在上一章節,我們介紹了 Linux 的 cgroup(Control Groups)技術用於資源限制的概念。本章將聚焦於 Docker 容器,通過實驗探索資源限制的實際效果和特性。
在該使之前,讓我們先準備好測試環境和工具。
首先,通過以下指令查看 Docker 提供的資源限制參數:
docker container run --help
#
[...]
-c, --cpu-shares int CPU shares (relative weight)
--cpus decimal Number of CPUs
--cpuset-cpus string CPUs in which to allow execution (0-3, 0,1)
--cpuset-mems string MEMs in which to allow execution (0-3, 0,1)
[...]
-m, --memory bytes Memory limit
--memory-reservation bytes Memory soft limit
--memory-swap bytes Swap limit equal to memory plus swap: '-1' to enable
unlimited swap
[...]
其中,--memory-reservation 的描述中提到它是一種「軟性限制」,怎麼記憶體也有「軟性限制」?
實際上,它更接近於「記憶體保留」的功能:
這與 Kubernetes 中的 request 和 limit 概念一致,可參考 Kubernetes Limit Range 官方文件。
stress-ng 是一款強大的 Linux 壓力測試工具,支持模擬多種資源負載(如 CPU、內存、I/O 和網絡),幫助用戶測試系統在高負載下的性能和穩定性。
由於基礎鏡像 Alpine 不包含 stress-ng,我們需要手動構建。
FROM alpine:latest
