如果我們需要從s3撈資料出來看,除了可以用S3提供的query之外,還可以選擇使用Athena。為什麼不直接使用S3提供的query呢?S3提供的query較不彈性,使用者無法自己定義欄位名稱。
舉例來說,如果你有一些apache access log長這樣:
如果使用Query with S3 Select並輸出成csv格式。
雖然可以選擇格式化,但是無法針對每個欄位命名。
如果想要只看某個欄位的資料,必須自己去計算要取出第幾個欄位的資料,非常不方便。
所以使用Athena,可以更彈性的幫忙做資料的分析,過濾出需要的資料,接下來就會介紹,要怎麼做才能在Athena撈取到S3的資料。
到Athena的console之後,打開Query editor,並下新增database的指令產生database。其實也可以直接使用default,但是為了區格資料,在這邊我還是新增一個新的。
CREATE DATABASE IF NOT EXISTS log_analysis;
新增完之後,就可以在左邊的下拉選單看到新增的database。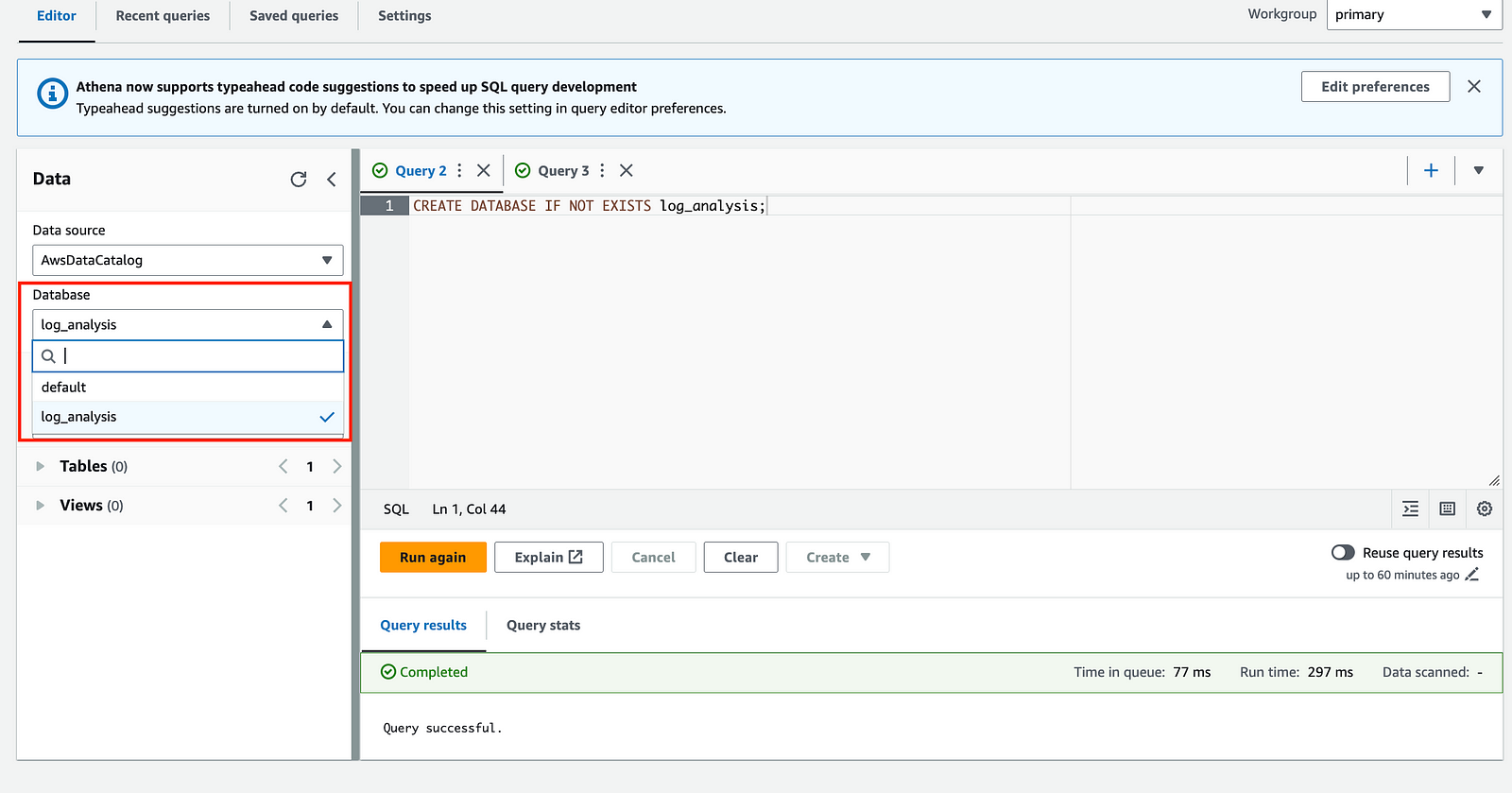
接著就可以在database底下,下指令新增table。在新增table的時候,就像在一般常用的Mysql或Postgresql一樣,需要定義schema,指定每個欄位的名稱和型別,並在ROW FORMAT SERDE指定要使用哪種方式解析資料,在這邊選用了Regex的話,需要在SERDEPROPERTIES說明你的資料格式,這樣才能讓Athena正確解析在S3的資料(資料格式很複雜,不知道怎麼轉,可以請chatGPT幫忙喔XD)。
CREATE EXTERNAL TABLE IF NOT EXISTS log_analysis.apache_logs (
client_ip STRING,
identity STRING,
user STRING,
request_time STRING,
request STRING,
status_code INT,
size INT,
referer STRING,
user_agent STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex' = '^(\\S+)\\s+(\\S+)\\s+(\\S+)\\s+\\[(.*?)\\]\\s+"(.*?)"\\s+(\\d{3})\\s+(\\S+)\\s+"(.*?)"\\s+"(.*?)"$'
)
LOCATION 's3://hjoru-access-log/'
TBLPROPERTIES ('has_encrypted_data'='false');
新增完table之後,就可以在左邊看到結果。
前面的步驟都做好,就可以查詢資料了。指定database(log_analysis)和table(apache_logs),並根據需求下query的條件,就可以開始查詢。
SELECT client_ip, request, status_code, size, referer, user_agent
FROM log_analysis.apache_logs
WHERE status_code = 200
AND request LIKE 'GET%';
查詢結果可以看到,很清楚地列出每一筆資料的資訊,而且可以用欄位名稱指定要看的欄位,比S3的query好很多。

