接按字串長度來分段處理,讓檢查過程更高效,且只有在確保所有字串的出現次數匹配後,才會將起始索引加入結果列表。
優點:
效率更高,在大字串 s 和 words 列表時,能減少不必要的重複遍歷,提升運算速度,邏輯更清楚,通過哈希表的應用和滑動視窗結合起來,讓整個解題過程更清晰,處理字串時對記憶體的消耗也更少,運算速度更快,尤其是在處理大規模資料時。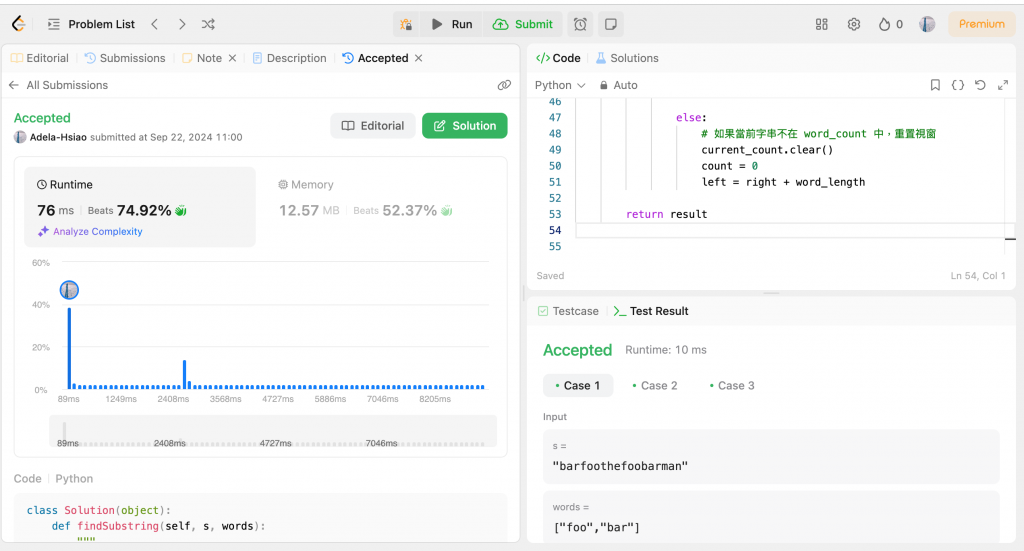


 iThome鐵人賽
iThome鐵人賽