# 安裝必要工具
RUN apk update && apk add --no-cache stress-ng
# 設置 ENTRYPOINT 使容器啟動時執行壓力測試命令
ENTRYPOINT ["stress-ng"]
執行以下指令構建鏡像:
docker image build -f Dockerfile.stress -t stress:alpine .
為了更好地測試記憶體限制,我們構建一個專用鏡像,包含自定義腳本。
腳本:run.sh
#!/usr/bin/env sh
timeout 20 sh -c '
used=0
for i in $(seq 1 10); do
sleep 2
used=$((used + 100))
stress-ng --vm 1 --vm-bytes 100M --vm-keep --quiet &
echo "Used Memory: ${used}M"
done
wait
'
說明
每隔 2 秒新增一個100M記憶體佔用的stress-ng工作,並累加輸出當前已用記憶體量。
範例輸出:
Used Memory: 100M
Used Memory: 200M
Used Memory: 300M
...
Used Memory: 1000M
Dockerfile
FROM alpine:latest
# 安裝必要工具
RUN apk update && apk add --no-cache stress-ng
# 複製腳本到容器
COPY run.sh /usr/local/bin/run.sh
# 確保腳本可執行
RUN chmod +x /usr/local/bin/run.sh
# 設置 ENTRYPOINT
ENTRYPOINT ["/usr/local/bin/run.sh"]
構建指令:
docker build -f Dockerfile.stress.memory -t stress:memory .
在測試過程中,使用以下工具監控資源使用狀況:
