進入下一個主題分類啦 ~ 接下來我們會練習一些 Reverse 的題型。今天會從簡單的內容切入,只需要觀察能解的題目。
8 位元的 Unicode 轉換格式是當前全球最廣泛使用的字元編碼標準之一。它將 Unicode 字元集中的每個字元編碼為 1 到 4 個位元組,解決了跨平台顯示多語言文本的問題,並在網路及軟體開發中扮演著不可或缺的角色。
隨著網際網路的崛起和全球化的推動,單一語言的字元編碼方式如我們曾在 Day8 中提到 ASCII 編碼,以及其他區域性編碼系統,逐漸無法滿足多語言文本的需求。為了統一不同語言的字元表示,創建 Unicode 字元集,目的是為每種語言的每個字元提供唯一的碼點。
UTF-8 是 Ken Thompson 和 Rob Pike 於 1992 年設計的。將 Unicode 字元以 8 位元序列的方式進行編碼,兼具效率和向後相容性,因此成為目前最流行的編碼標準。
UTF-8 是一種可變長度的編碼方式,依據字元的範圍,使用 1 到 4 個位元組來表示不同的 Unicode 字元:
這種可變長度編碼確保常見字元能以最少的位元組表示,提升了儲存和傳輸的效率。
相容性: UTF-8 的前 128 個字元與 ASCII 相同,因此能夠無縫處理所有 ASCII 文本,並且無需對現有系統進行大幅修改。
儲存空間效率提升: 相較於固定長度編碼(如 UTF-16 或 UTF-32),UTF-8 在處理英文的文件時更為節省空間。
支援全球語言: UTF-8 能夠編碼所有 Unicode 字元,成為支援多語言應用的好選擇。
廣泛相容性: 由於 UTF-8 與 ASCII 的相容性,許多現有系統可以輕鬆過渡到 UTF-8,減少了技術成本。
UTF-8 編碼處理不同字元:
ASCII字元:
字元:A
Unicode 編碼:U+0041
UTF-8 編碼:41(1 個位元組)
非 ASCII 拉丁字元:
字元:ñ(西班牙語)
Unicode 編碼:U+00F1
UTF-8 編碼:C3 B1(2 個位元組)
中文字元:
字元:你
Unicode 編碼:U+4F60
UTF-8 編碼:E4 BD A0(3 個位元組)
表情符號:
字元:😊
Unicode 編碼:U+1F60A
UTF-8 編碼:F0 9F 98 8A(4 個位元組)
開始今天的練習 ~
Lab_1 - Transformation
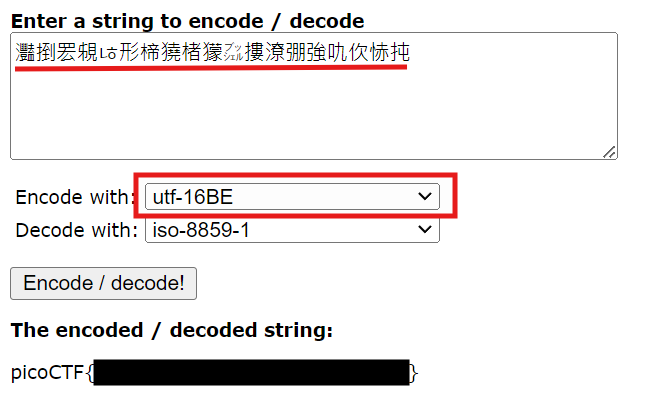
打開 enc 檔案後發現一串看不懂的字 灩捯䍔䙻ㄶ形楴獟楮獴㌴摟潦弸強㕤㐸㤸扽,可以推斷可能出跟UTF 的編碼有關
再看看題目的敘述 ''.join([chr((ord(flag[i]) << 8) + ord(flag[i + 1])) for i in range(0, len(flag), 2)])。意思是將 flag 字串每個字元編碼往左邊移八位。具體來說,就是將兩個字元的數值合併成一個整數。例如,對於 flag[i] = 'A' 和 flag[i + 1] = 'B',ord('A') = 65,ord('B') = 66,結果是 (65 << 8) + 66 = 16706。(65*8 + 66 = 16706)
等於兩個八位元的字元組合成一個十六位元的字元,試試看 UTF-16
用這個酷酷的解碼工具 Character Encoder / Decoder Tool 讓他幫我們解碼回去成 flag 原本的模樣
Lab_2 - Reverse
這題我們會用到一個會很常使用到的指令 strings
strings指令是 Unix/Linux 系統中的一個工具,主要用於從二進位檔案中提取可讀的文字字串。用來分析二進位檔案、可執行檔案或其他資料檔案,快速找出其中的可讀內容。
- 提取可讀文字字串:
strings指令會掃描二進位檔案,並顯示其中的可讀 ASCII 或 Unicode 字串。這些字串通常由於編程需求被嵌入在檔案中,比如日誌訊息、錯誤提示、路徑、檔案名稱等。- 分析二進位檔案: 開發者、逆向工程師或資安研究人員可以使用
strings來分析二進位檔案,嘗試發現其中的有用資訊,特別是在進行逆向工程、惡意程式分析或 CTF 比賽中。- 快速檢查資料檔案: 當不確定檔案的內容時,可以使用
strings查看該檔案是否包含可讀文字、檔案類型或其他線索。
我們對題目附上的檔案 ret 使用 strings ret 這個指令,印出所有可讀的字串。

今天的練習就到這邊,以下是參考資料,請搭配服用:
UTF-8
UTF-8 編碼原理
位元組順序
strings 指令
內文如有錯誤,還請不吝指教~


 iThome鐵人賽
iThome鐵人賽