我們改用 dbt core 了!
先不講一些高大上的價值跟理由,一開始急著要研究這個轉移,最關鍵的還是看到這個方案:
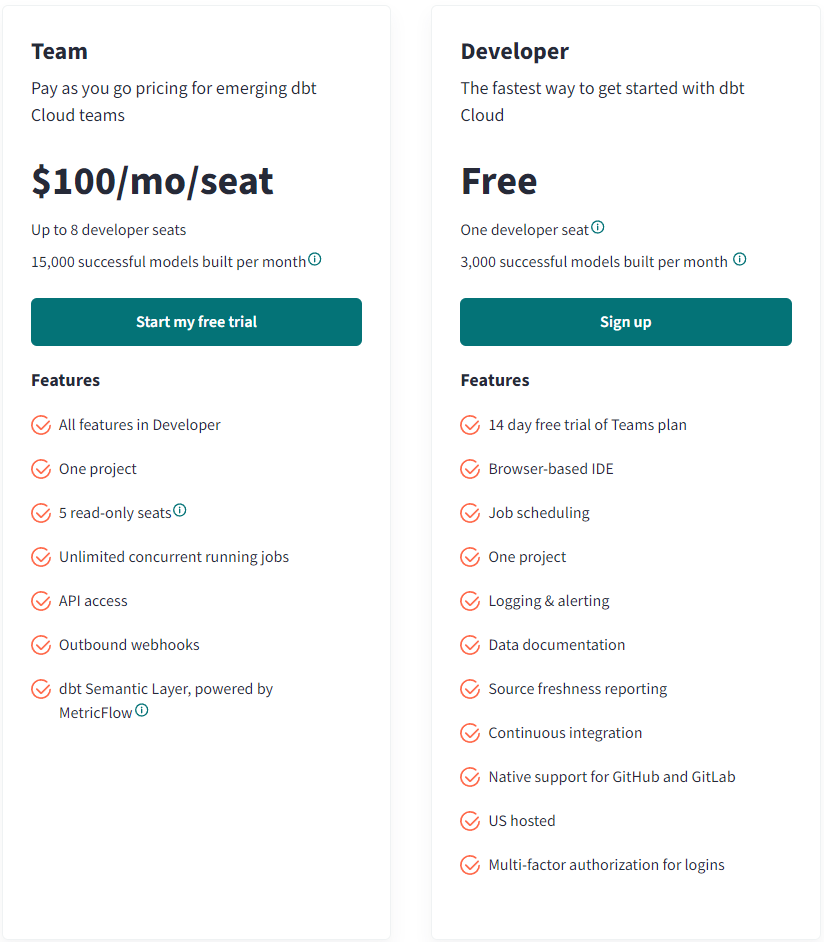
免費的 developer 每個月只能建立 3000 個模型,在依循著 best practice 操作時,時常為了把流程拆解乾淨,而將整個 pipeline 分解成更多個模型,3000 個模型一天只能跑一百個,要是一天跑多次(一小時一次),跑個四五個就超過上限了、即使是付錢提升至團隊方案,也只增加五倍,超過 15000 個之後,每個模型 0.01 美元,會蠻受到限制的(不是 dbt,而是貧窮限制了我)。
雖然去年在搬遷的過程中,dbt 就已經說要開始收費了,但我們的免費帳號仍然可以跑超過 3000 個模型,我們還是嗅到了收費的大手已經近在眼前,加緊腳步逃跑(?),看討論今年好像就正式開始收費了。
dbt 自己有提供一個比較表(連結),講述 core 跟 cloud 的差異,如果是電視廣告,肯定會看到 dbt cloud 那一側有一整排「勝!」的圖示。
但我自己使用起來,dbt core 加上了 power user,開發的功能性上跟 dbt cloud 旗鼓相當,而在版本跟新功能上,dbt cloud 推出的新功能,power user 跟上的速度都蠻快速的,加上現在 Cursor 編譯器結合了 AI 功能,打幾個字之後就可以幫我把後面的內容生成完畢,可說是如虎添翼啊!
在本機的 IDE 上,開發起來更加的自在,不會因為網路問題做不了或是心血直接消失,作為開發者的一些無謂的堅持,可以在自己的 IDE 上透過各種自定義的功能體現出來。
pipeline 之間是有相依性的,像是原始資料的處理,我們目前是依賴 airflow 觸發,而使用 dbt cloud 自己原生的排程系統,假設我安排 airflow 在 8 點處理資料,預計處理 30 分鐘,因此我將 dbt cloud 的任務安排在 8 點半,而若是 airflow 的處理過程中出現問題,dbt cloud 仍然會開始工作,不管前人的死活。
這時候就得使用 dbt cloud 的 api,而 api 去觸發相應的工作流程是付費才能解鎖的功能,這就表示我們既沒有使用到 dbt cloud 原生的排程系統,又要付錢解鎖這些必要的功能,不太划算。
因此,根據大多數的討論,通常都會在轉往使用 dbt core 後,搭配 airflow 等組織原先就有的任務排程系統,讓整條 pipeline 上的任務可以一個接著一個的順利進行,後面會再花篇幅來討論我們怎麼讓 airflow 與 dbt 進行協作。
如果只是剛開始摸摸看這個工具,我覺得暫時用一下 dbt cloud 也不失為一種選擇,反正一開始也不會需要處理很多的模型運算。
dbt core 還是要花一些額外的力氣來處理的,下一篇我們會討論在部署 dbt core 時遇到的問題,以及我們的解決方式!