htop:交互式系統監控工具,用於查看 CPU、內存等系統資源使用情況。docker stats:顯示運行中容器的資源使用情況。tail -f /var/log/syslog | grep -i "oom":監控系統日誌中有關 OOM(Out of Memory)的記錄。docker container run -it --rm --name stress --cpus=0.5 stress:alpine -c 1 -t 10
結果:
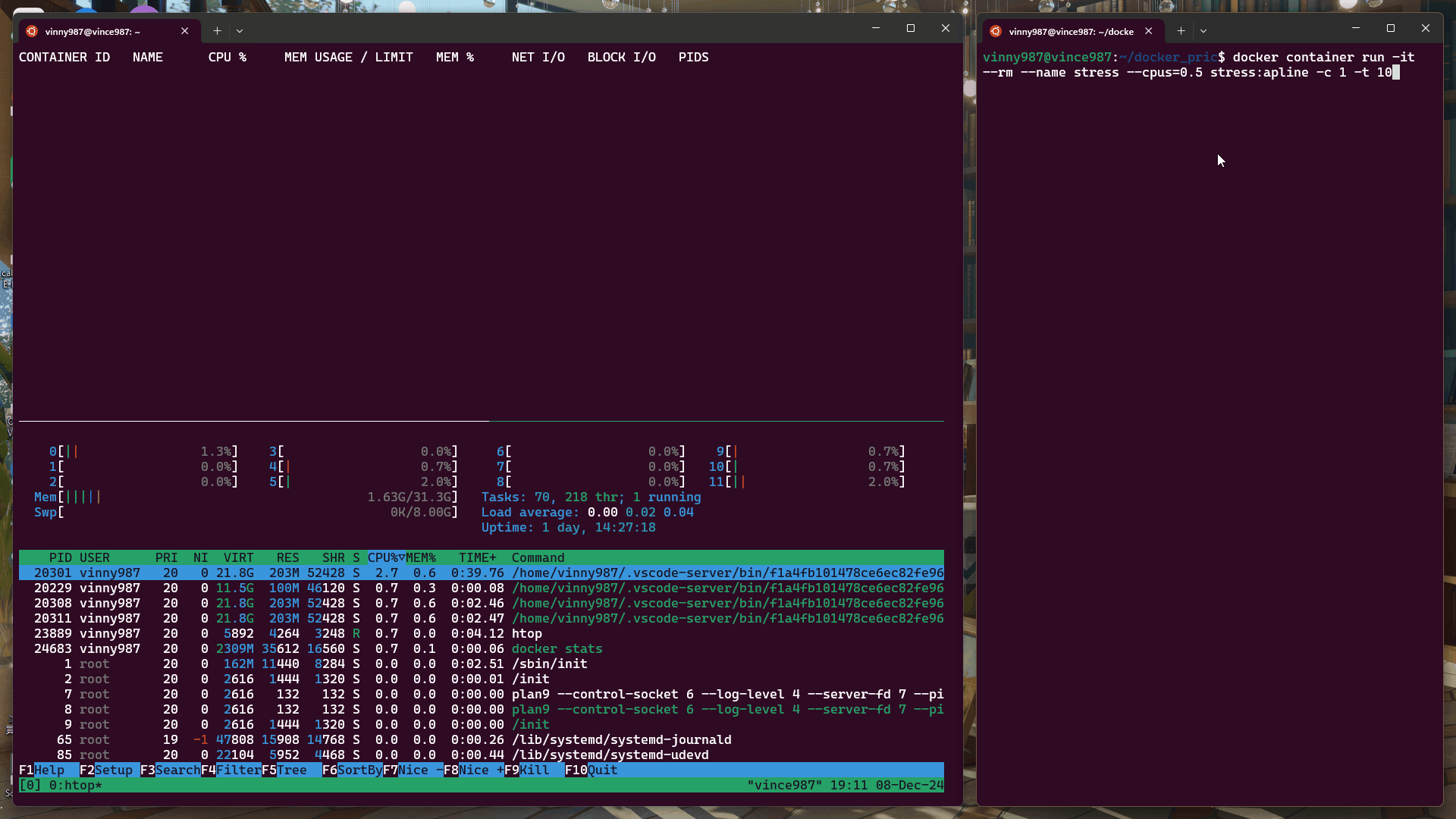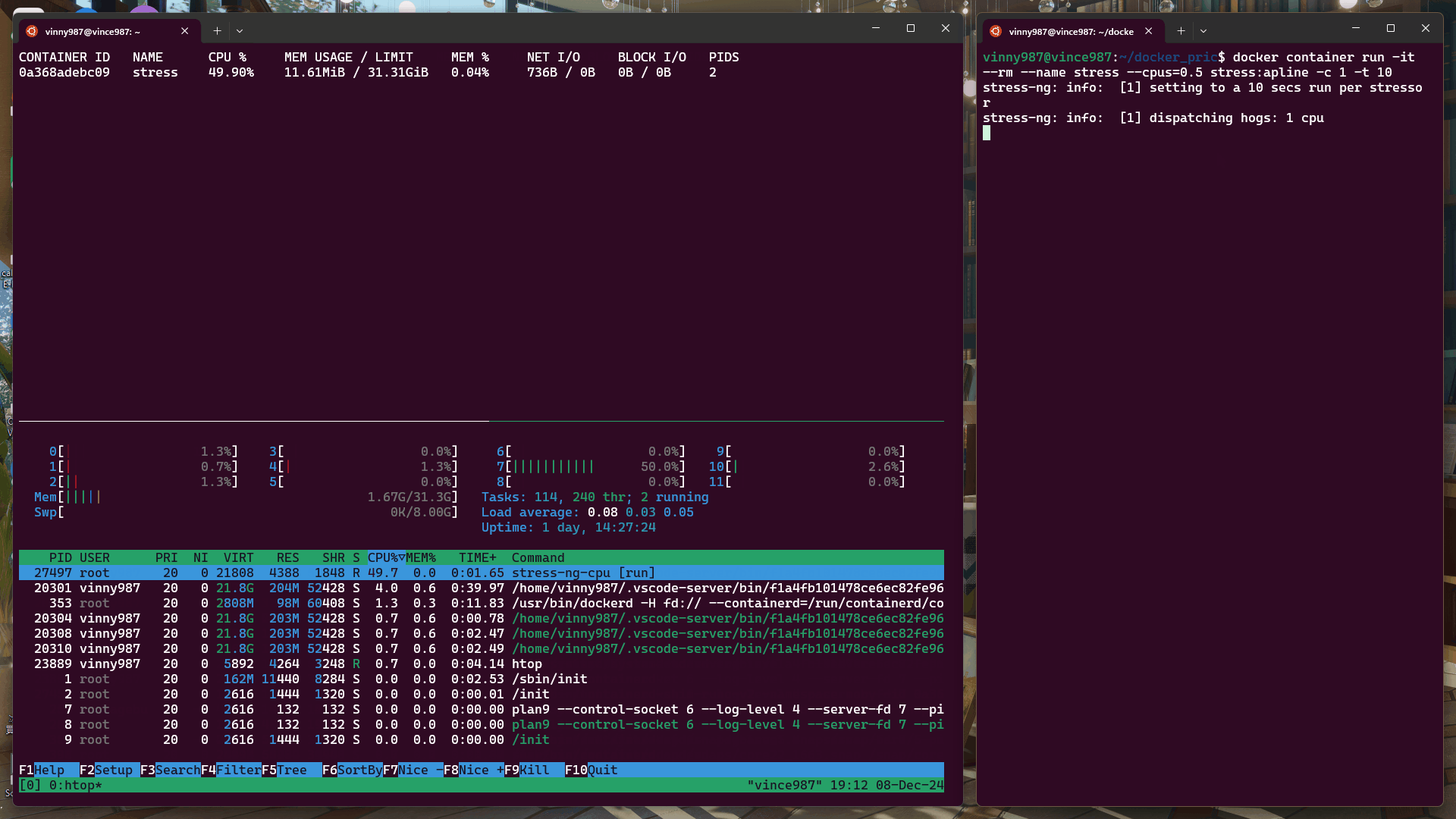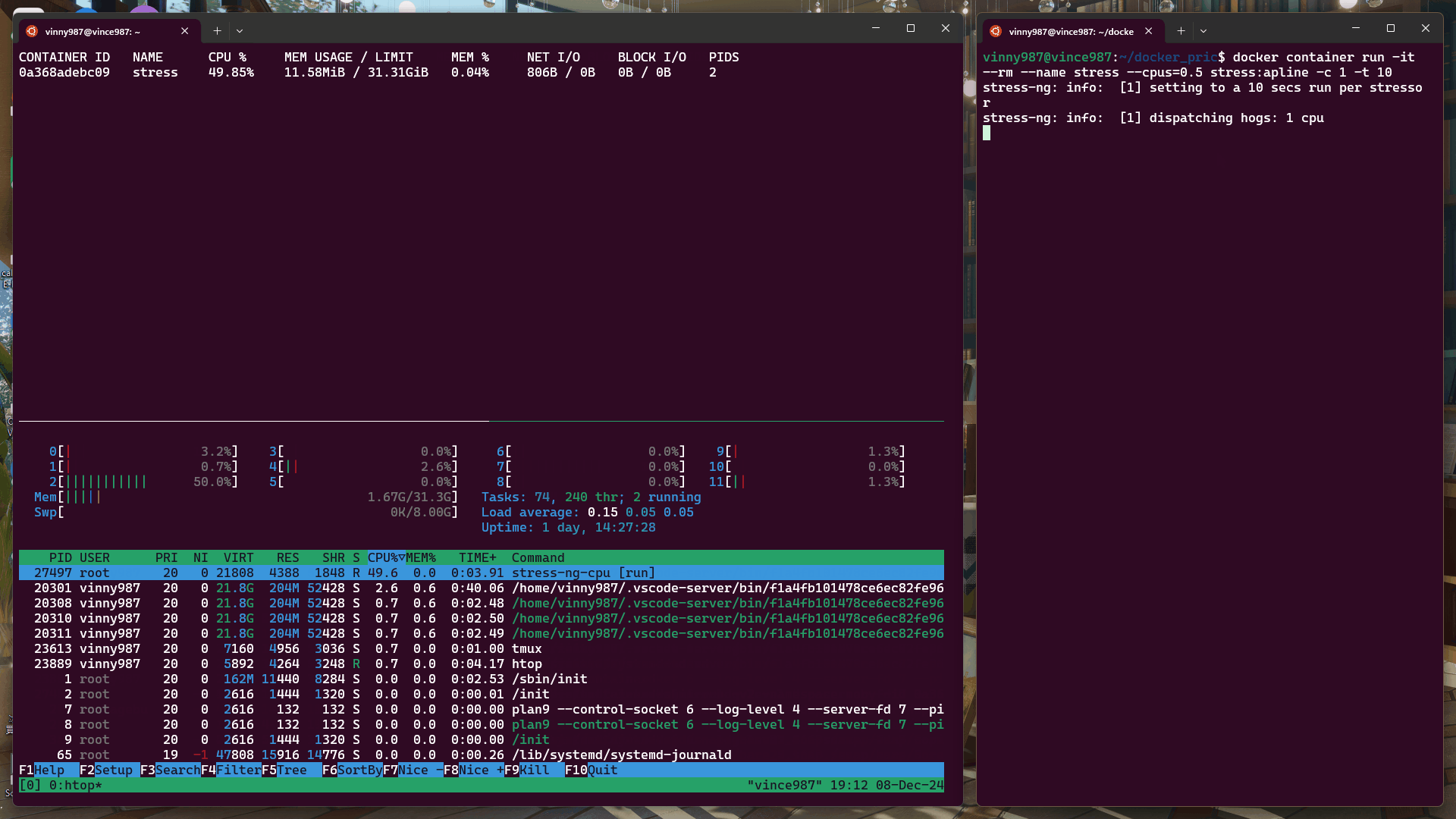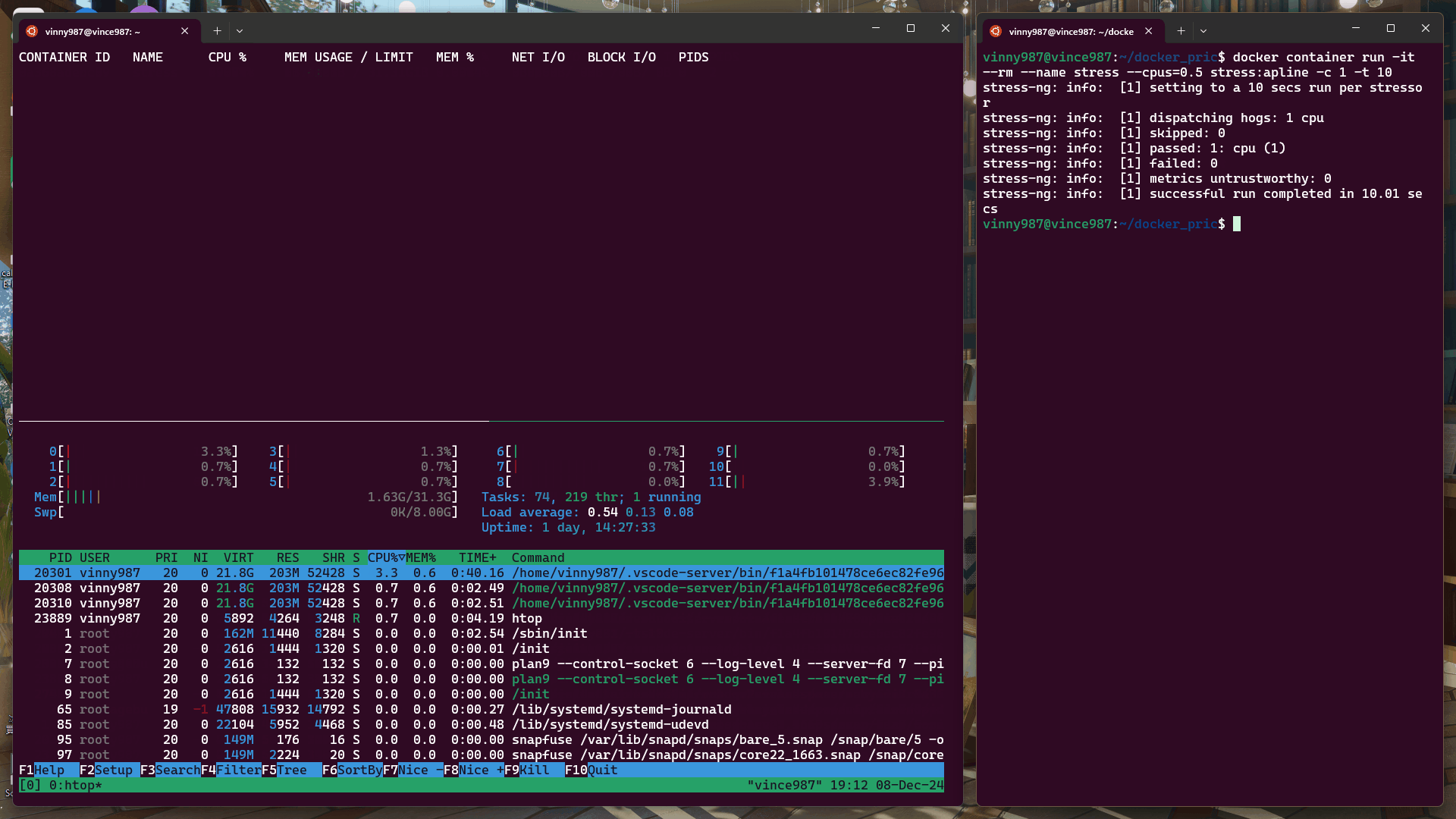
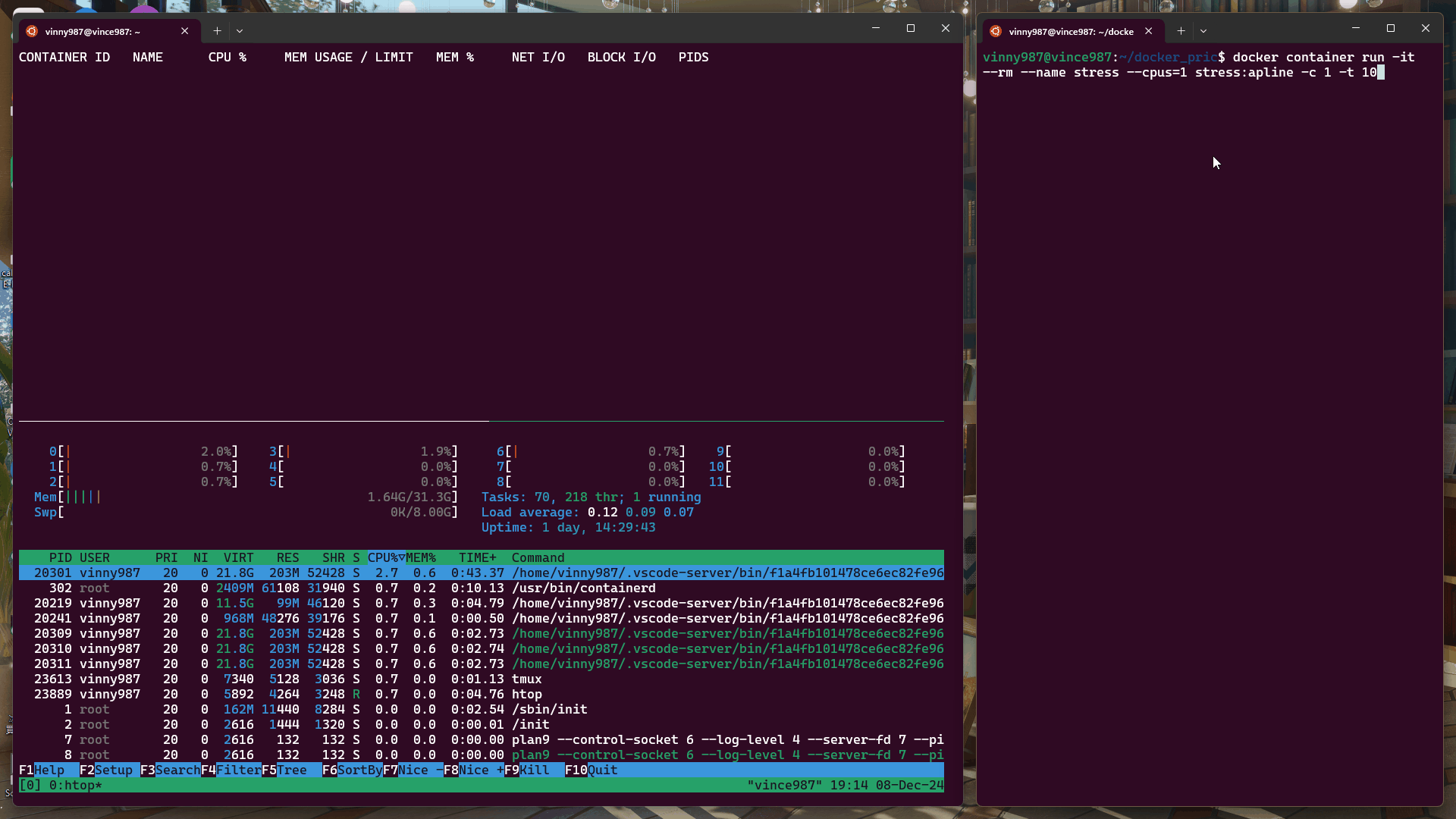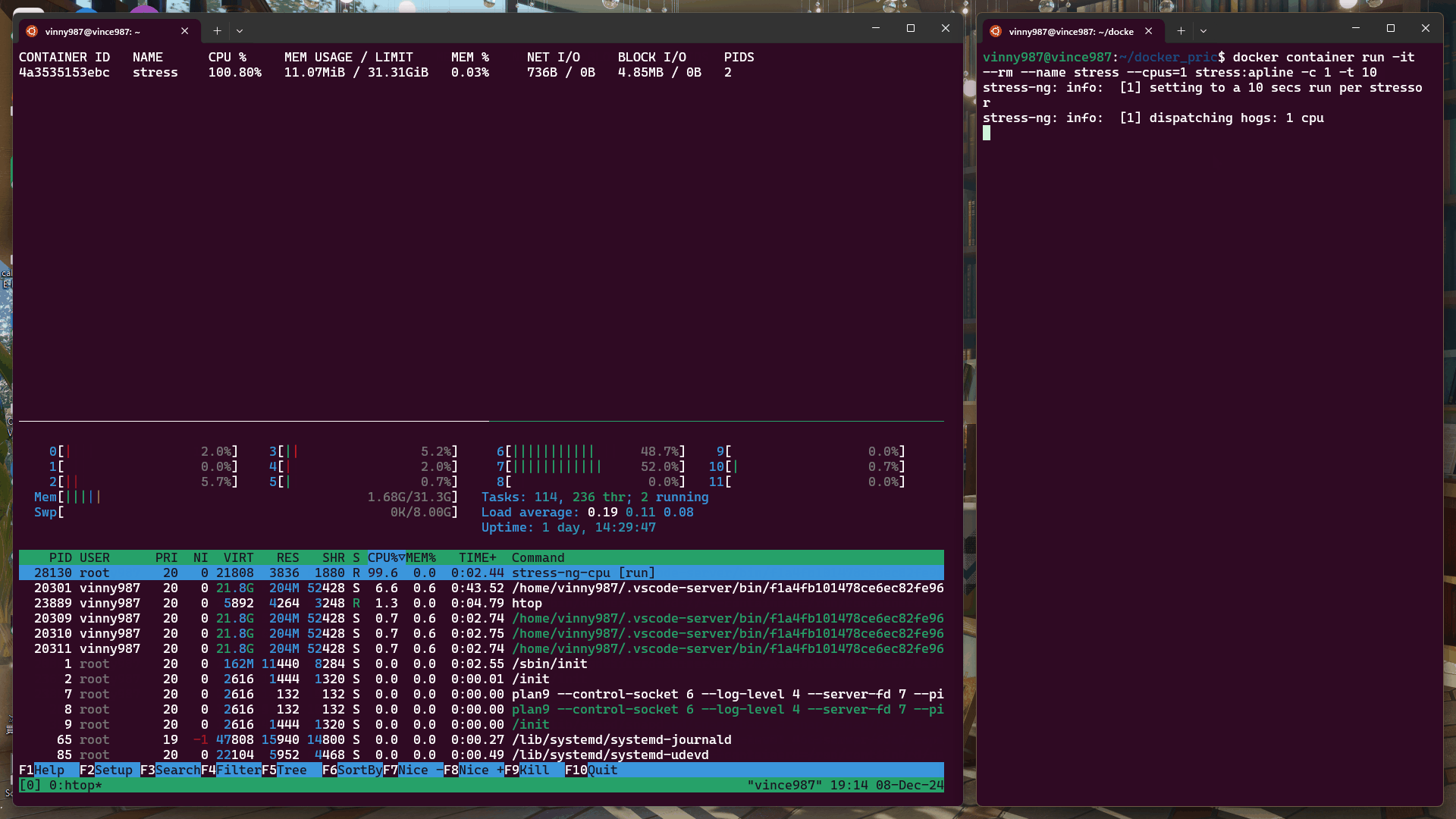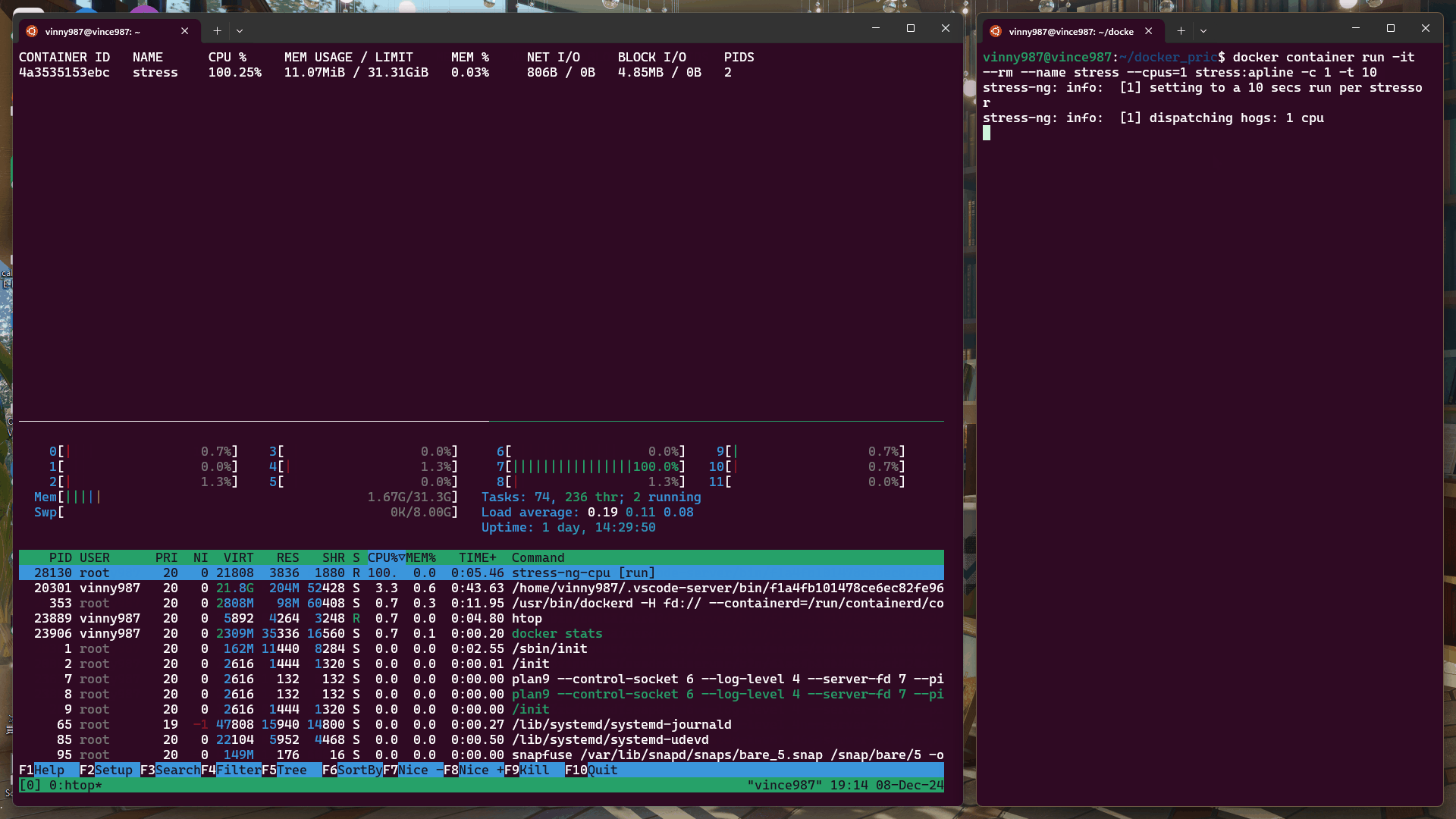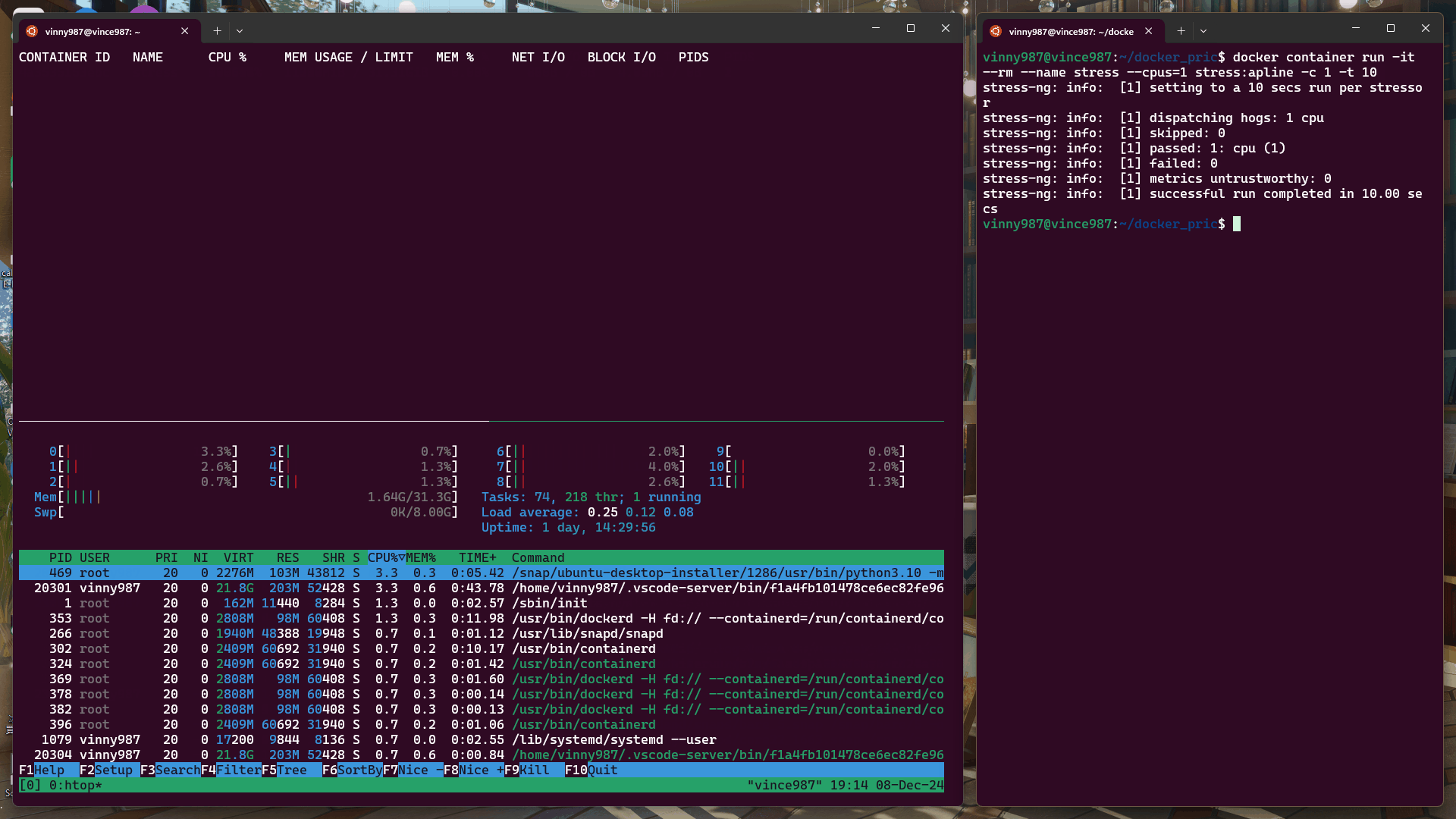
docker container run -it --rm --name stress --cpus=1 stress:alpine -c 1 -t 10
結果:
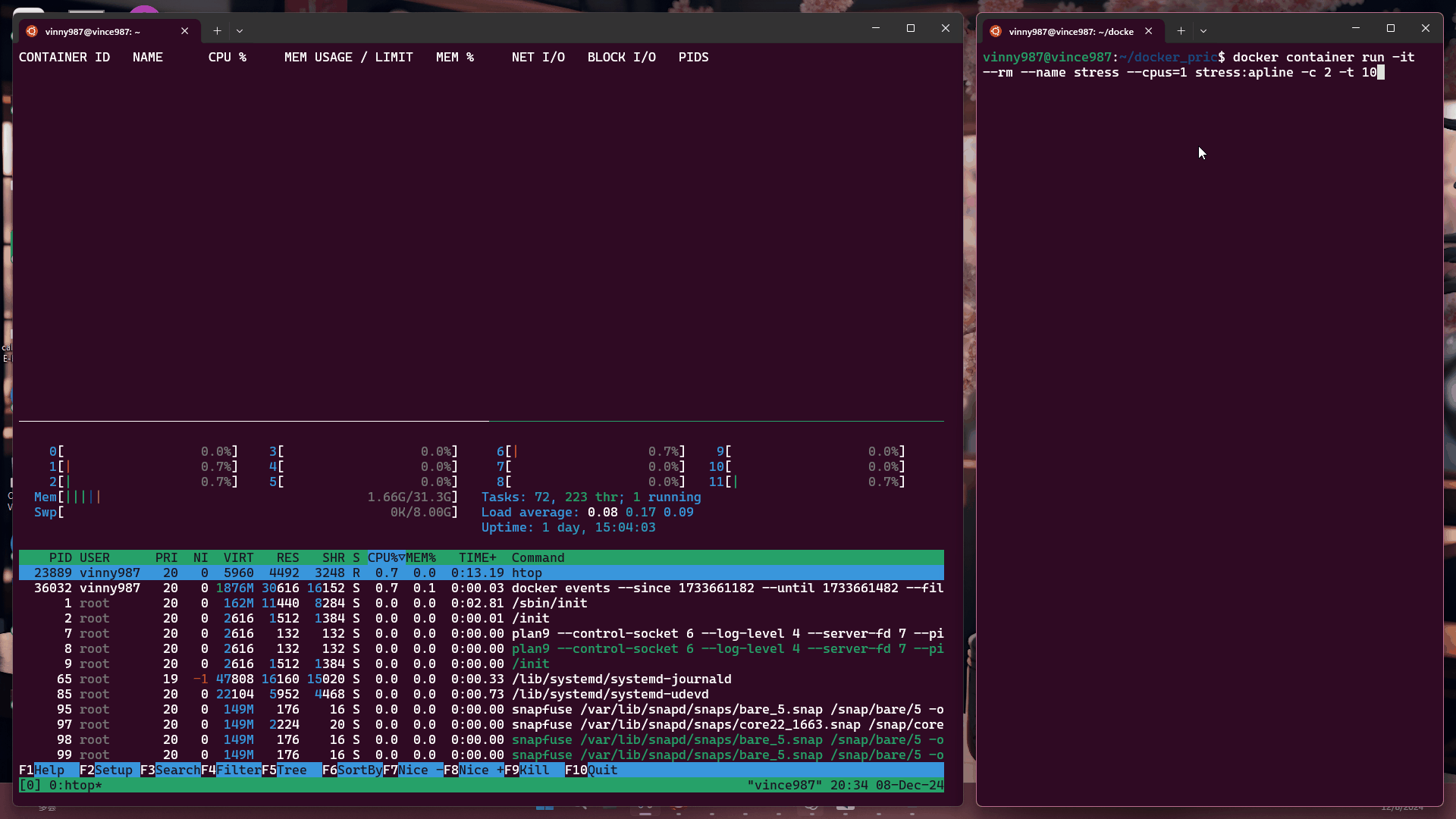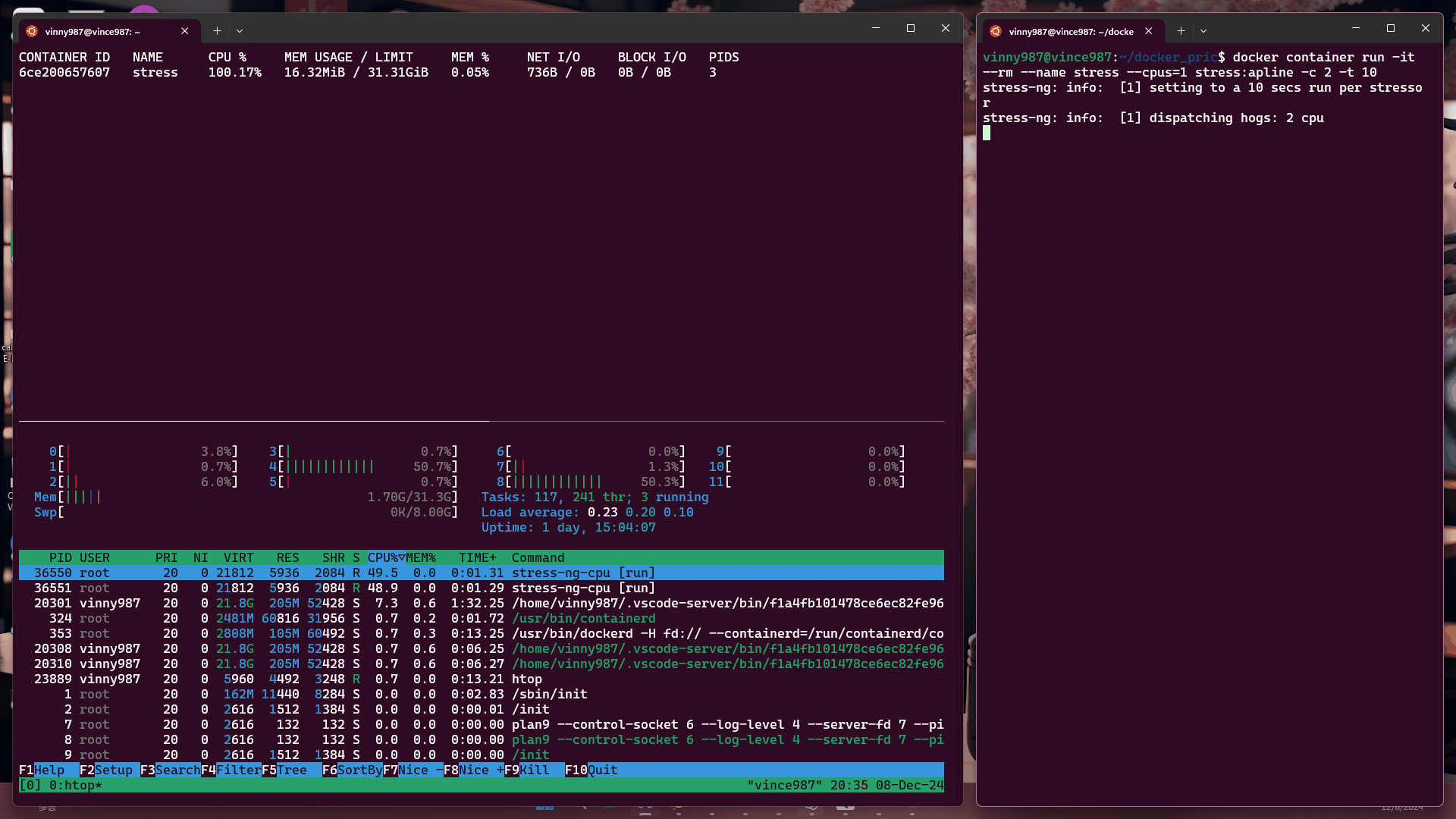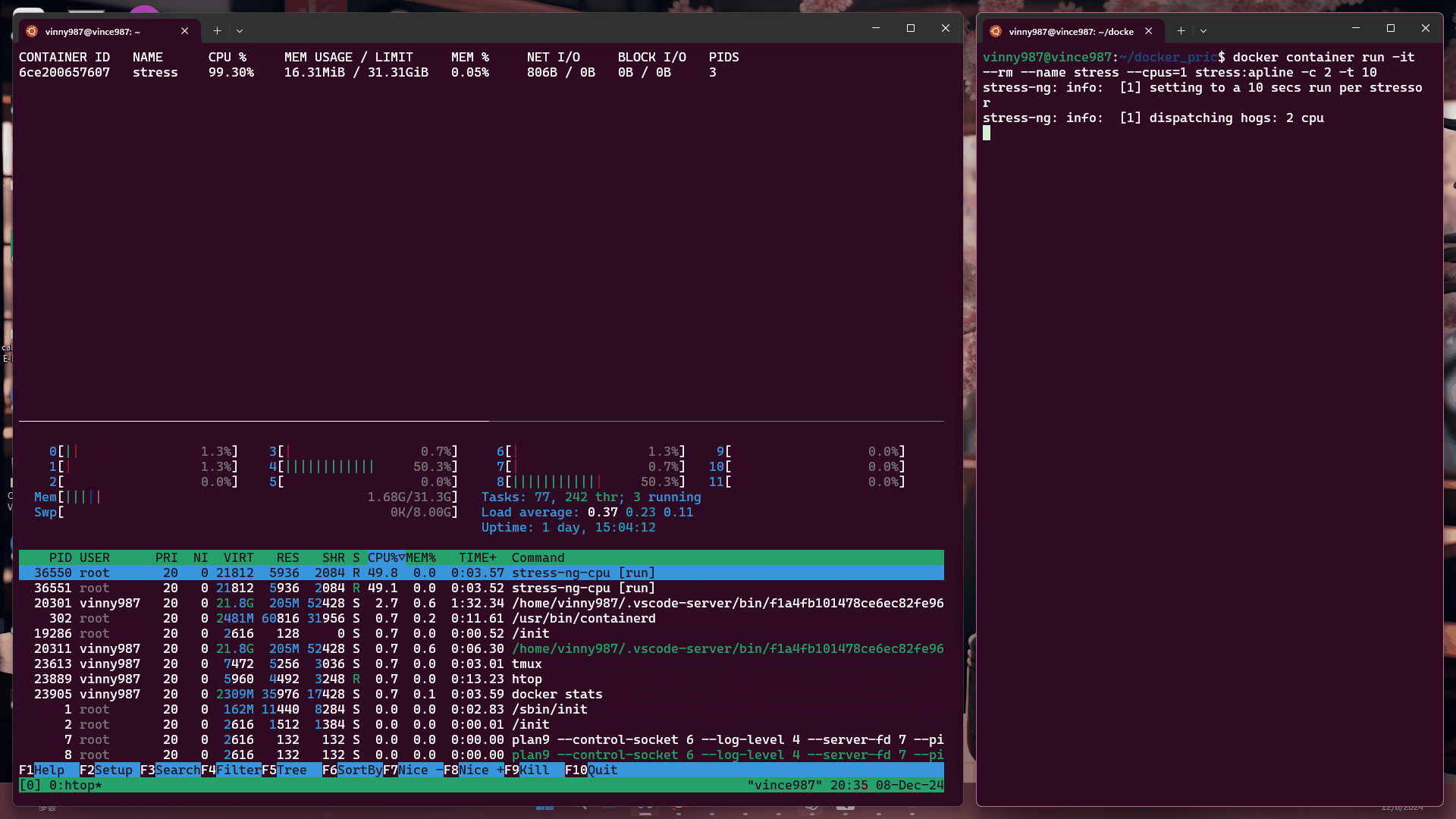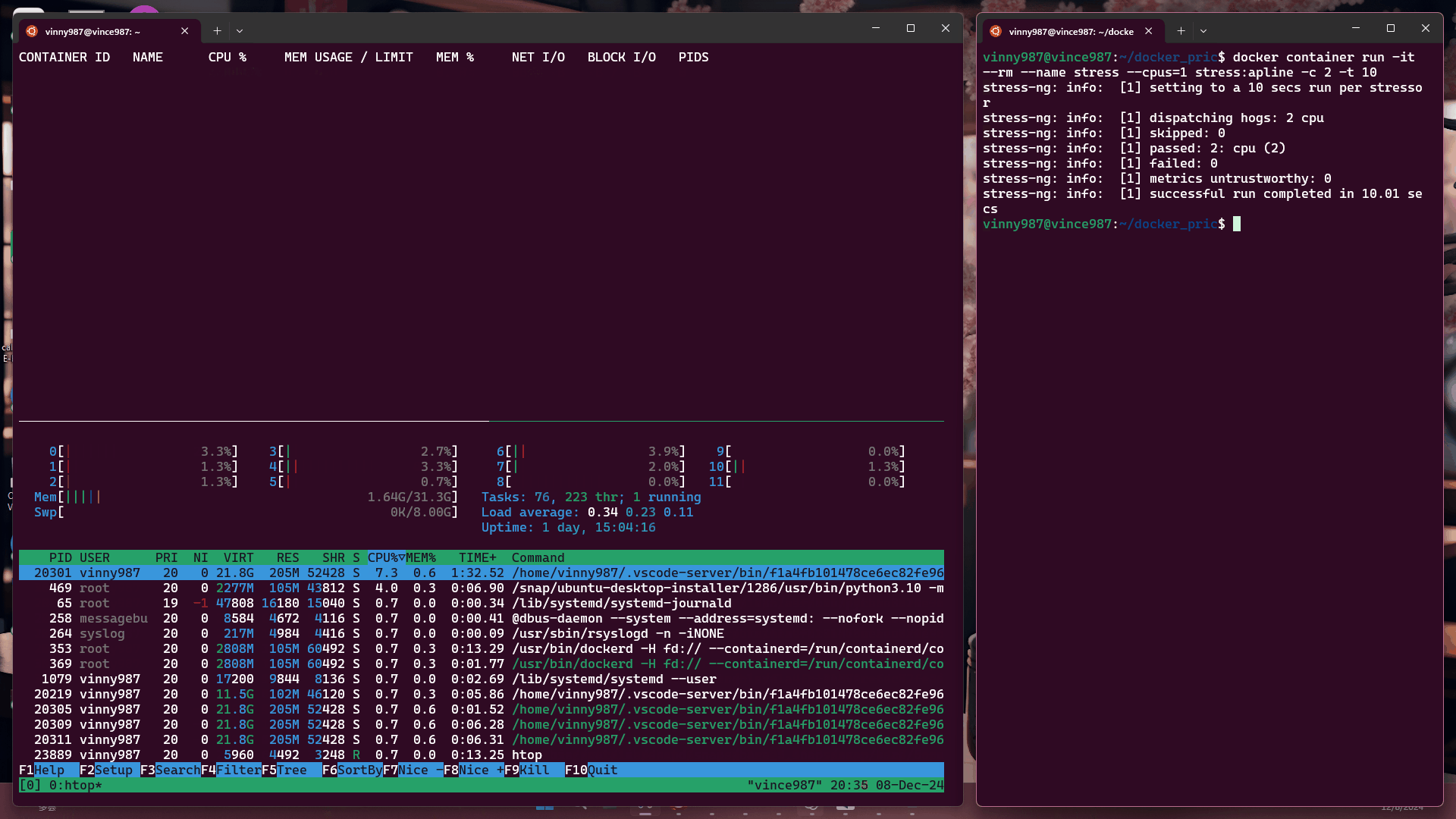
docker container run -it --rm --name stress --cpus=1 stress:alpine -c 2 -t 10
結果:
docker container run -it --rm --name stress --cpus=1.5 stress:alpine -c 2 -t 10
結果:
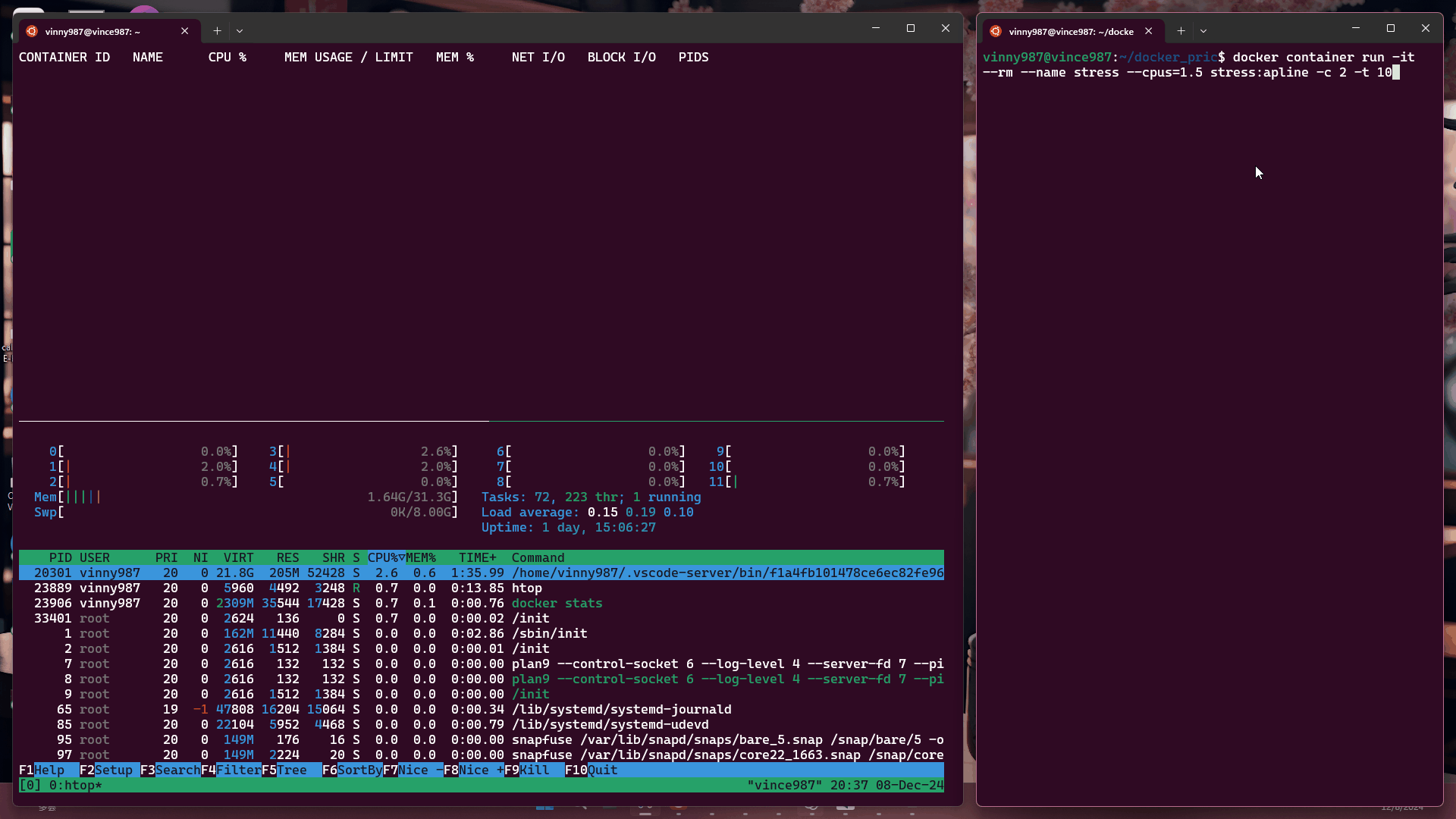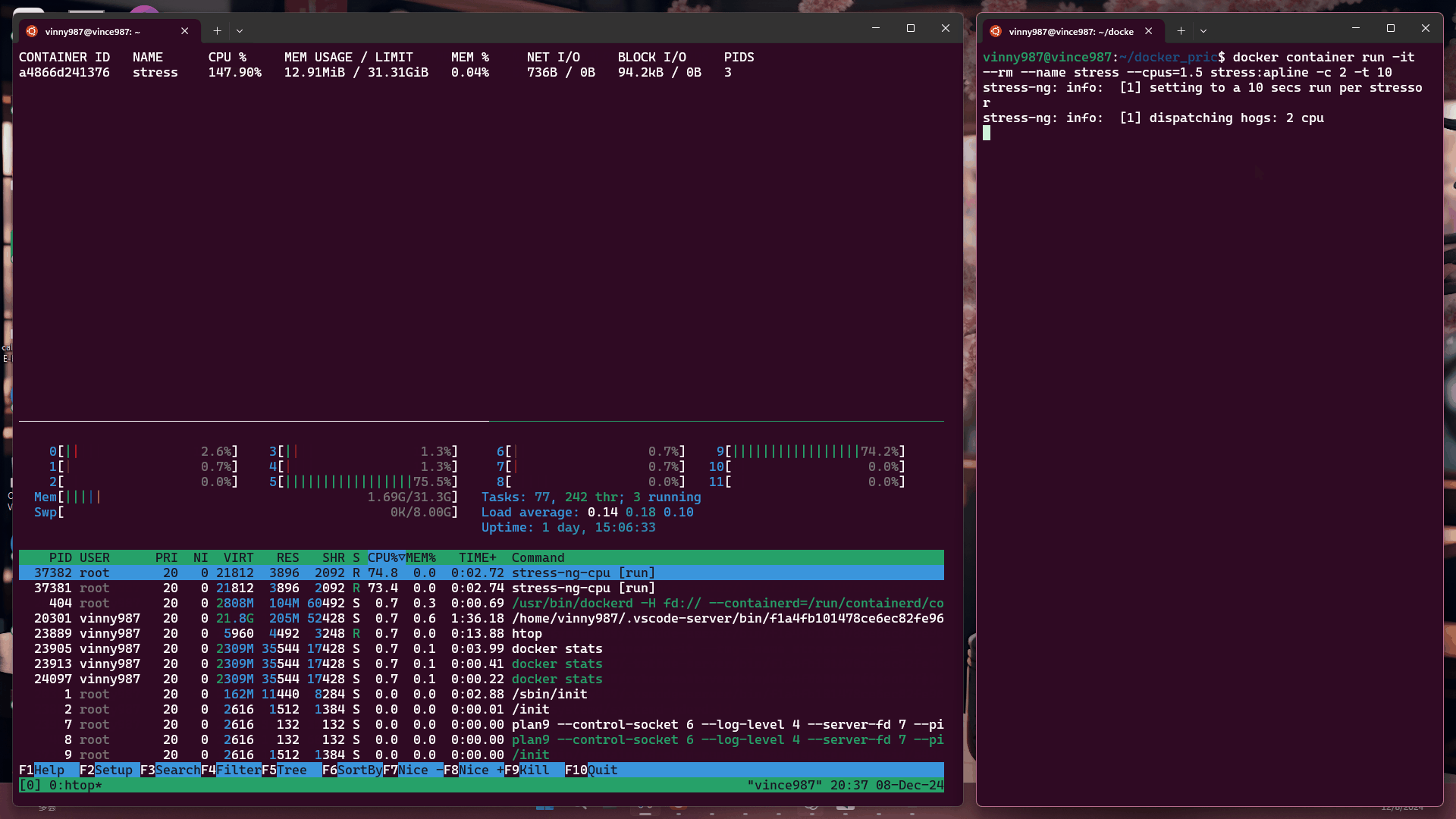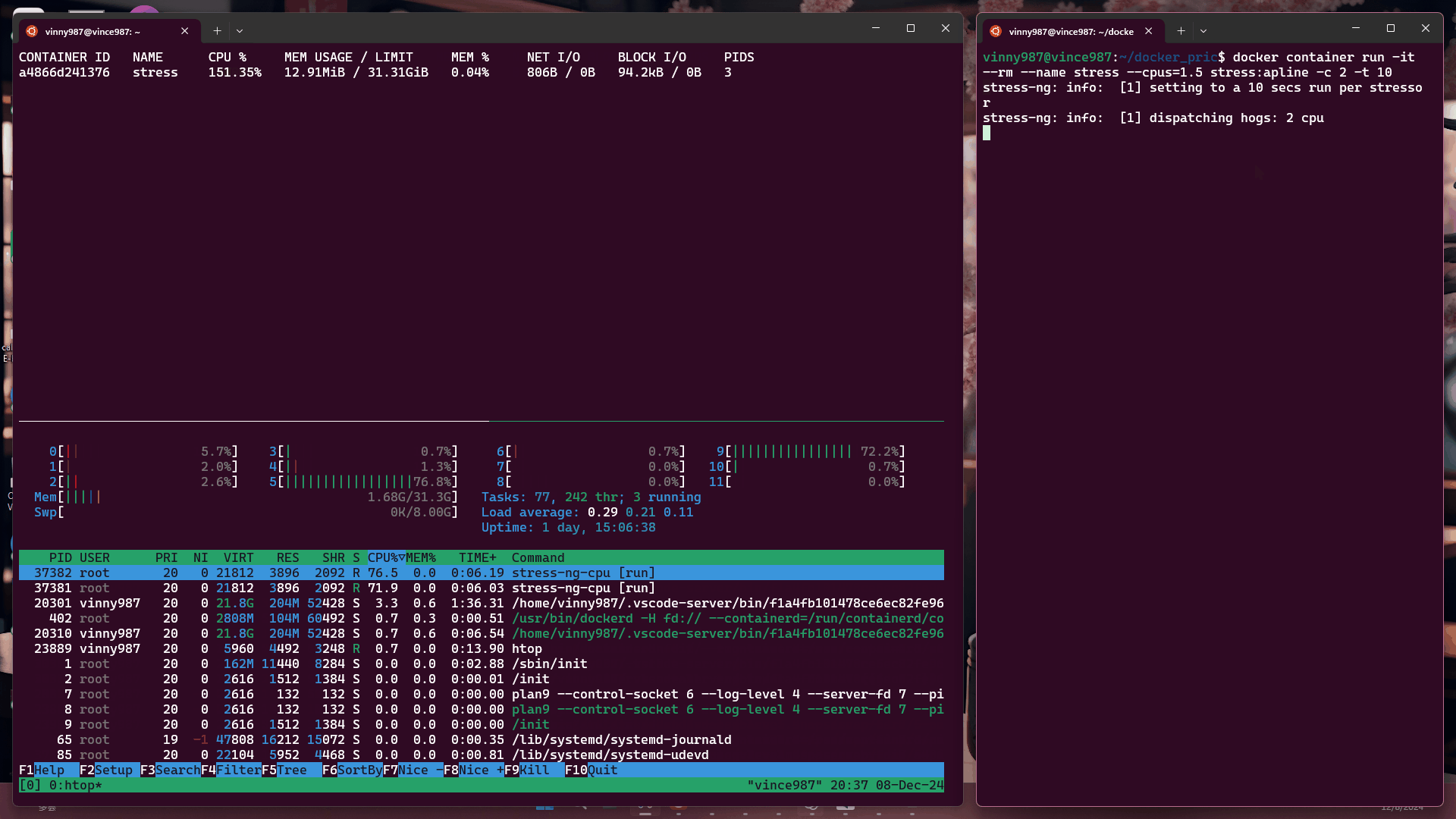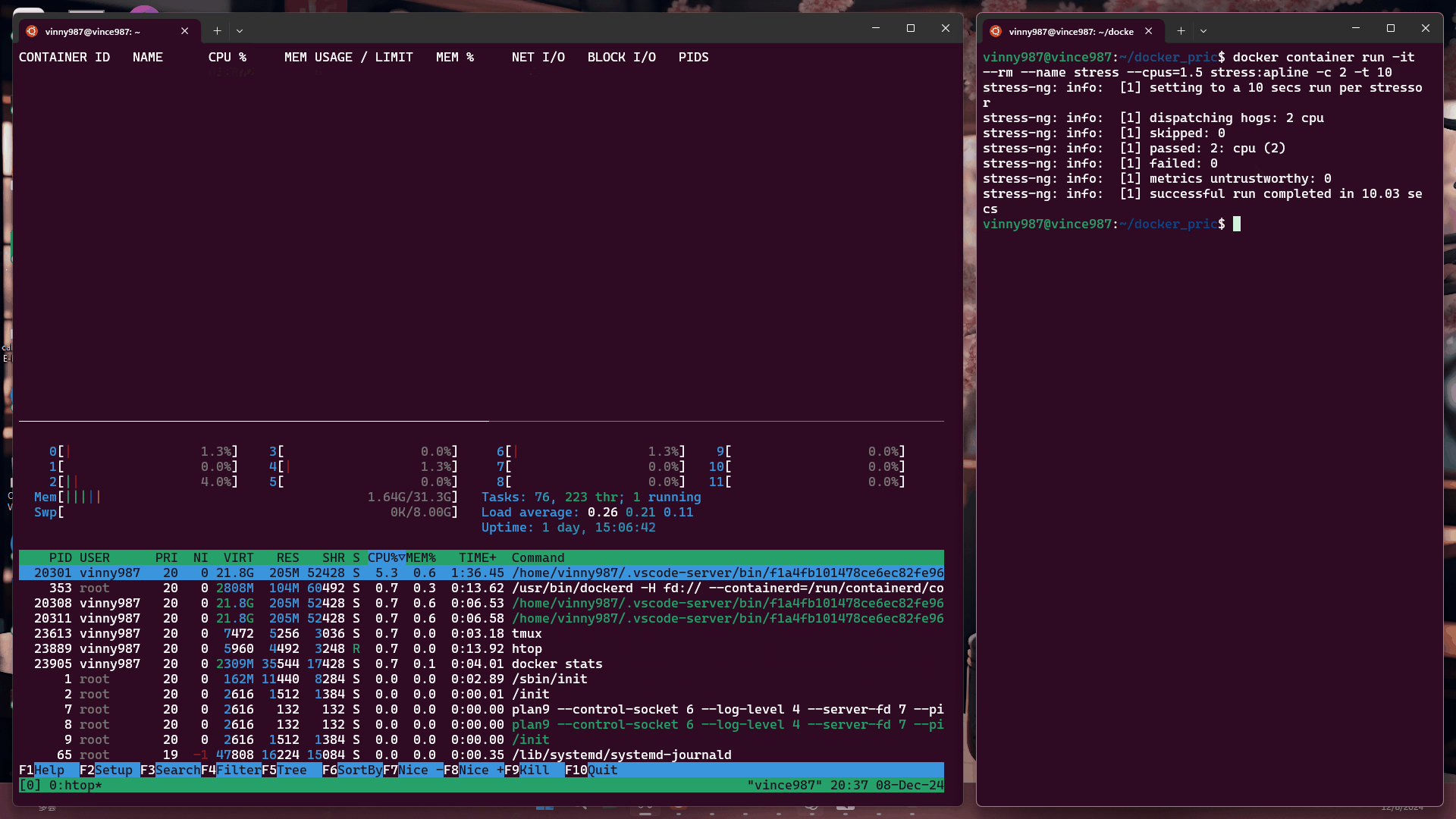
觀察結果:
即使壓力測試軟體將負載拉滿,基於 cgroup 的執行環境仍不能突破容器設置的資源限制。
在 CPU 資源限制中,容器執行時間由作業系統分配的運行時間決定。以下實驗旨在驗證這一點。
測試指令
time sh -c 'for i in $(seq 1 3000000); do :; done'
上述指令執行一個簡單的空迴圈,重複 3,000,000 次,並測量執行時間。
範例輸出:
real 0m0.882s
user 0m0.728s
sys 0m0.199s
real:實際運行時間(包含所有等待時間)。user:CPU 在用戶模式下執行的時間。sys:CPU 在核心模式下執行的時間(如 I/O 操作)。容器中執行測試
通過以下指令將測試整合至容器:
docker container run -it --rm --name stress --cpus=1 --entrypoint ash stress:alpine -c "time sh -c 'for i in \$(seq 1 3000000); do :; done'"
--cpus=1在限制為 1 個 CPU 的容器中執行上述指令:
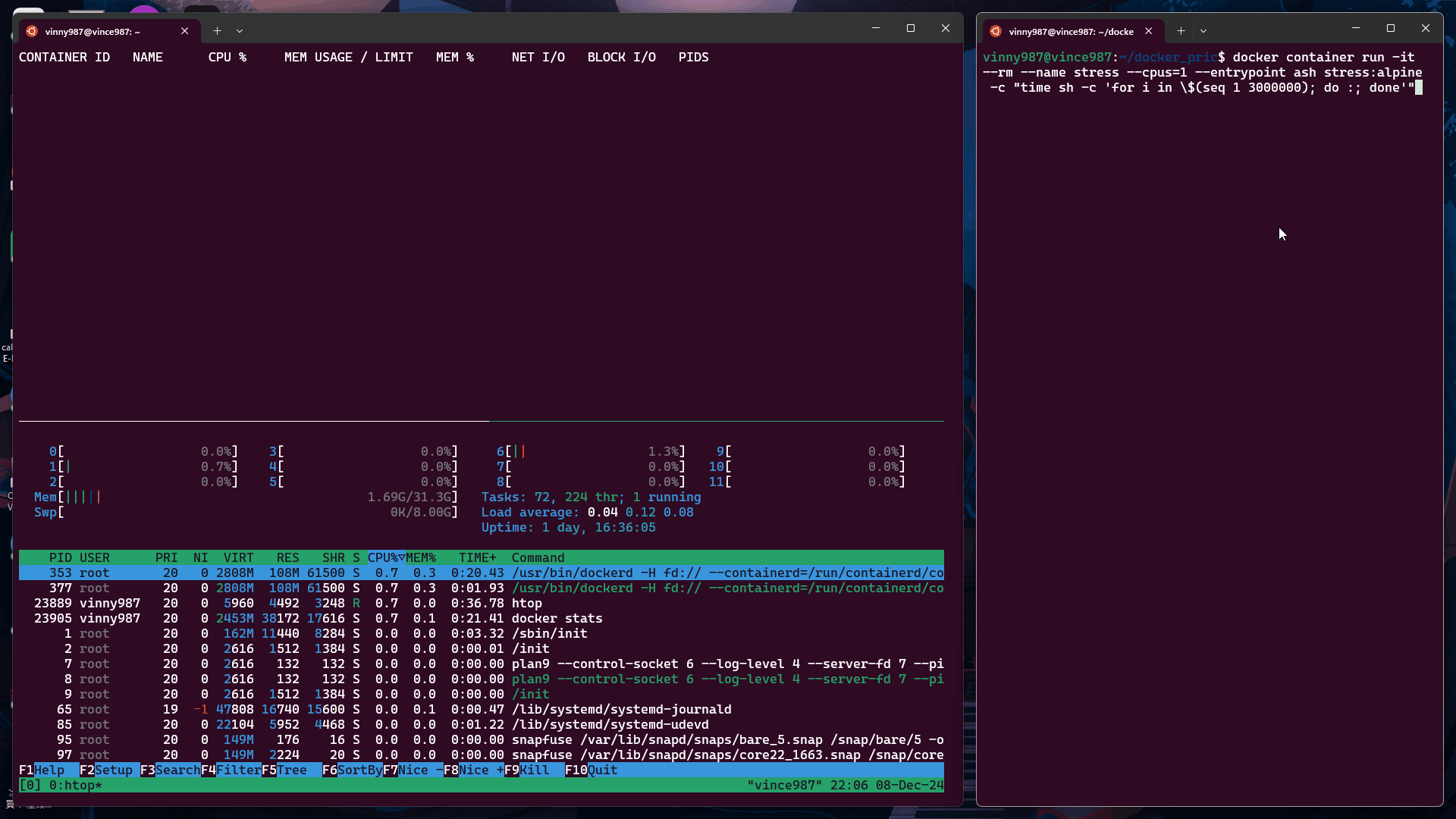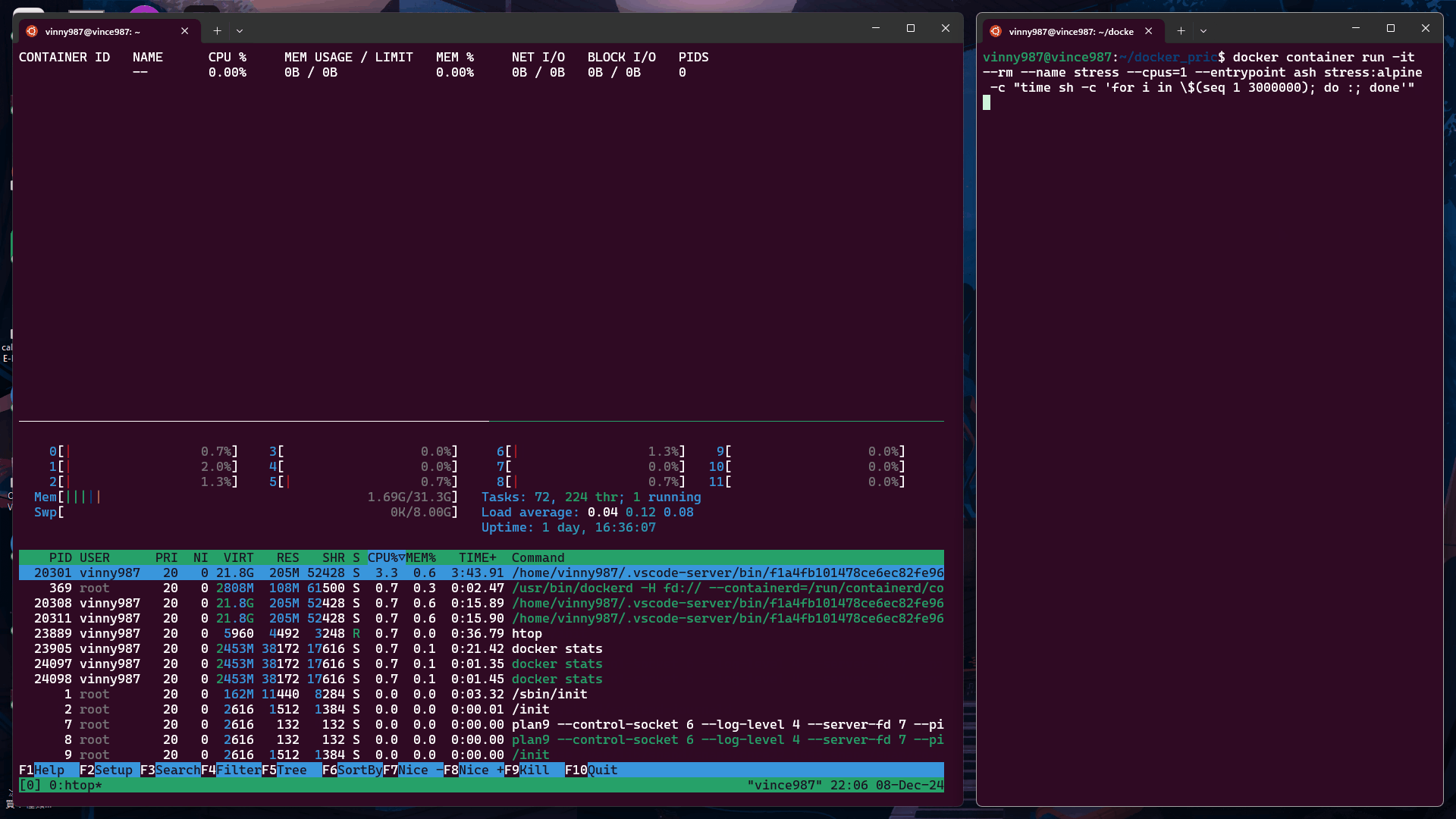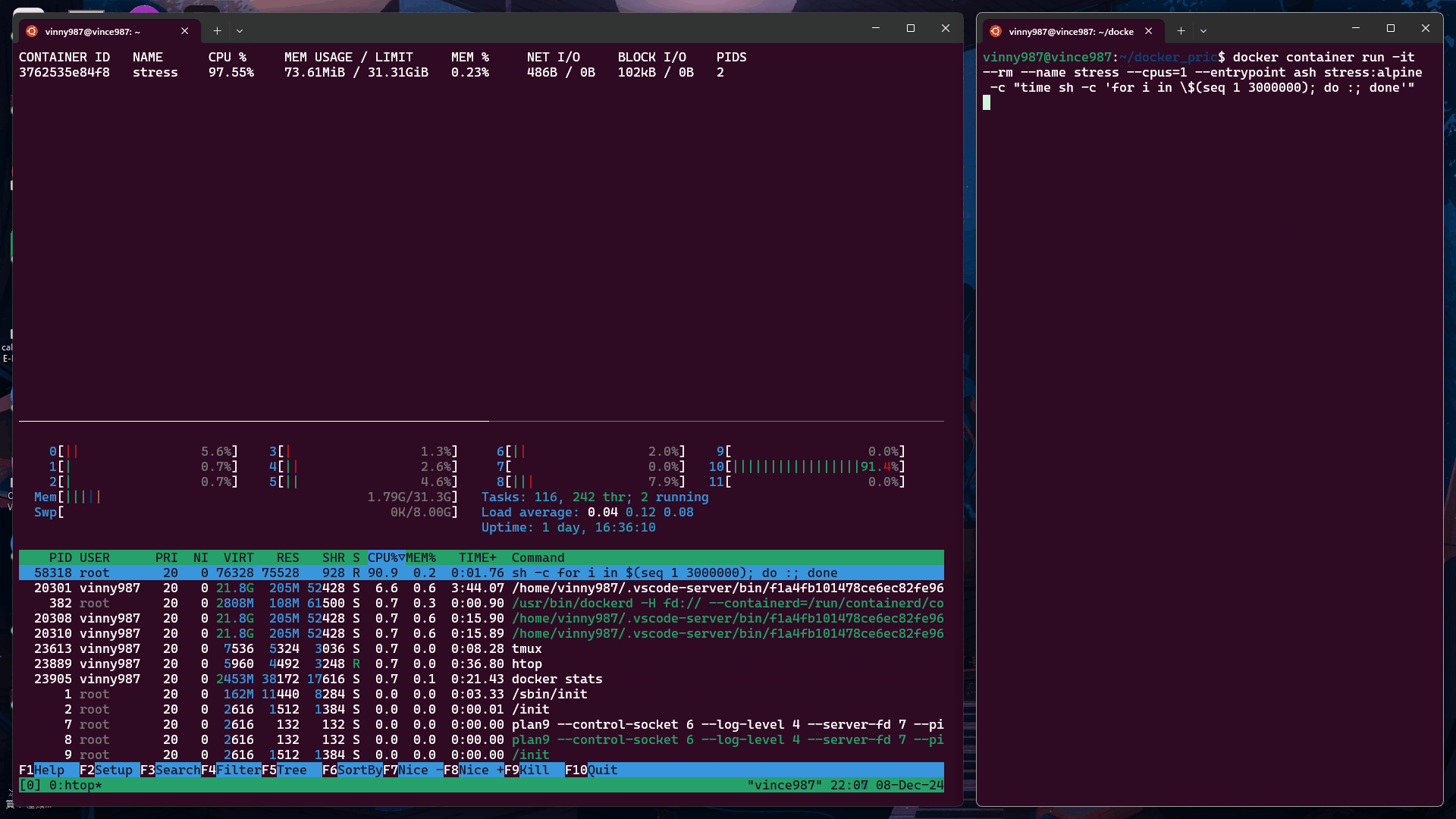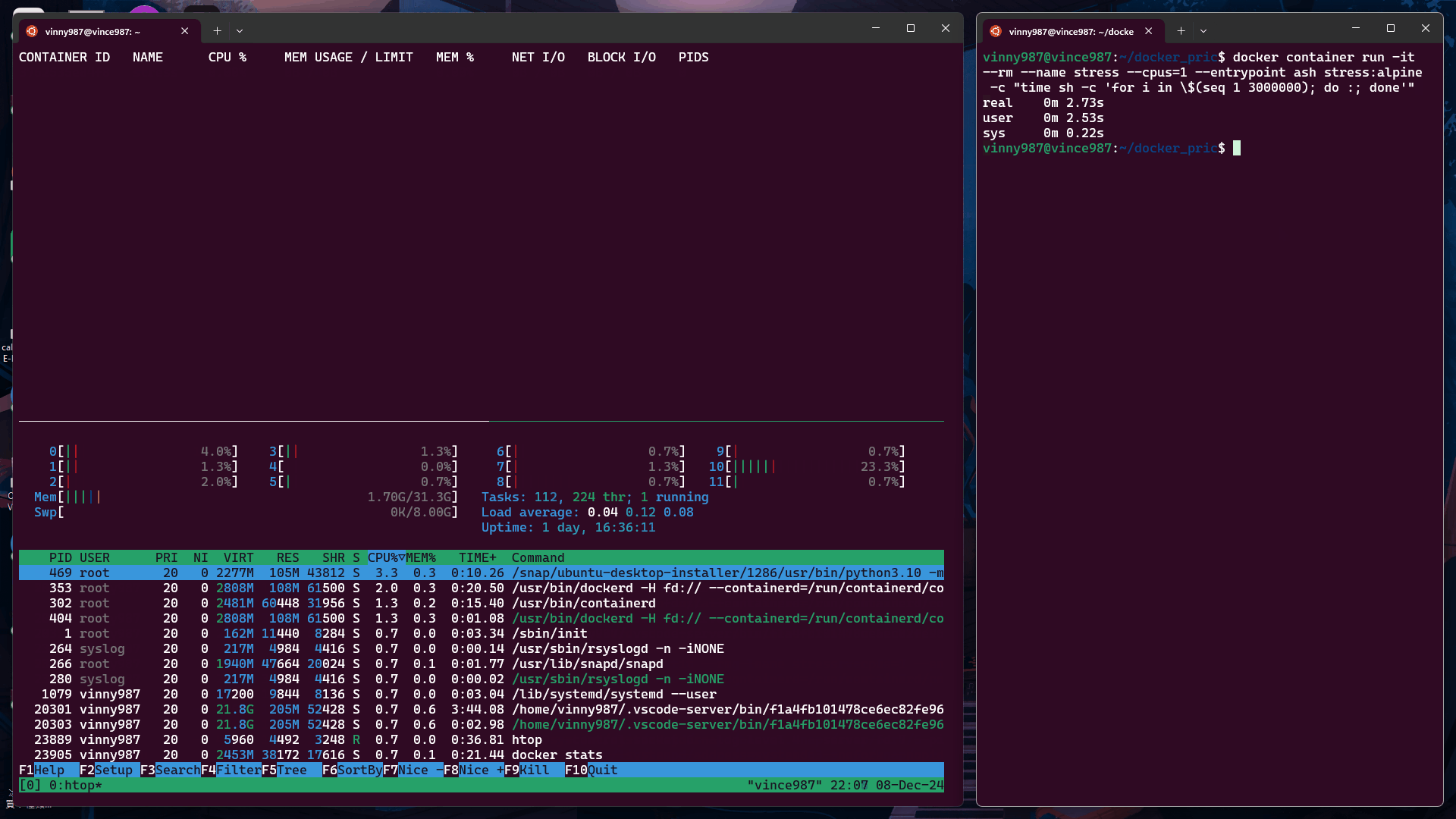
--cpus=0.5在限制為 0.5 個 CPU 的容器中執行:
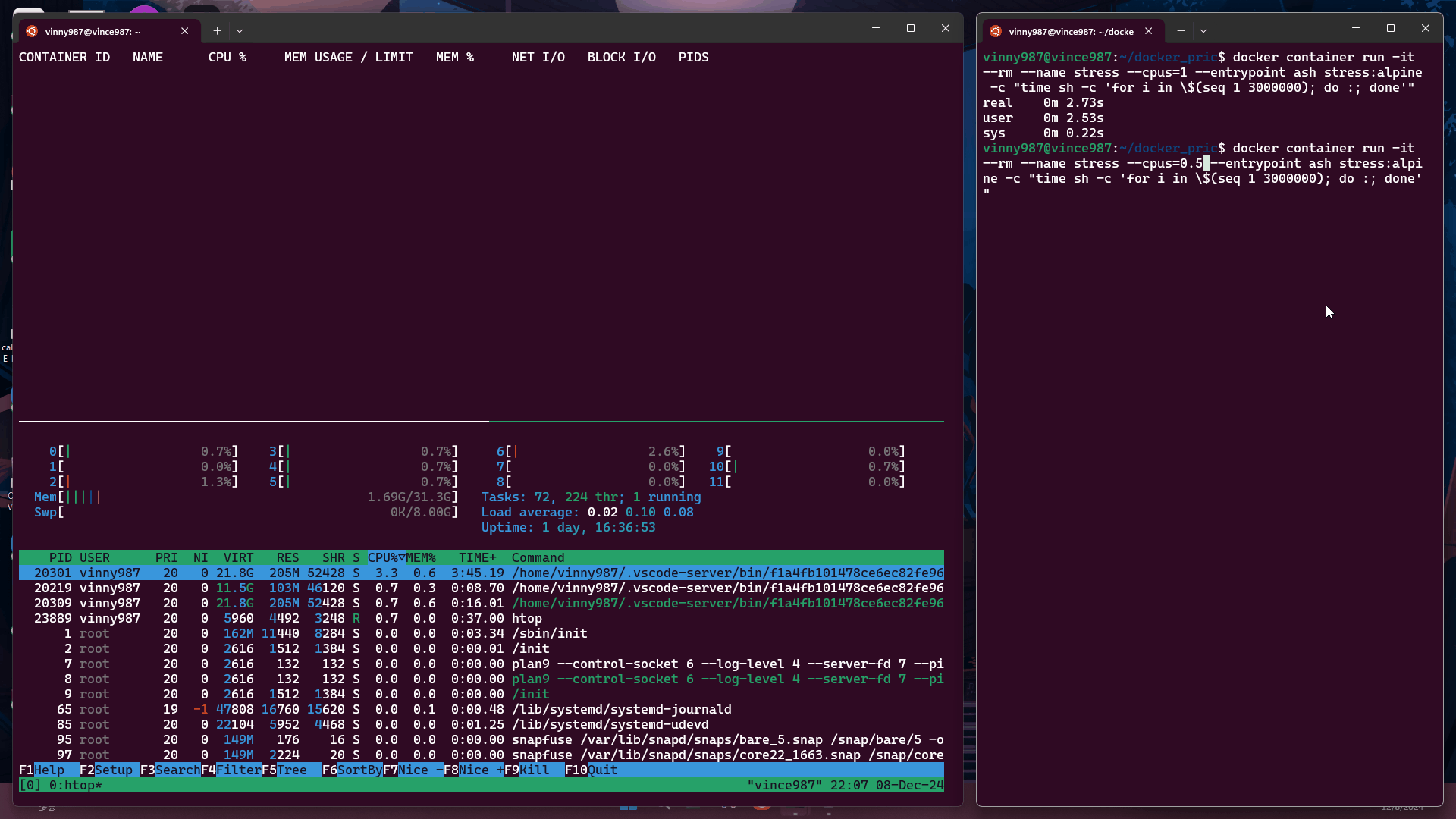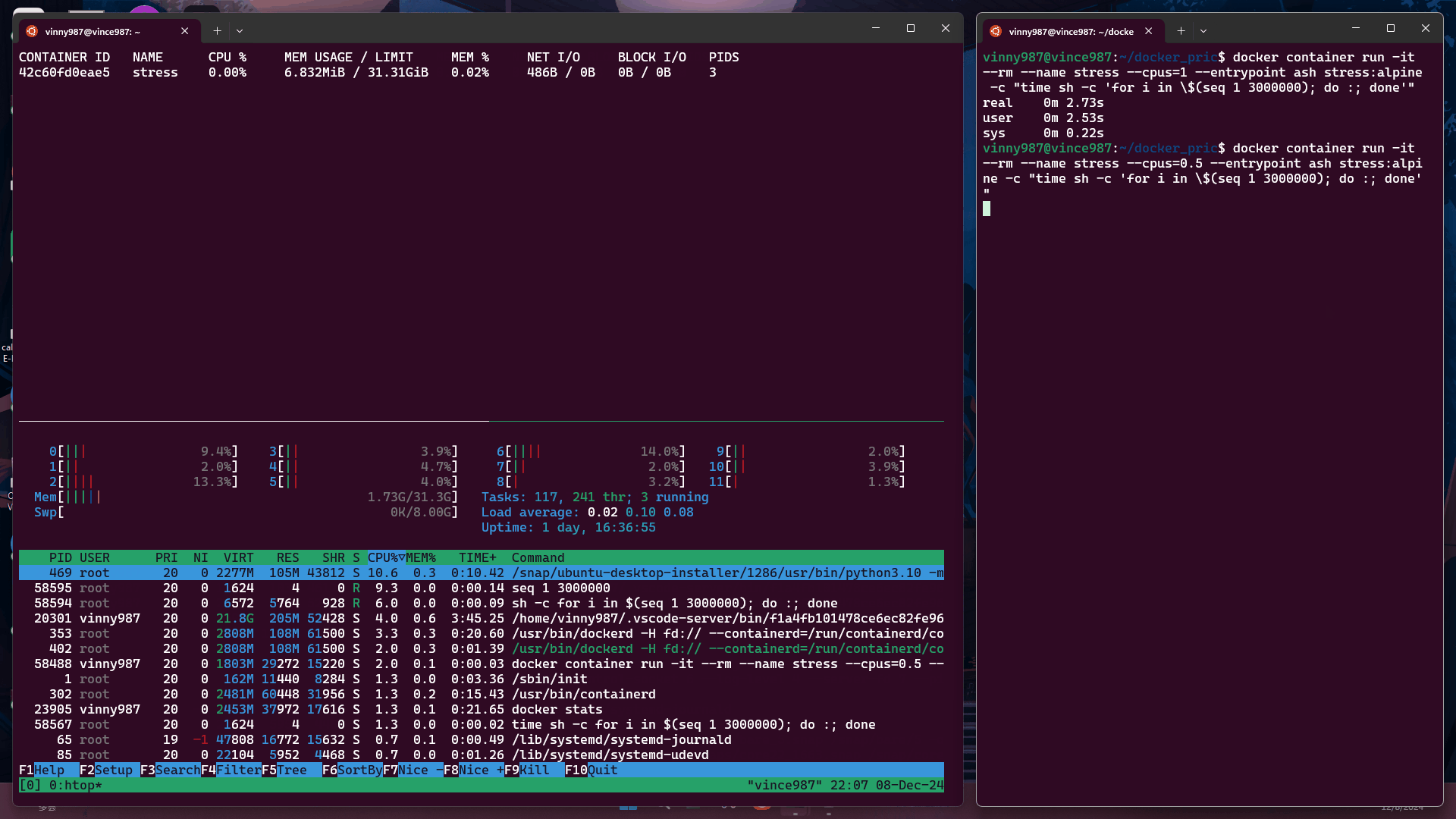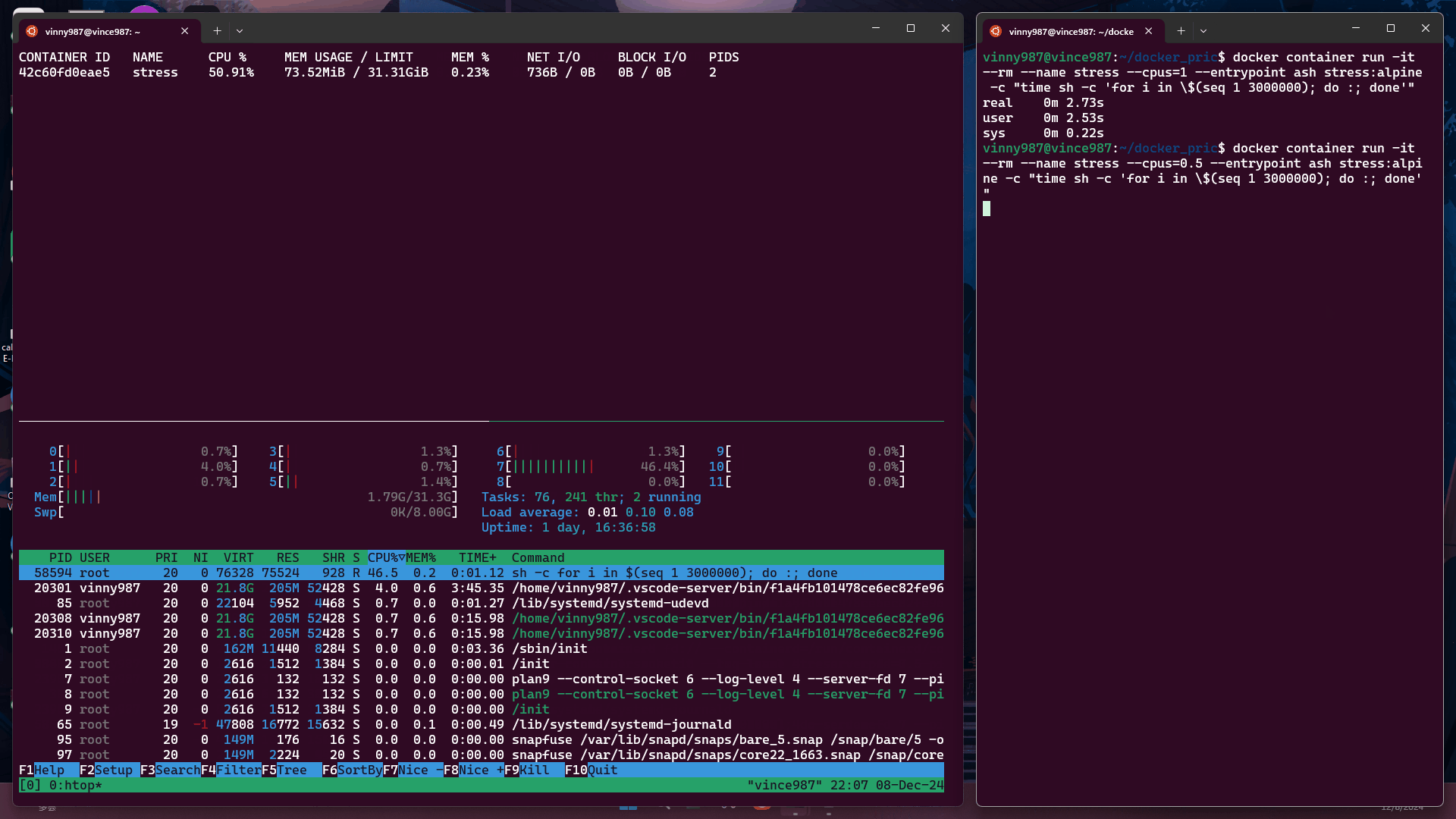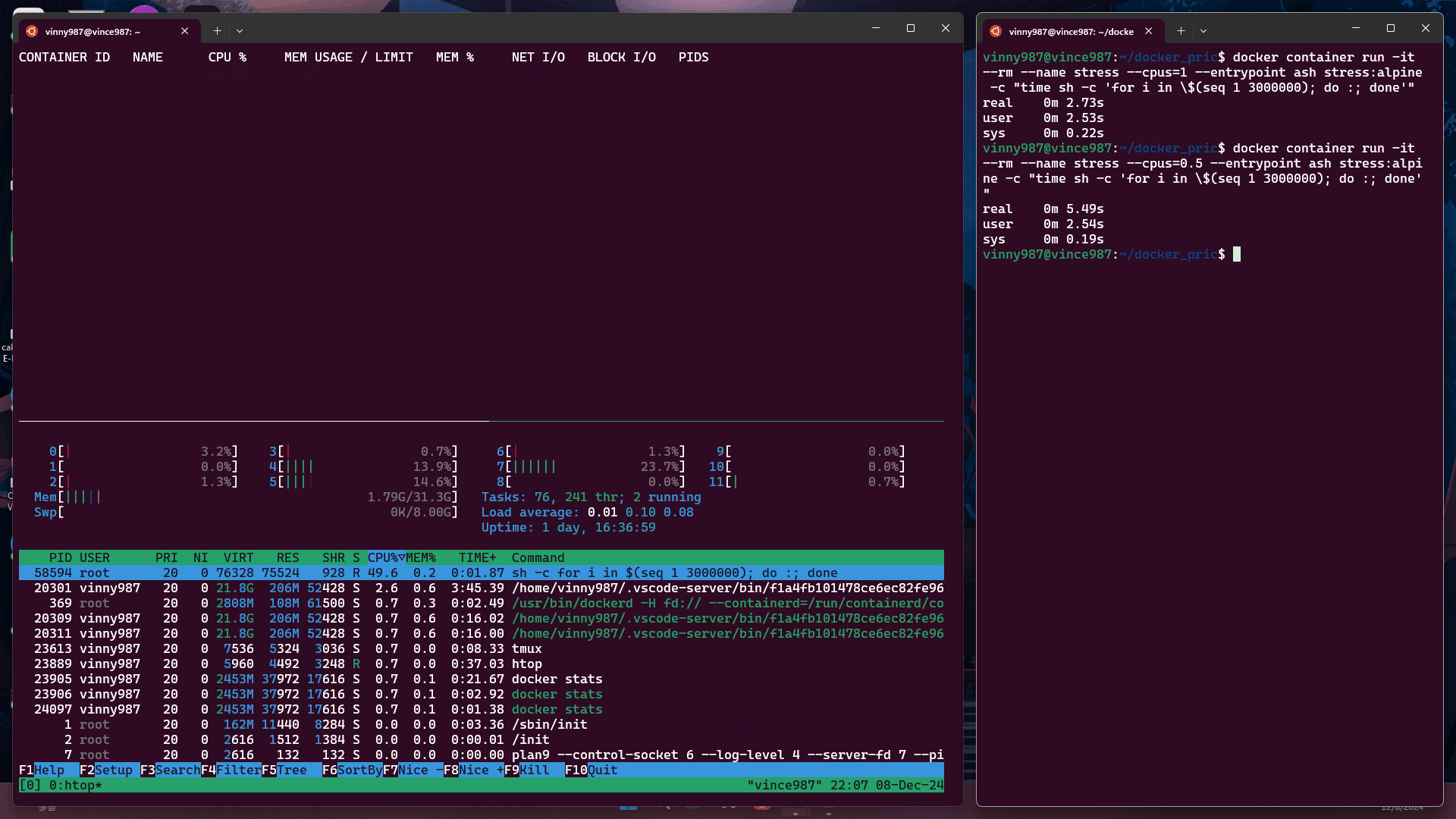
結論:
cgroup 使用 cpu-share 來決定 CPU 資源的分配權重。通過 Docker 提供的 --cpu-shares 參數,我們可以調整容器的資源權重。
測試指令
docker container run -it --rm --name stress --cpu-shares=256 stress:alpine
若未指定 --cpu-shares,容器的預設值為 1024。這是一個相對權重,與其他容器的 cpu-share 比例共同決定 CPU 分配。
資源分配公式
當系統資源不足時,cpu-share 決定了 CPU 分配的比例:
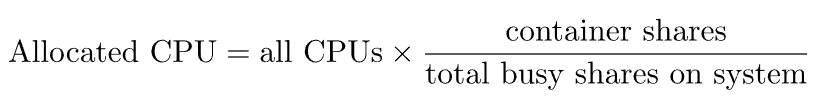
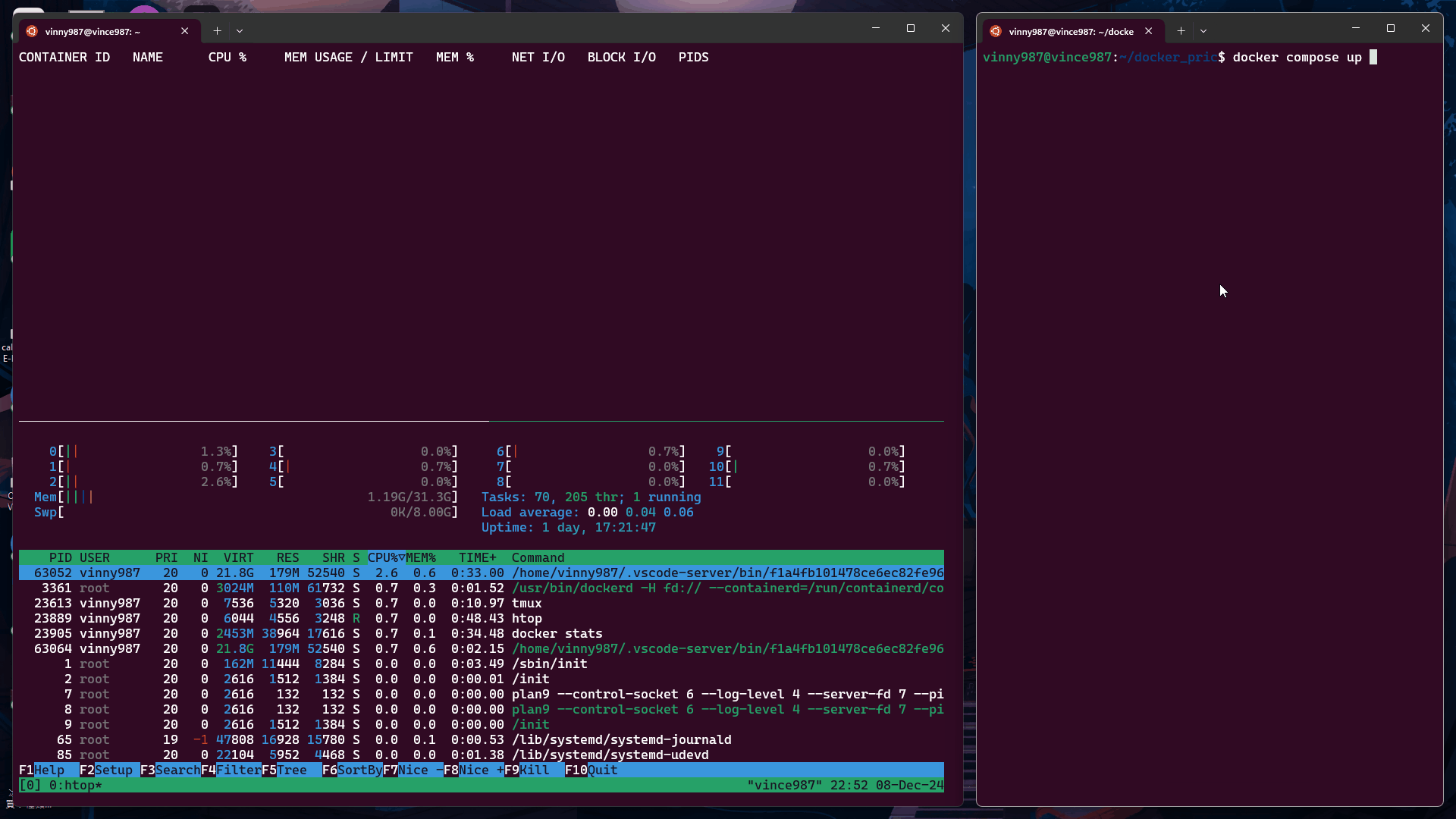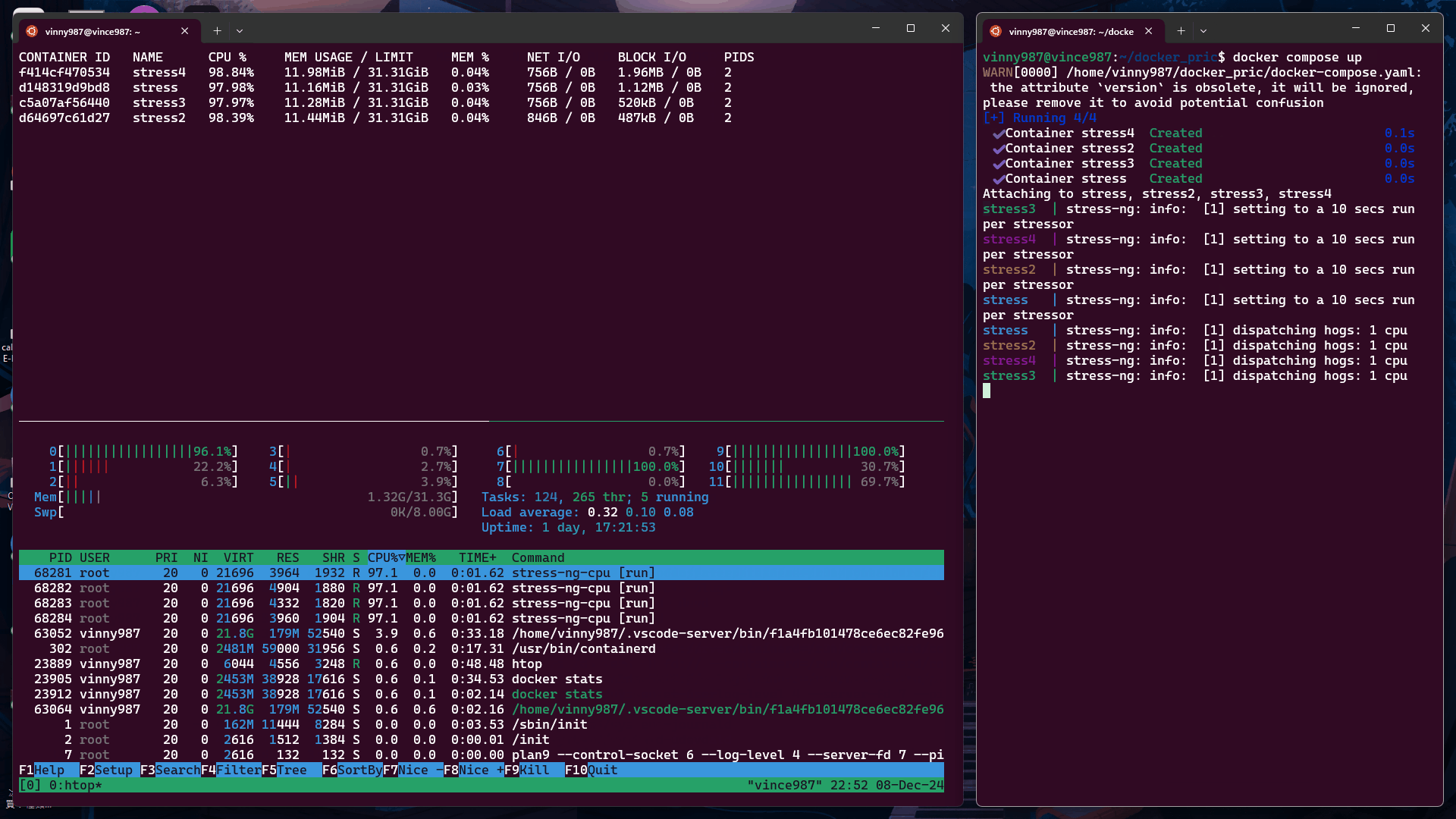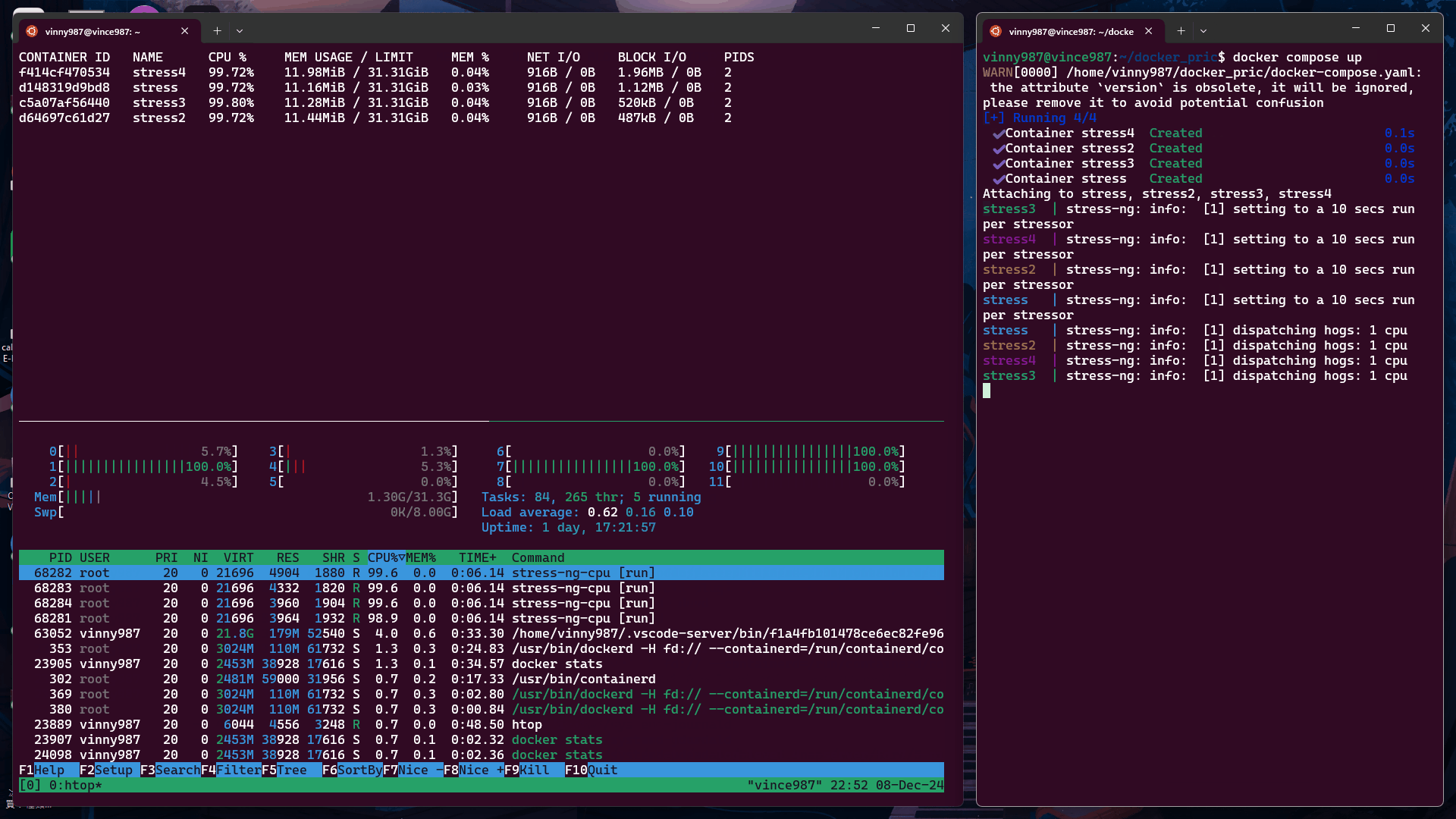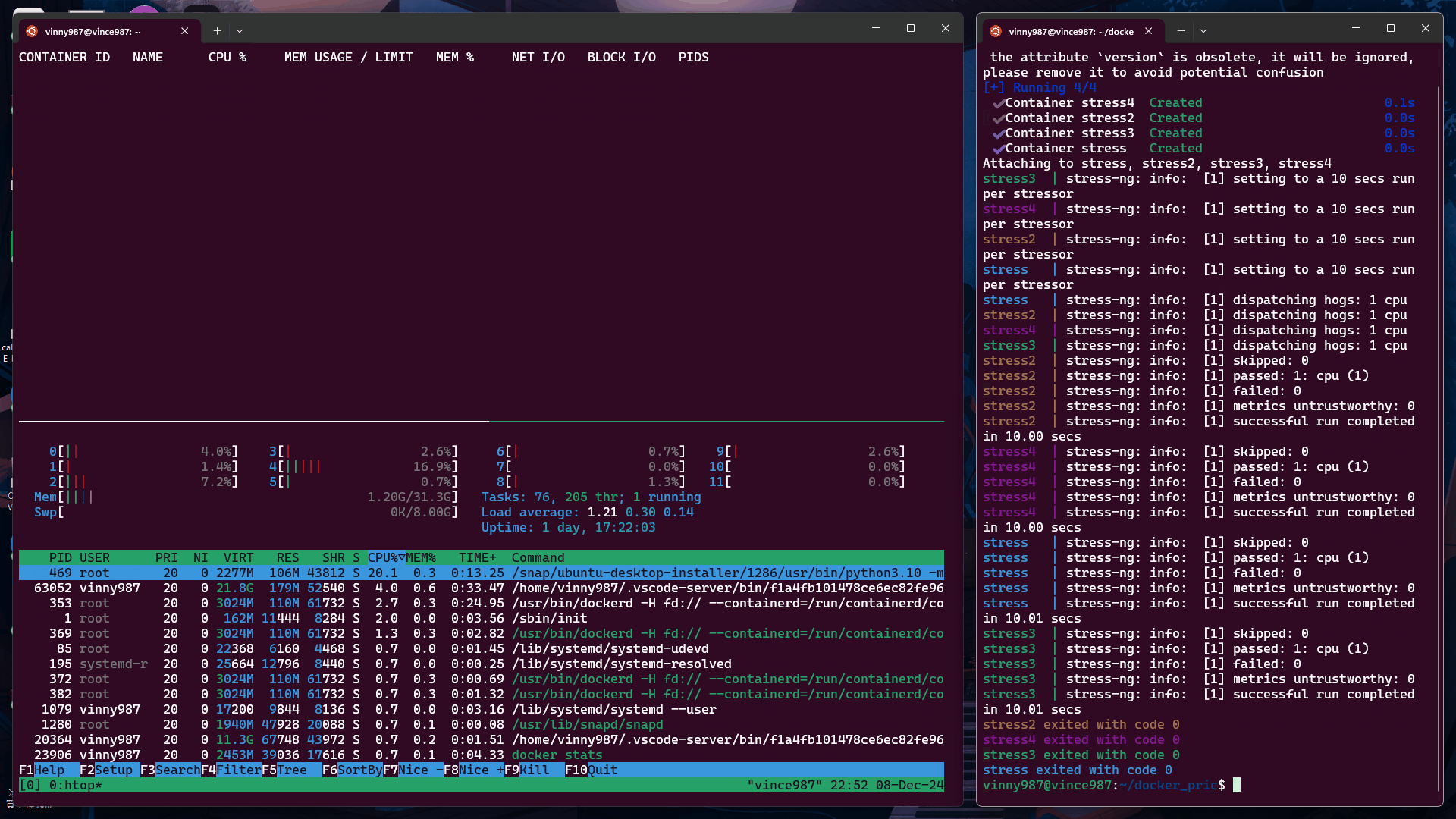
docker-compose.yml
version: '2'
services:
stress:
image: stress:alpine
container_name: stress
command: ["-c", "1", "-t", "10"]
cpu_shares: 256
stress2:
image: stress:alpine
container_name: stress2
command: ["-c", "1", "-t", "10"]
cpu_shares: 512
stress3:
image: stress:alpine
container_name: stress3
command: ["-c", "1", "-t", "10"]
cpu_shares: 768
stress4:
image: stress:alpine
container_name: stress4
command: ["-c", "1", "-t", "10"]
cpu_shares: 1024
執行結果:
在資源充足時,權重對容器的 CPU 使用沒有影響。
在 Windows Host 的 %UserProfile%\.wslconfig 文件中添加以下配置:
[wsl2]
memory=4GB
processors=2

再次執行 測試 1 中的 docker-compose.yml,觀察結果:
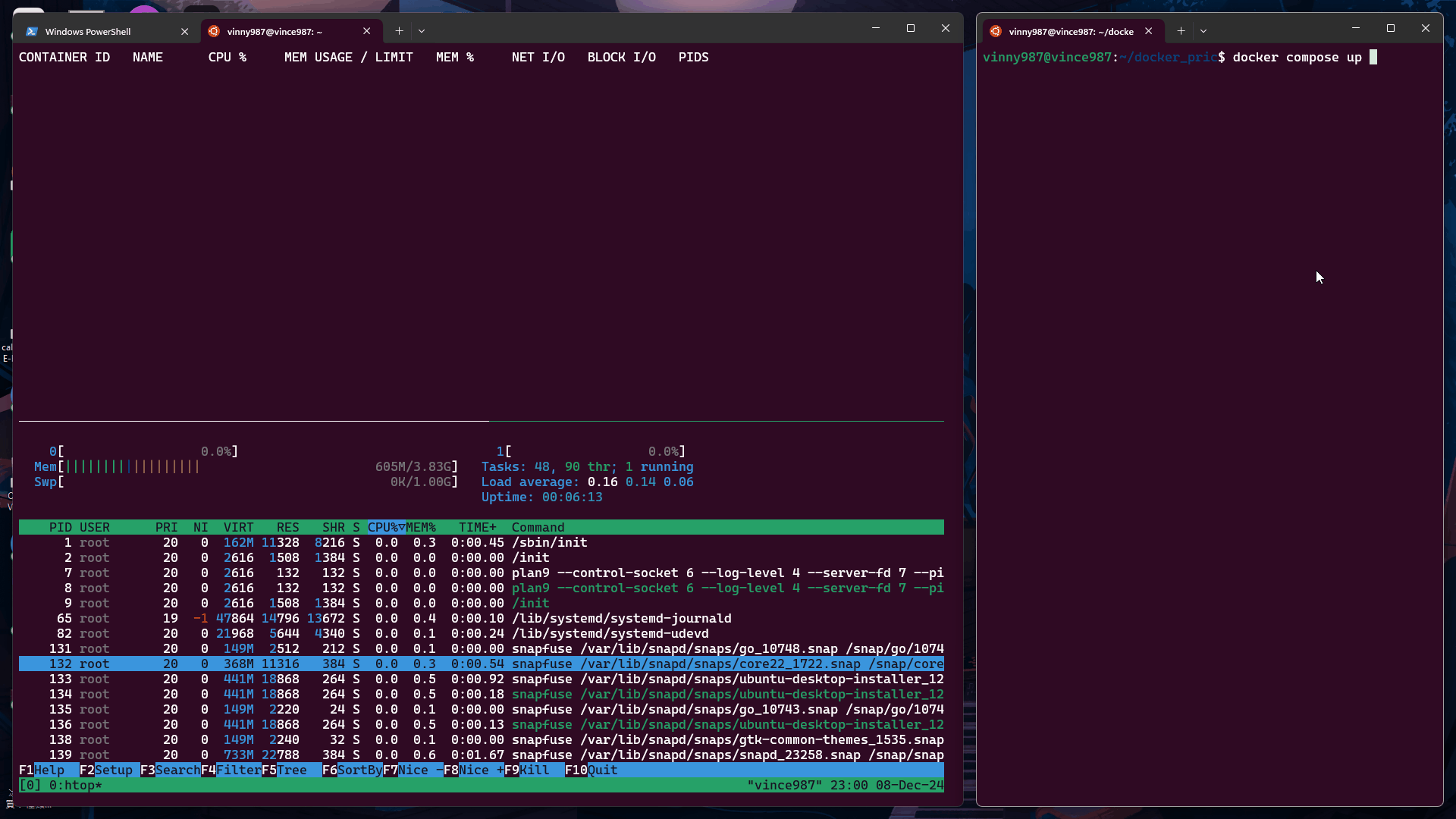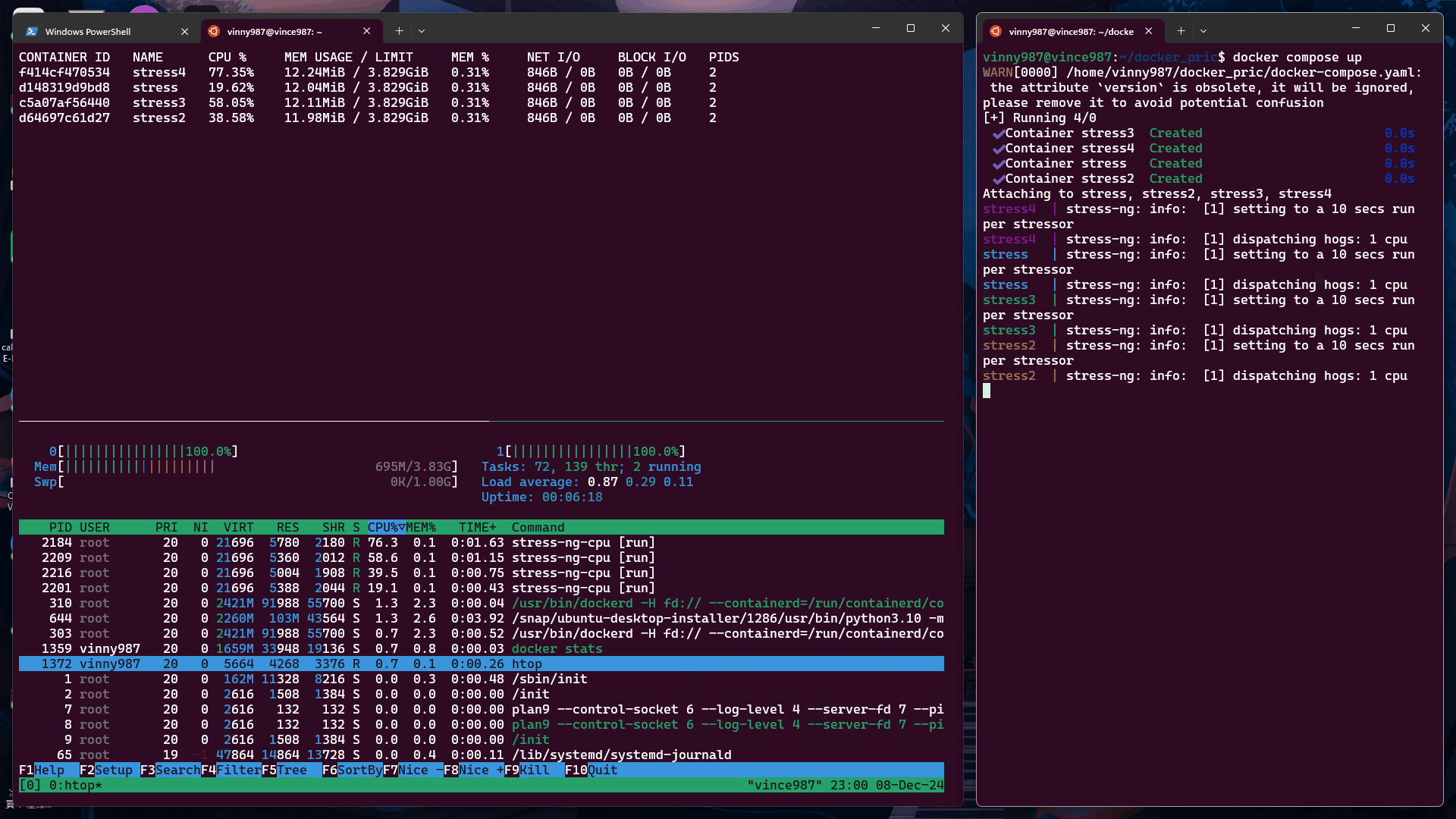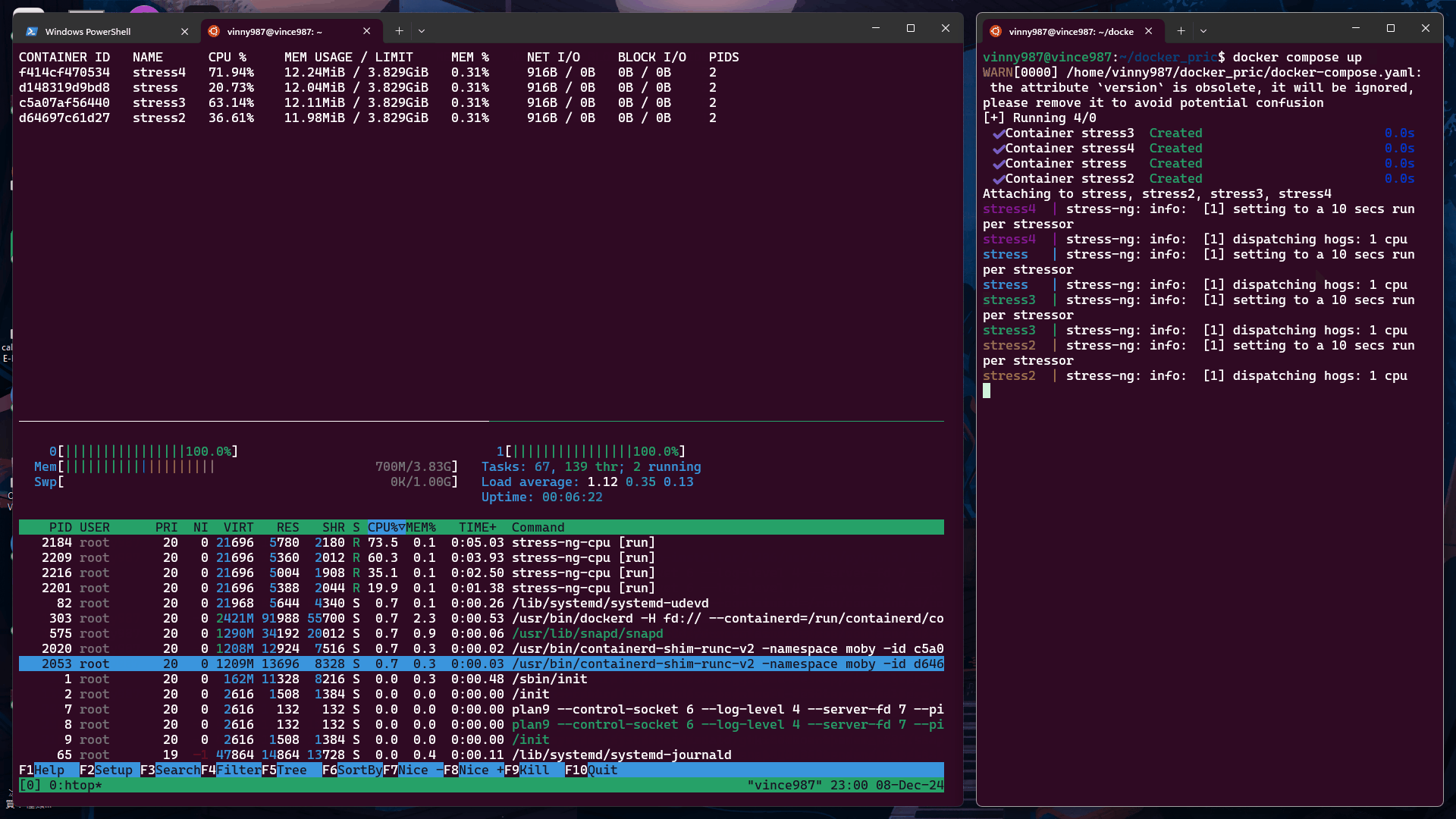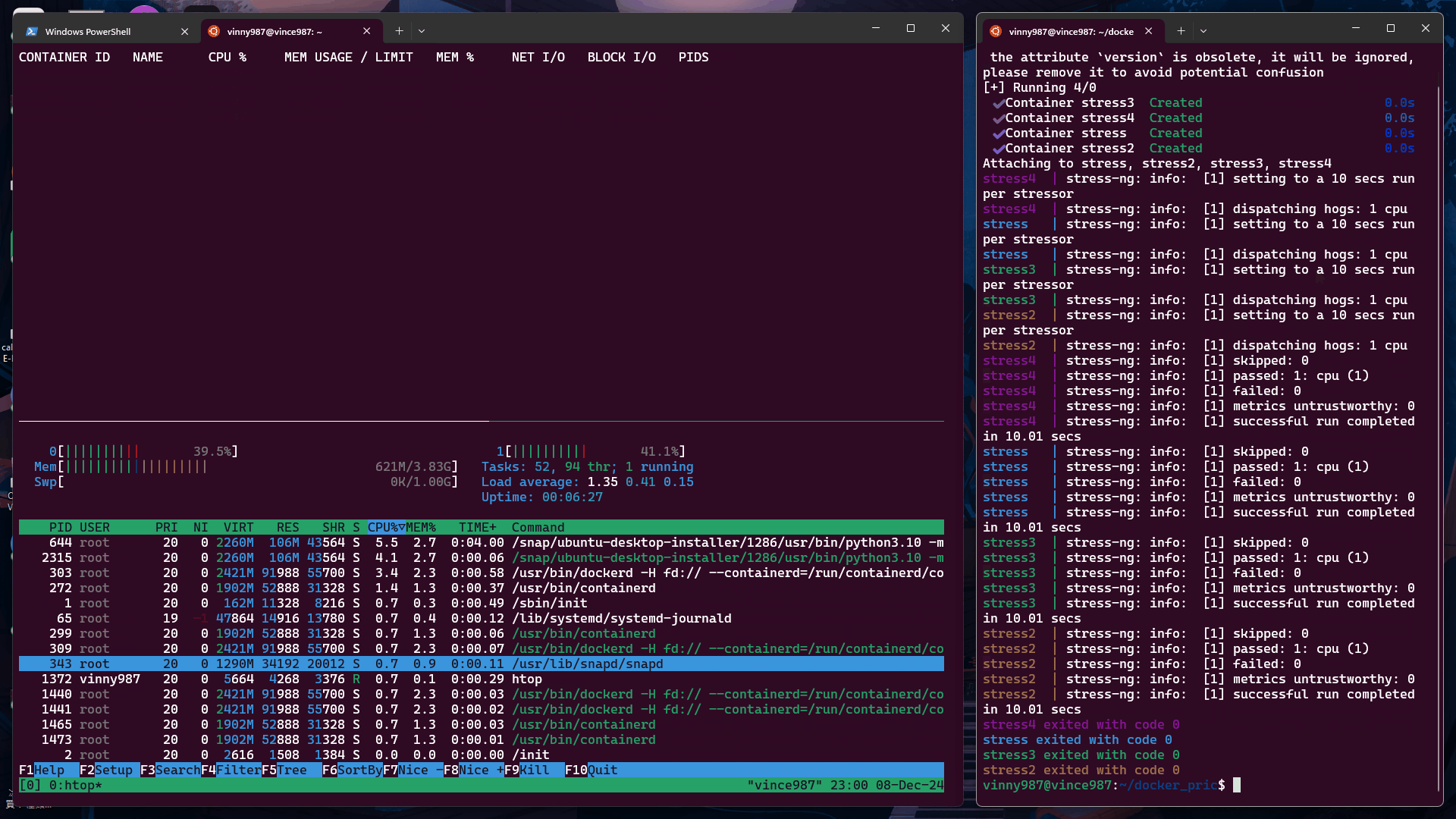
cpu-share 值根據 Docker 官方文檔,未設置 cpu-shares 的容器將採用默認值 1024。我們來實驗看看。
稍微修改 docker-compose.yml,移除 stress4 的 cpu-shares 配置:
version: '2'
services:
stress:
image: stress:alpine
container_name: stress
command: ["-c", "1", "-t", "10"]
cpu_shares: 256
stress2:
image: stress:alpine
container_name: stress2
command: ["-c", "1", "-t", "10"]
cpu_shares: 512
stress3:
image: stress:alpine
container_name: stress3
command: ["-c", "1", "-t", "10"]
cpu_shares: 768
stress4:
image: stress:alpine
container_name: stress4
command: ["-c", "1", "-t", "10"]
執行結果:
未設定 cpu-shares 的容器默認值為 1024,其分配的 CPU 資源比例高於其他容器。
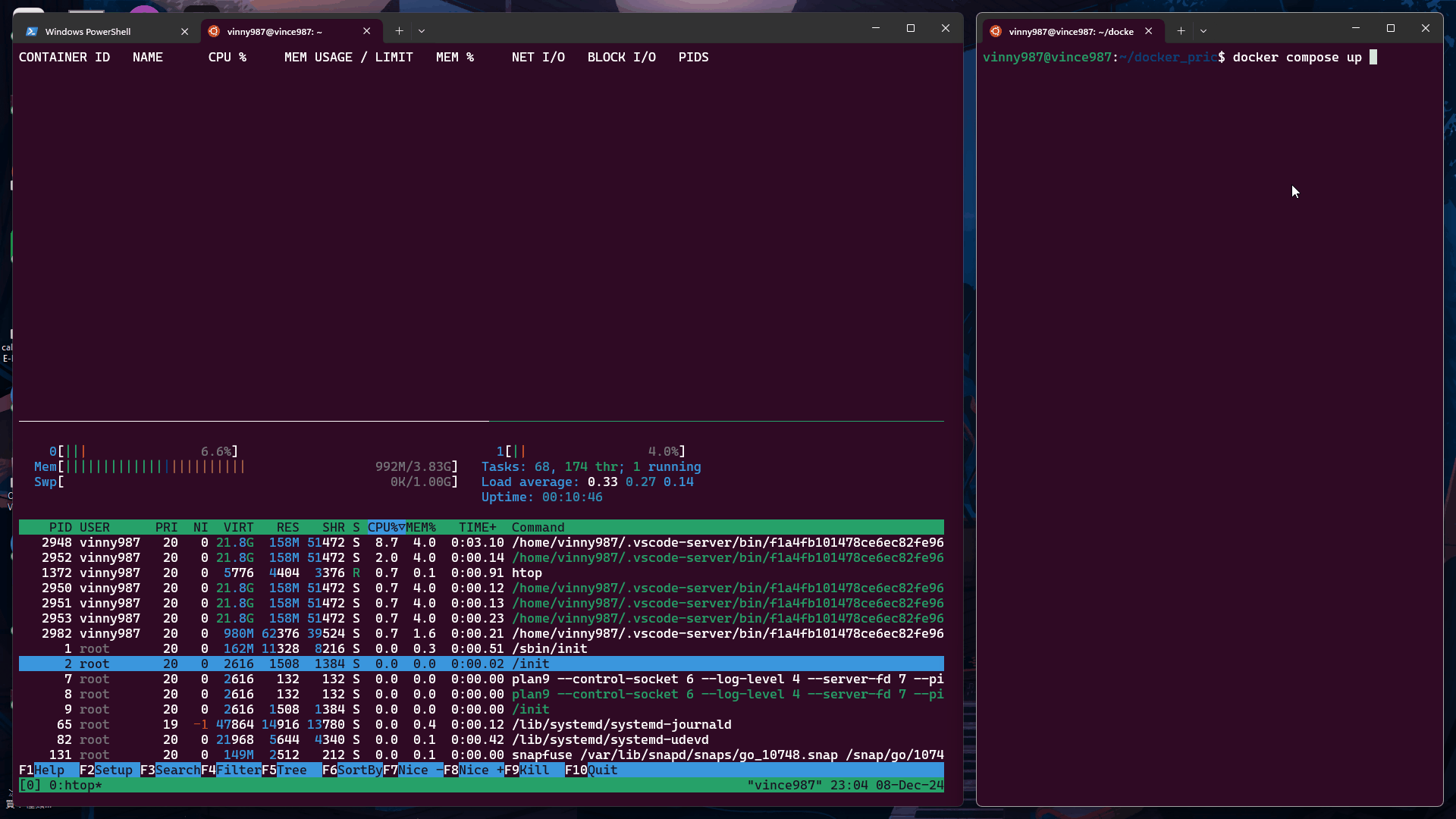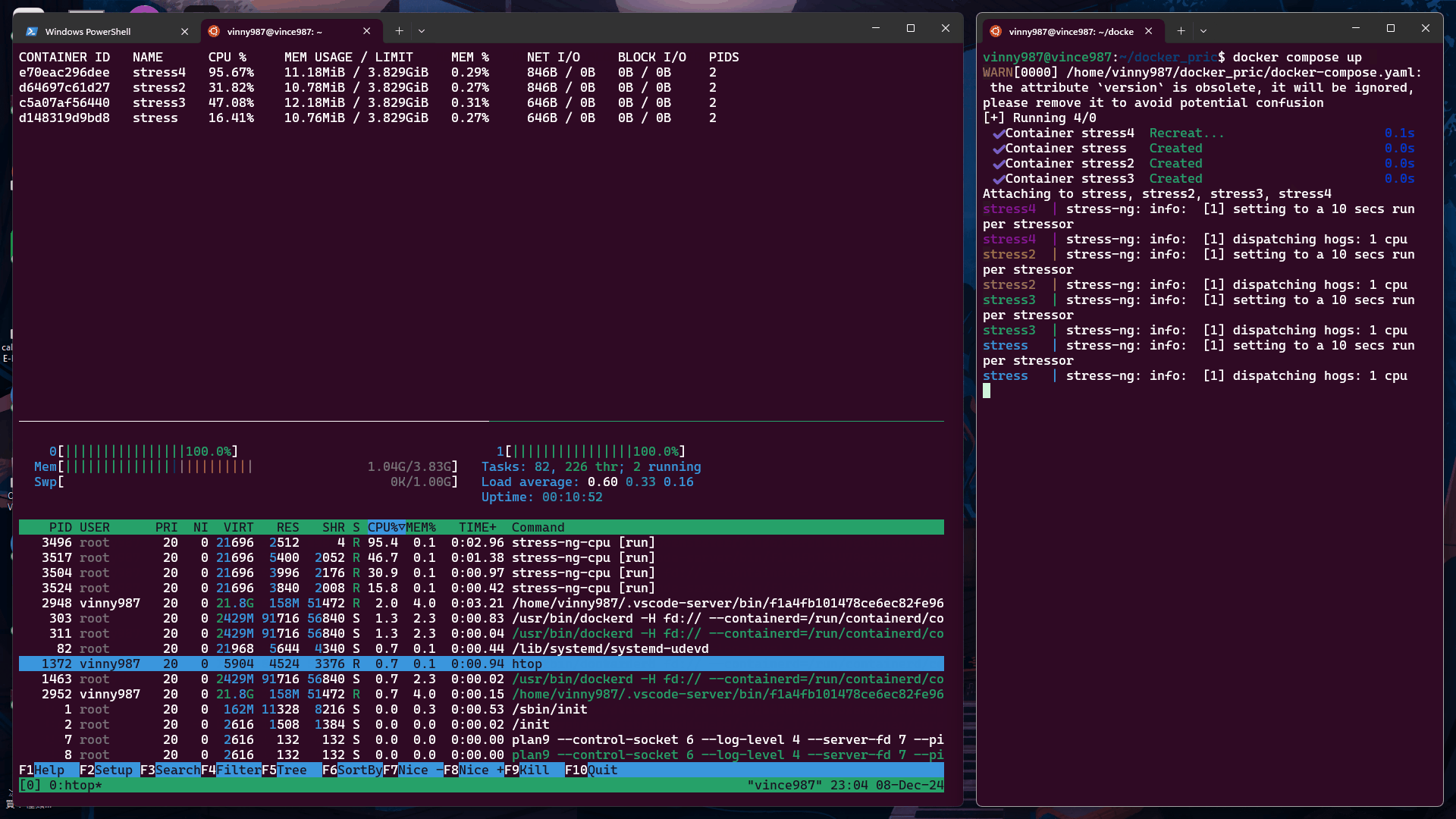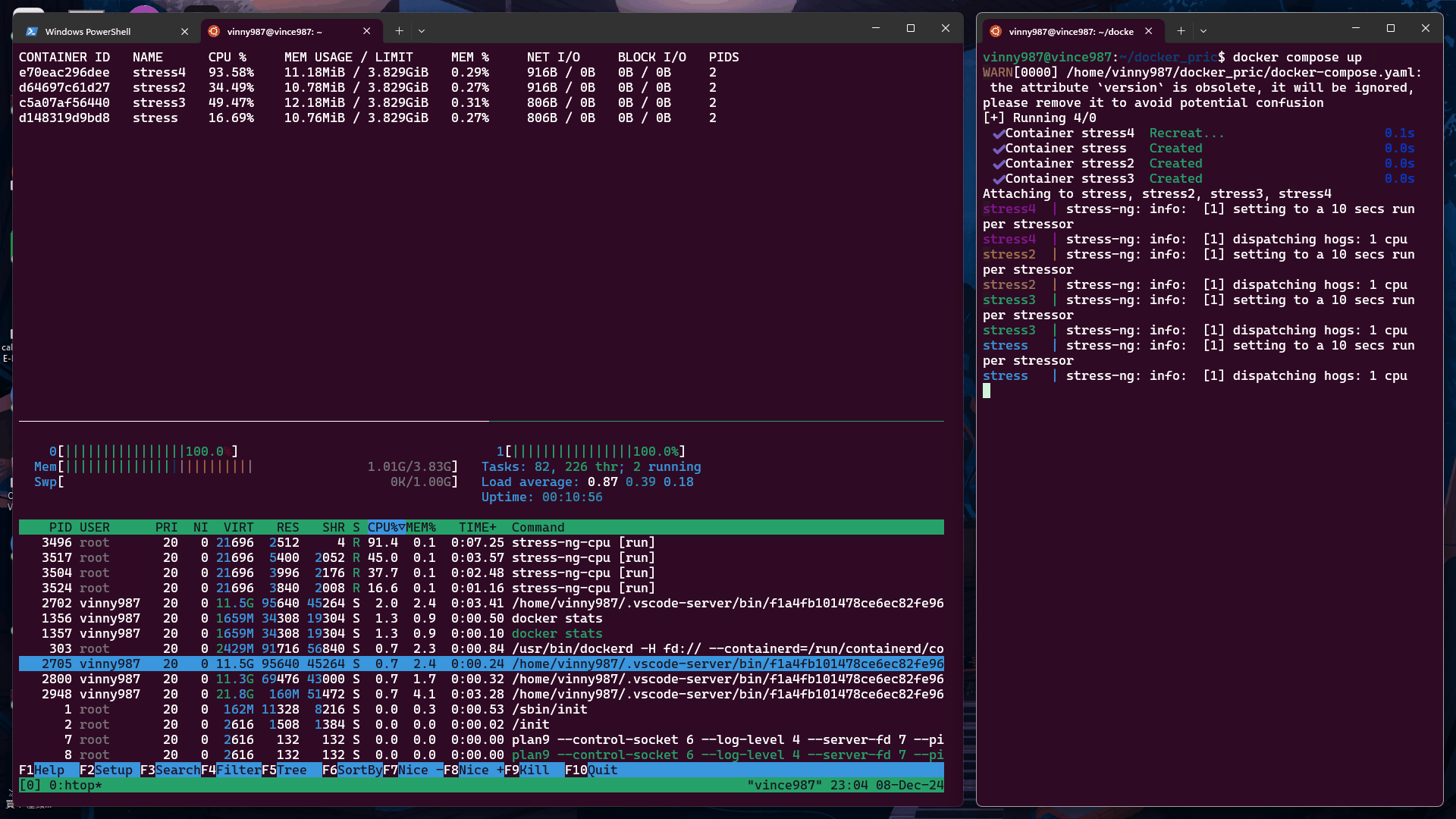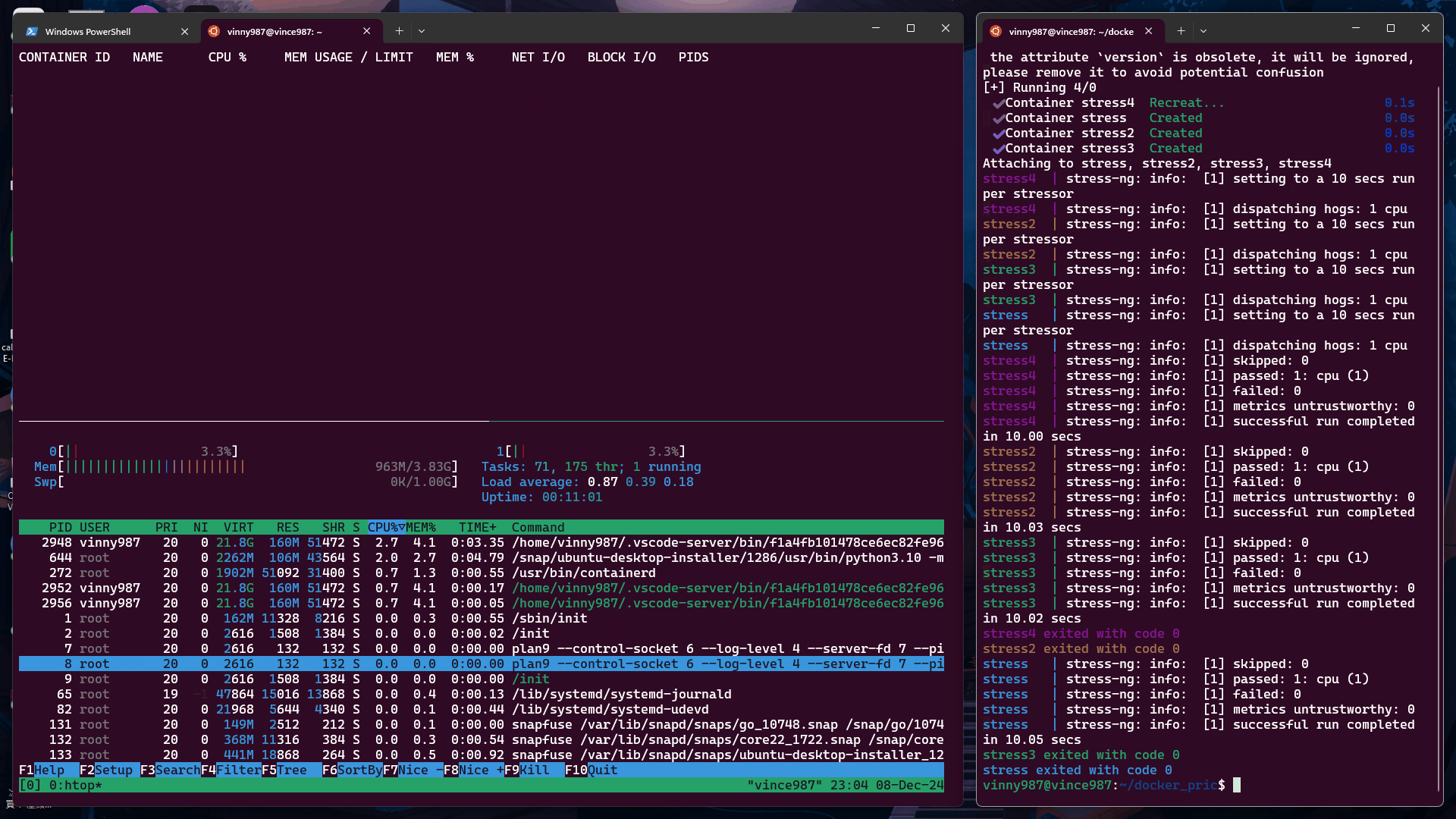
觀察結果
從實驗結果來看,沒有設定 cpu-shares 的容器,在資源搶奪上的優先度是高於有設定 cpu-shares 容器。
結論:
cpu-shares 決定。權重較高的容器將獲得更多的 CPU 資源。cpu-shares 的容器,在資源搶奪上的優先度高於有設定 cpu-shares 容器。記憶體資源限制是容器資源控制的重要部分。以下實驗將展示如何使用 Docker 限制容器記憶體,並觀察系統的行為。
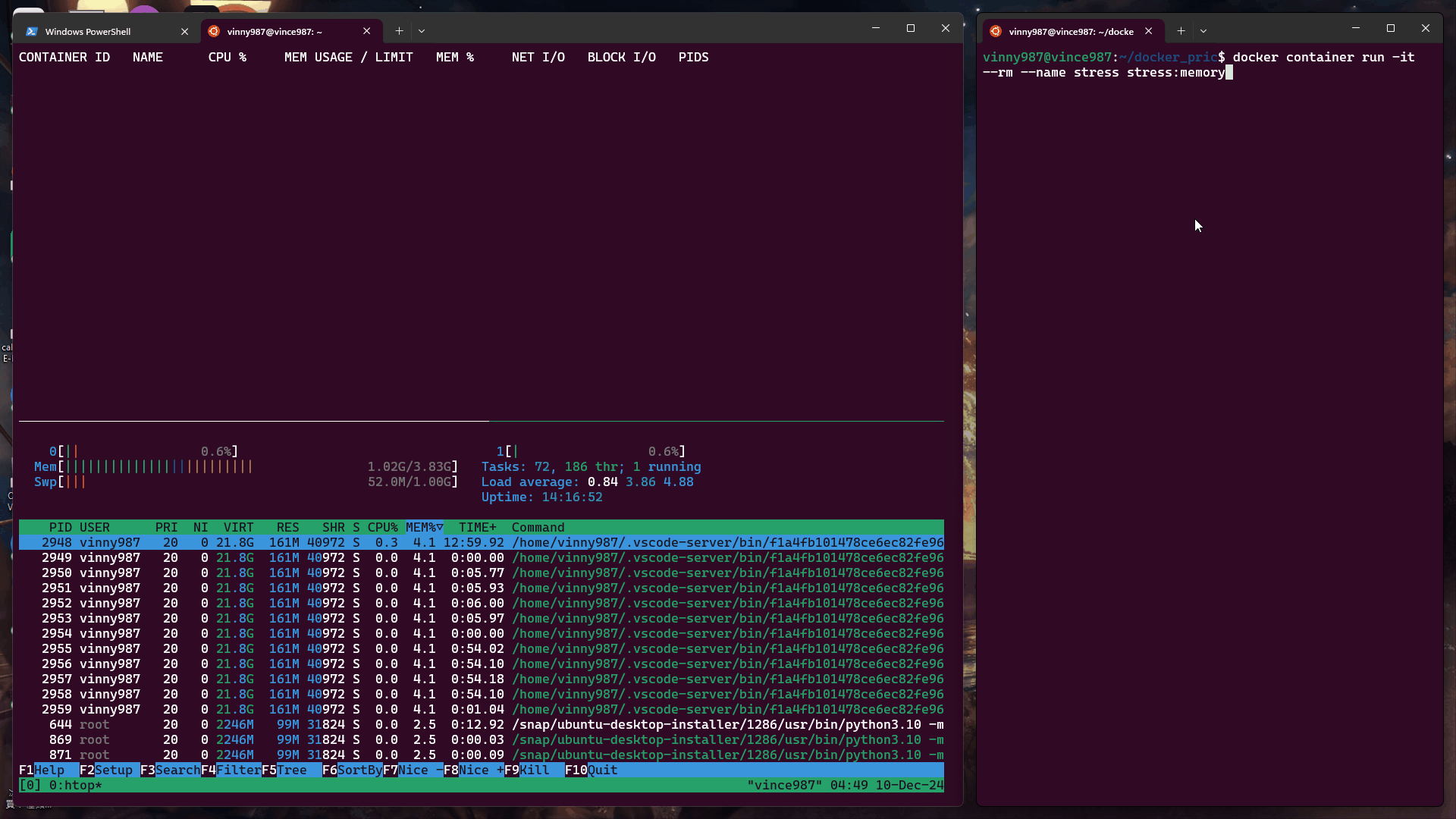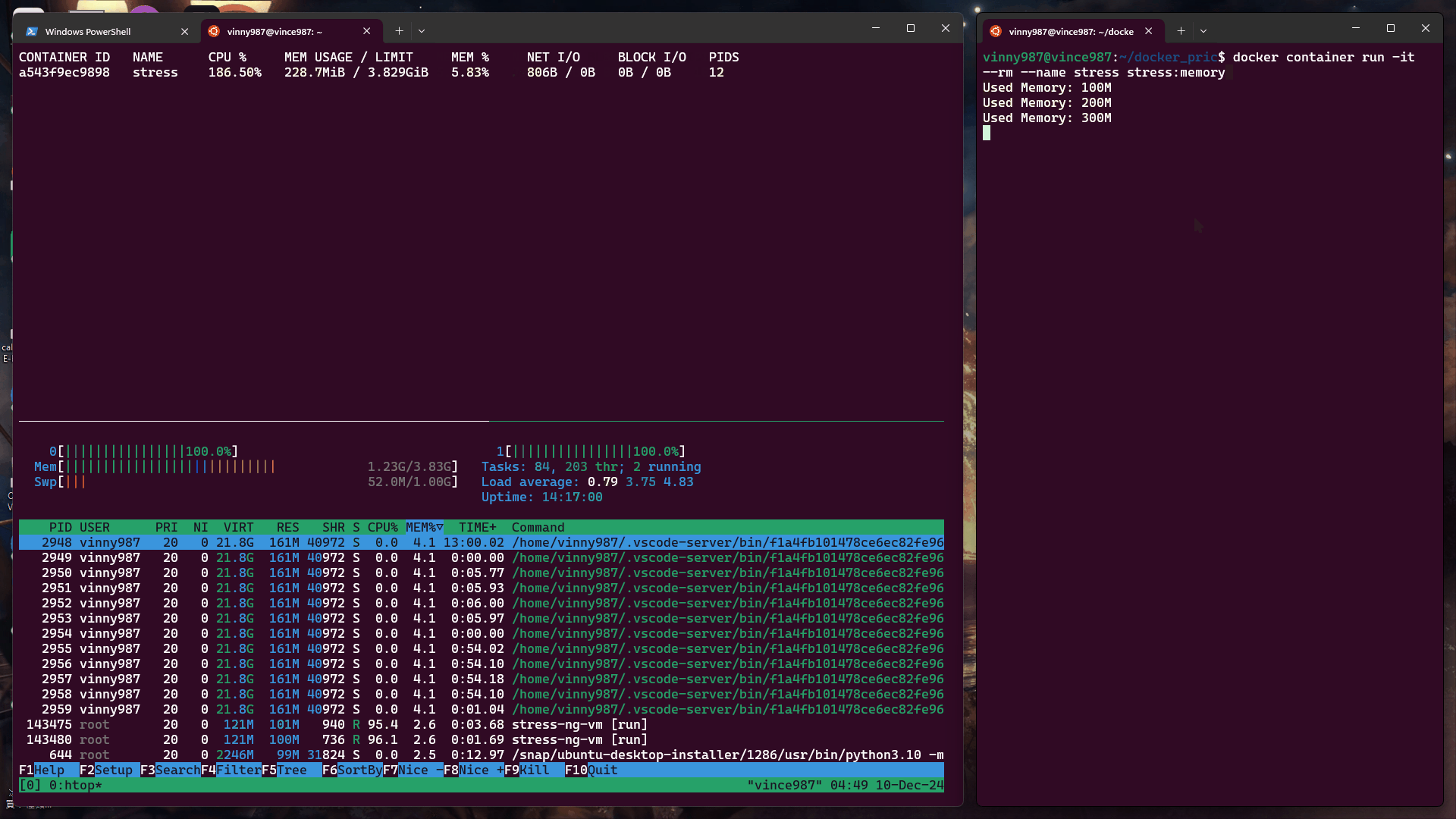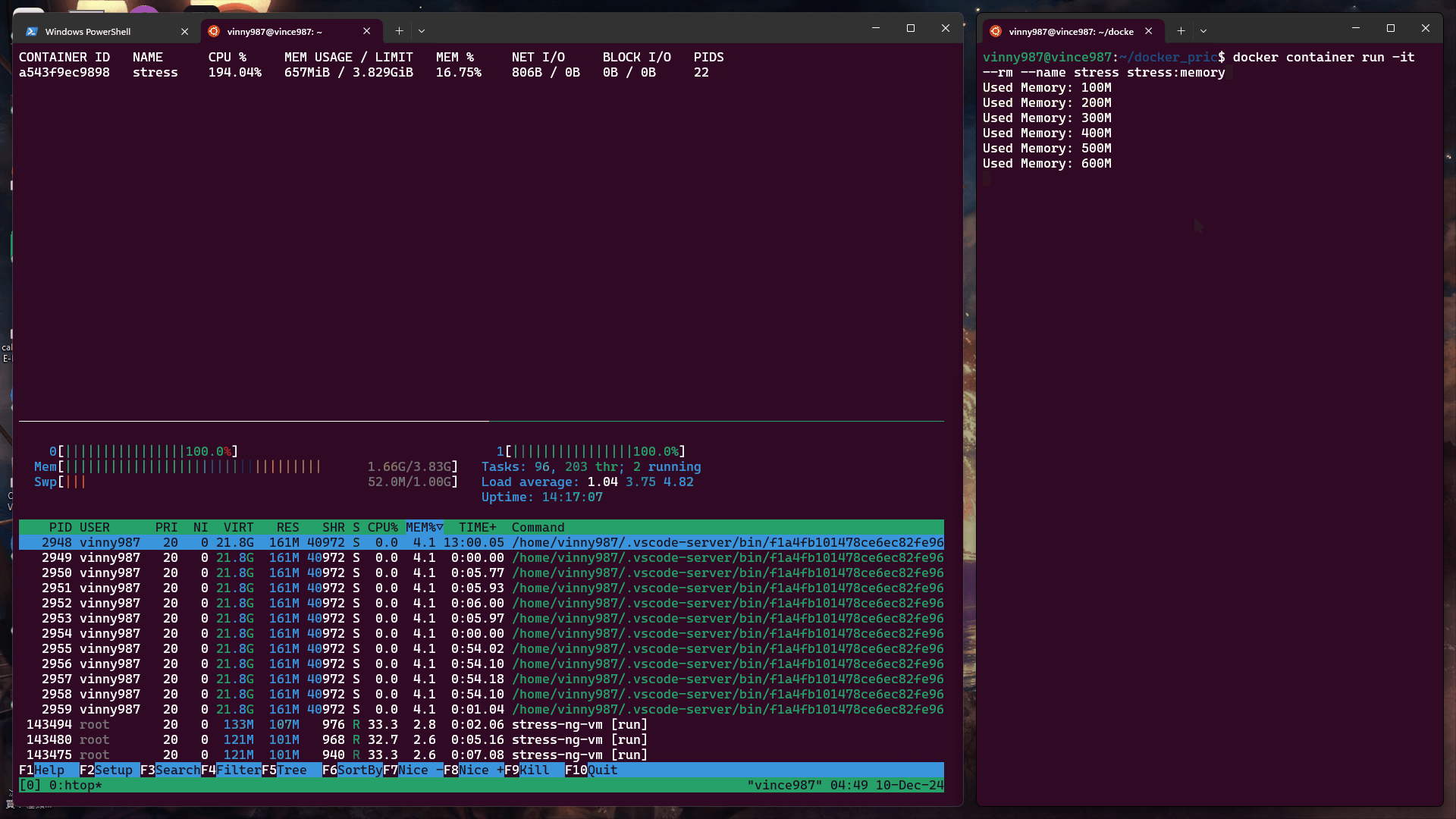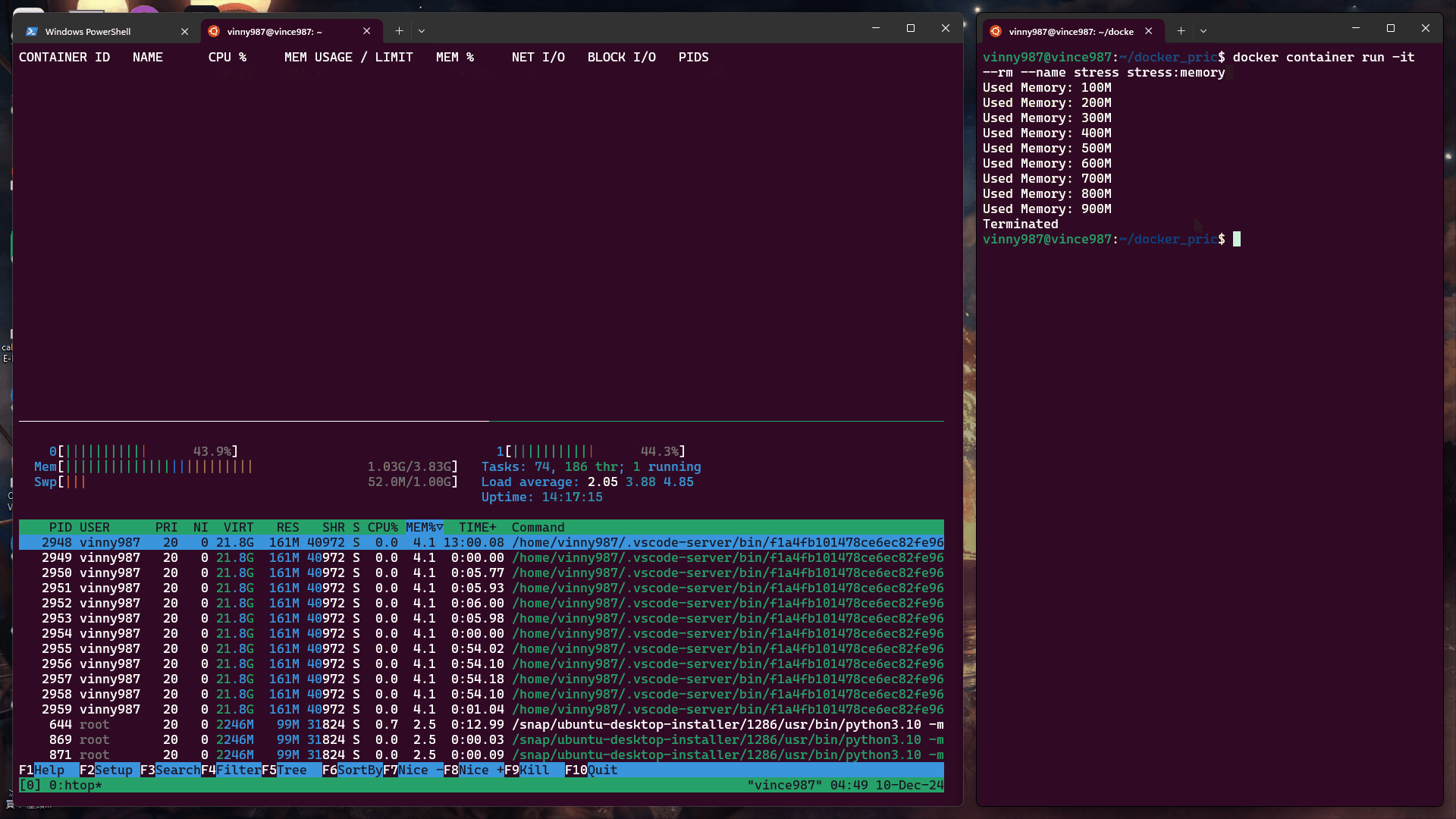
當未設定記憶體限制時,容器預設可以使用宿主機的所有可用記憶體。
測試指令:
docker container run -it --rm --name stress stress:memory
結果:
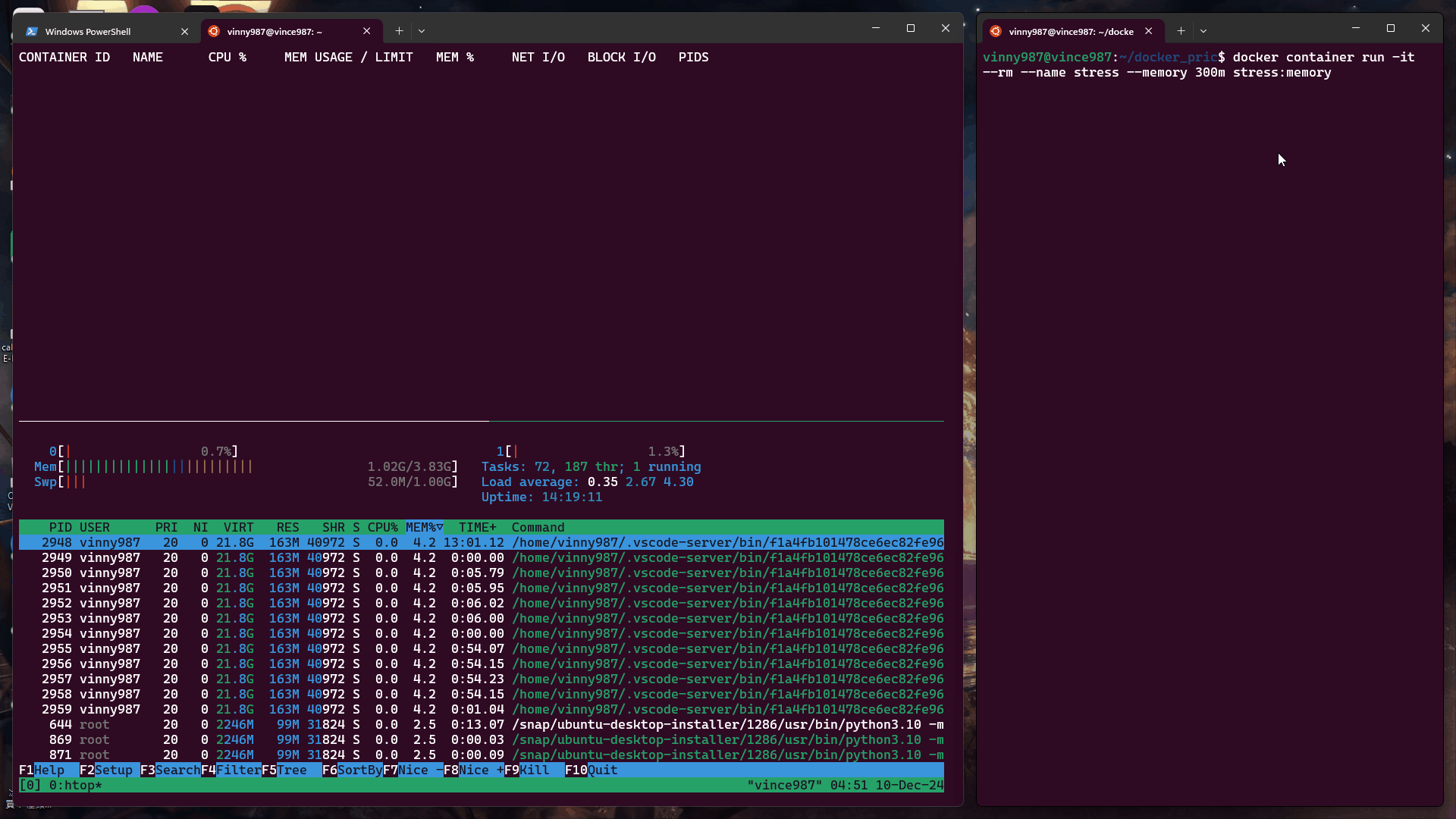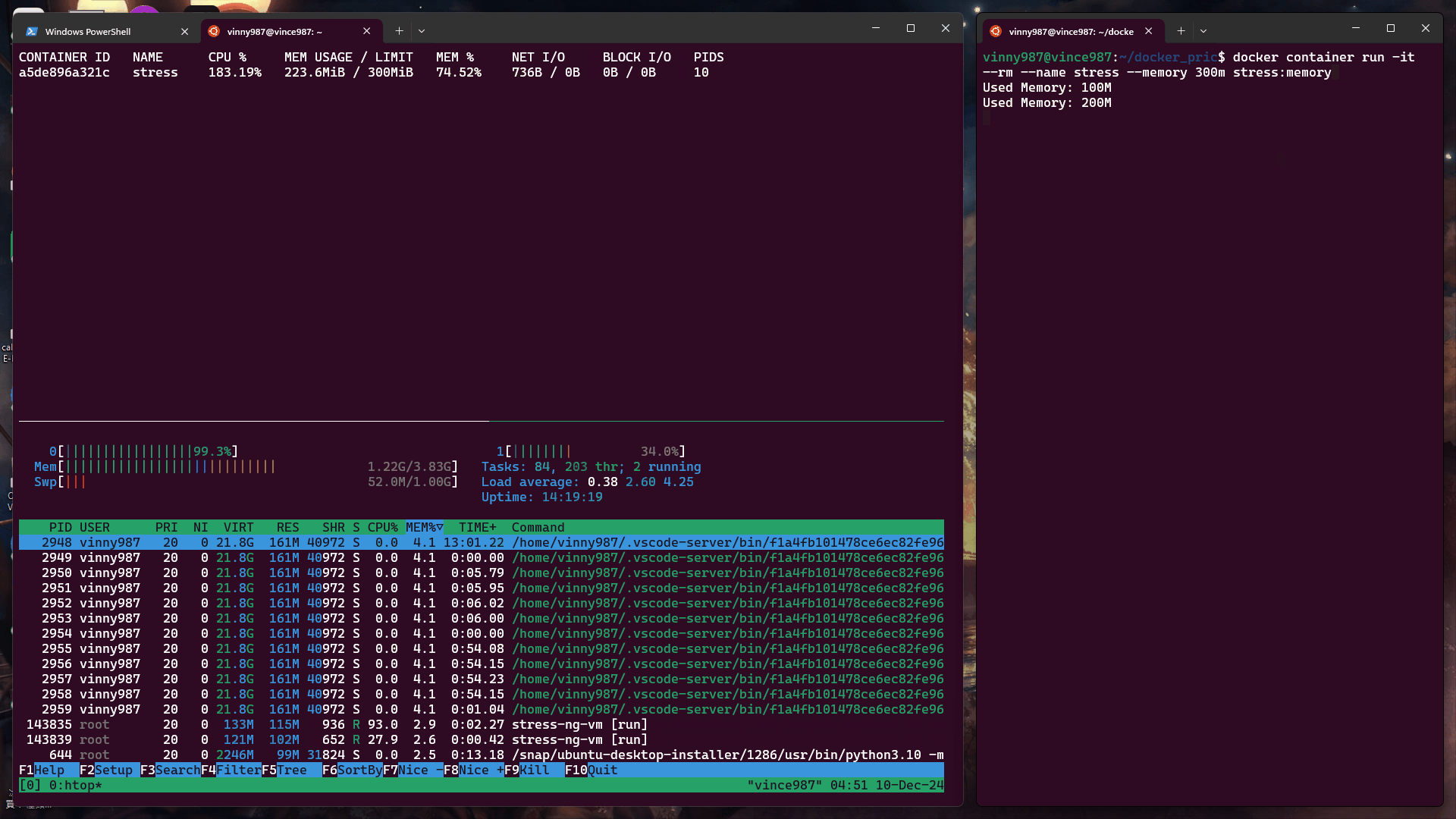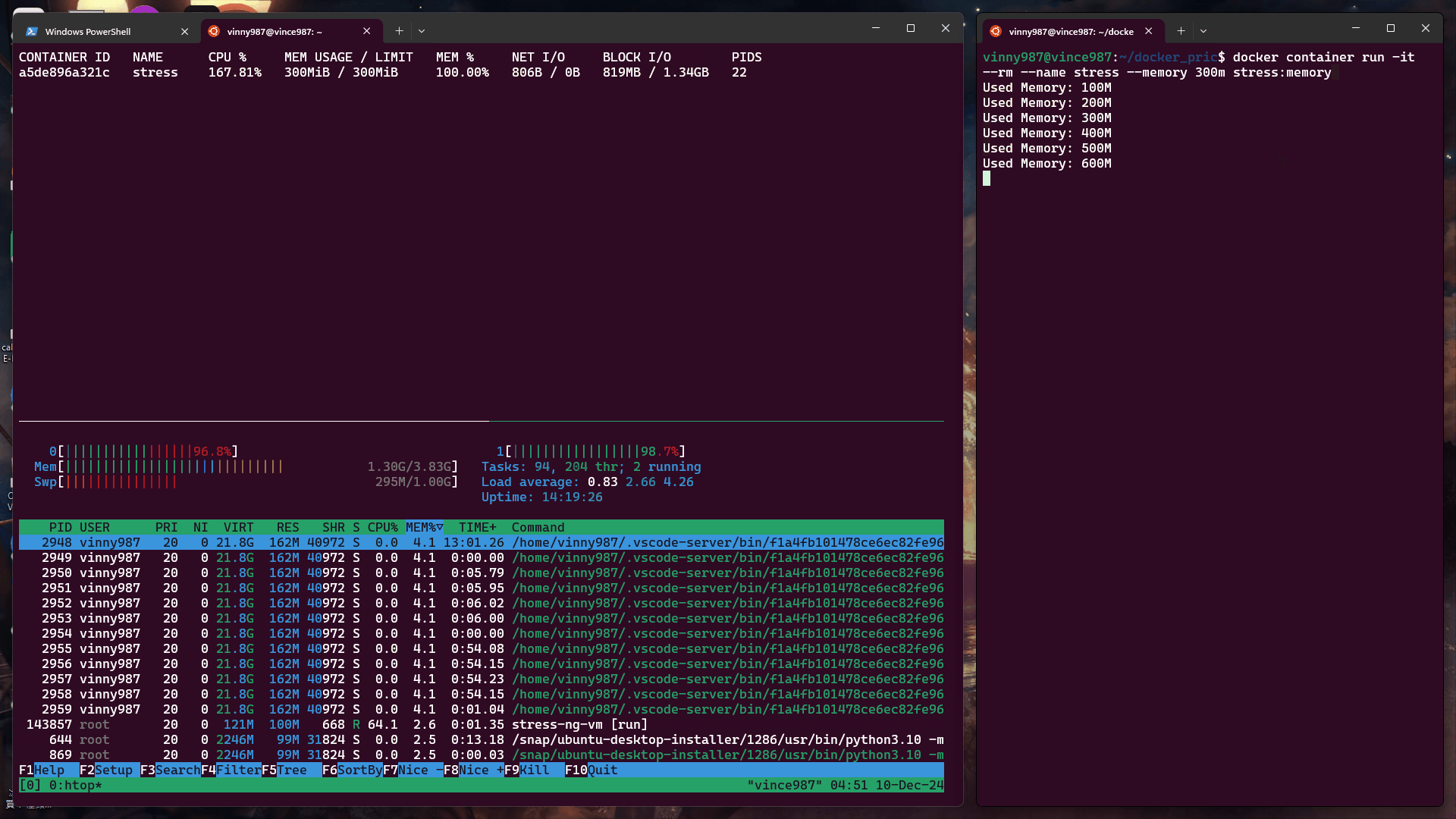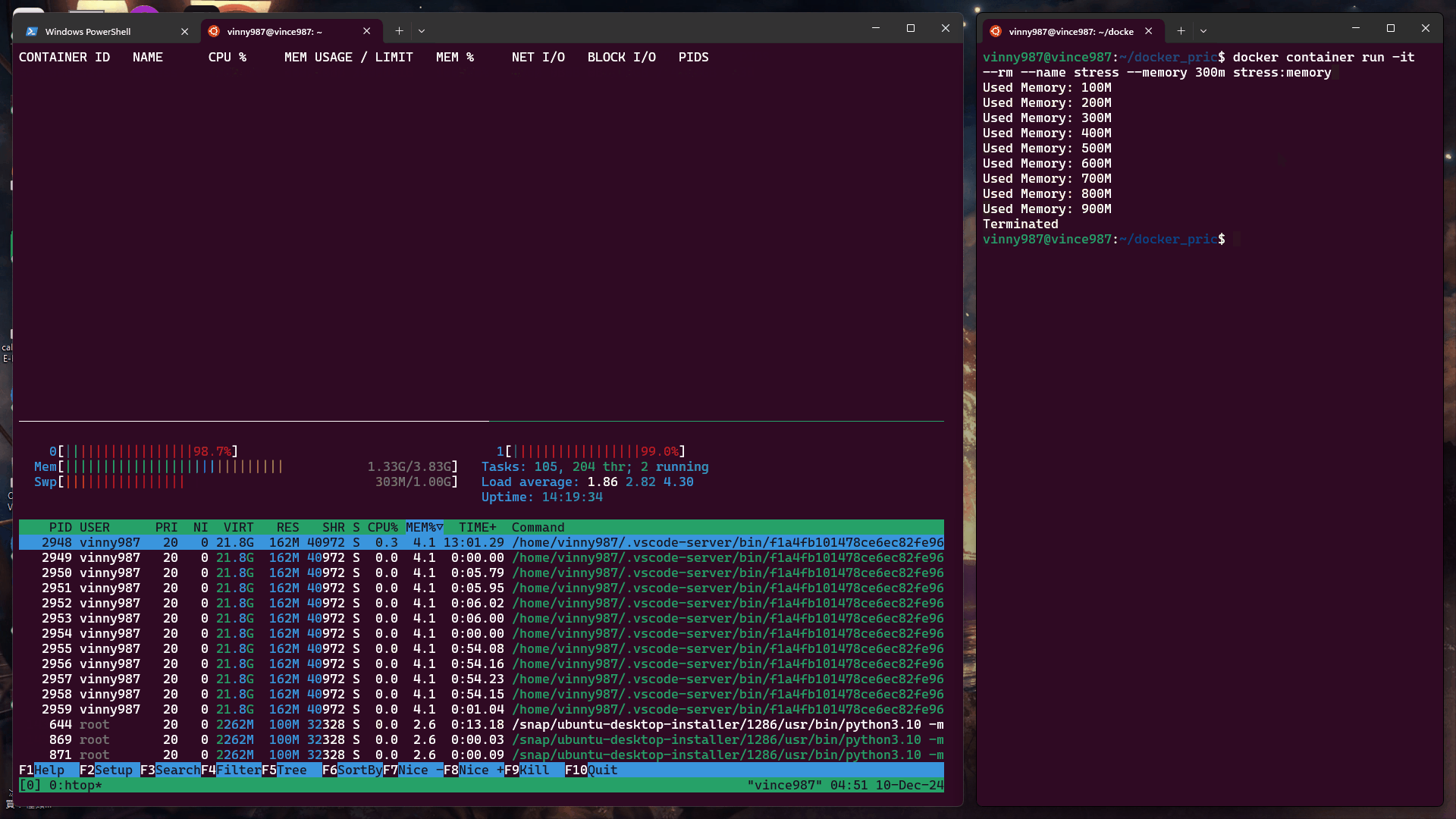
將容器的記憶體限制為 300MB,觀察系統的行為。
測試指令:
docker container run -it --rm --name stress --memory 300m stress:memory
結果:
觀察現象:
Swap 是 Linux 系統的虛擬記憶體,使用磁盤空間模擬記憶體,因此在記憶體耗盡時,會切換到使用 Swap。
當未限制容器的 Swap 使用量時,容器可以使用的 Swap 等於設置的記憶體限制(此例為 300MB)。
至於為什麼 Swap 使用量也耗盡後,為什麼還是沒觸發 OOM Kill 呢? 其實它已經發生了,下面我們來驗證。
進一步限制容器的總記憶體(物理記憶體 + Swap)為 300MB,模擬更嚴格的限制條件。
系統監控
在宿主機中開啟新終端,執行以下指令監控 OOM 現象:
tail -f /var/log/syslog | grep -i "oom"
測試指令:
docker container run -it --rm --name stress --memory 300m --memory-swap 300m stress:memory
--memory 限制物理記憶體。--memory-swap 限制總記憶體(物理記憶體 + Swap)。結果:
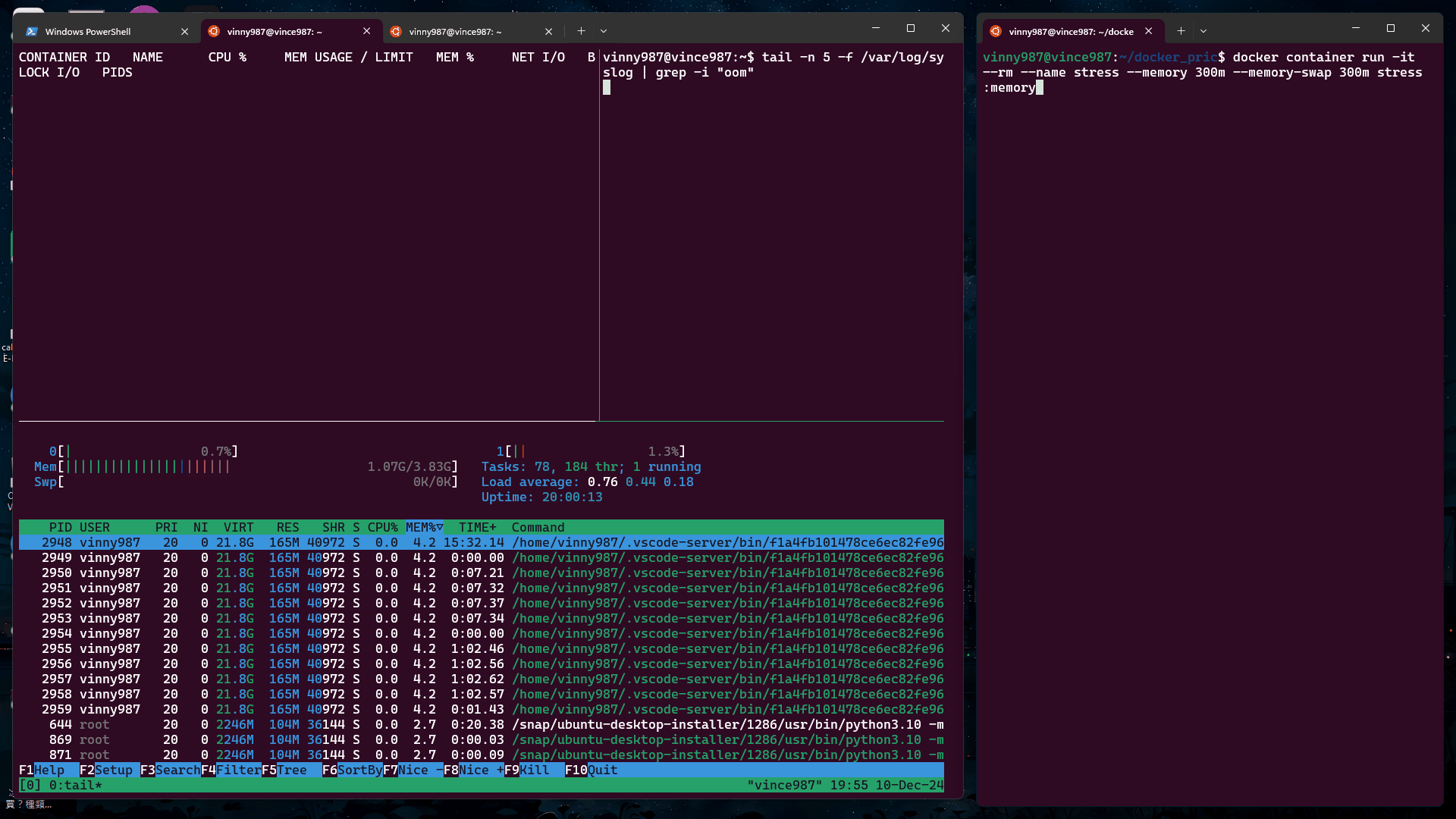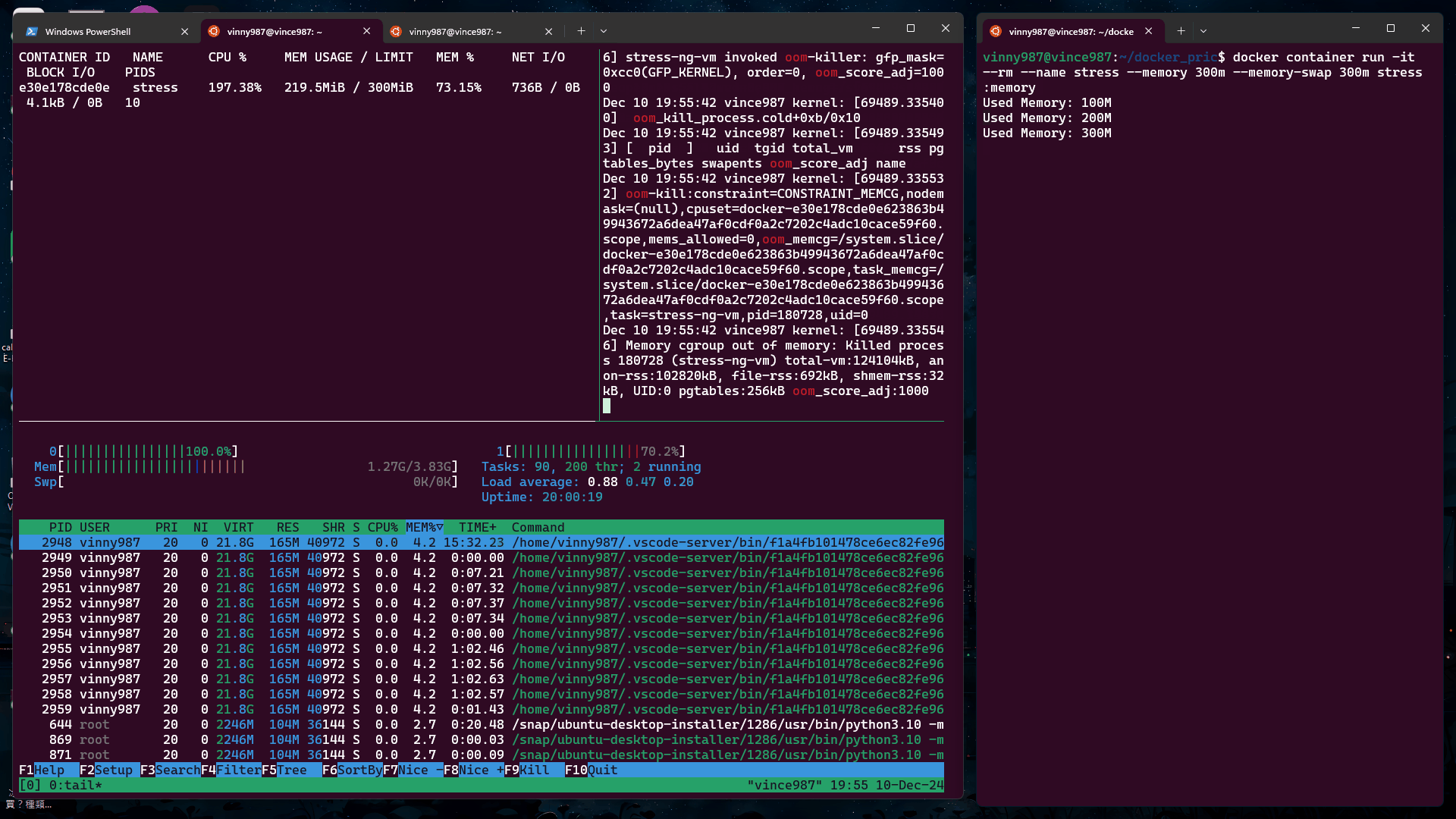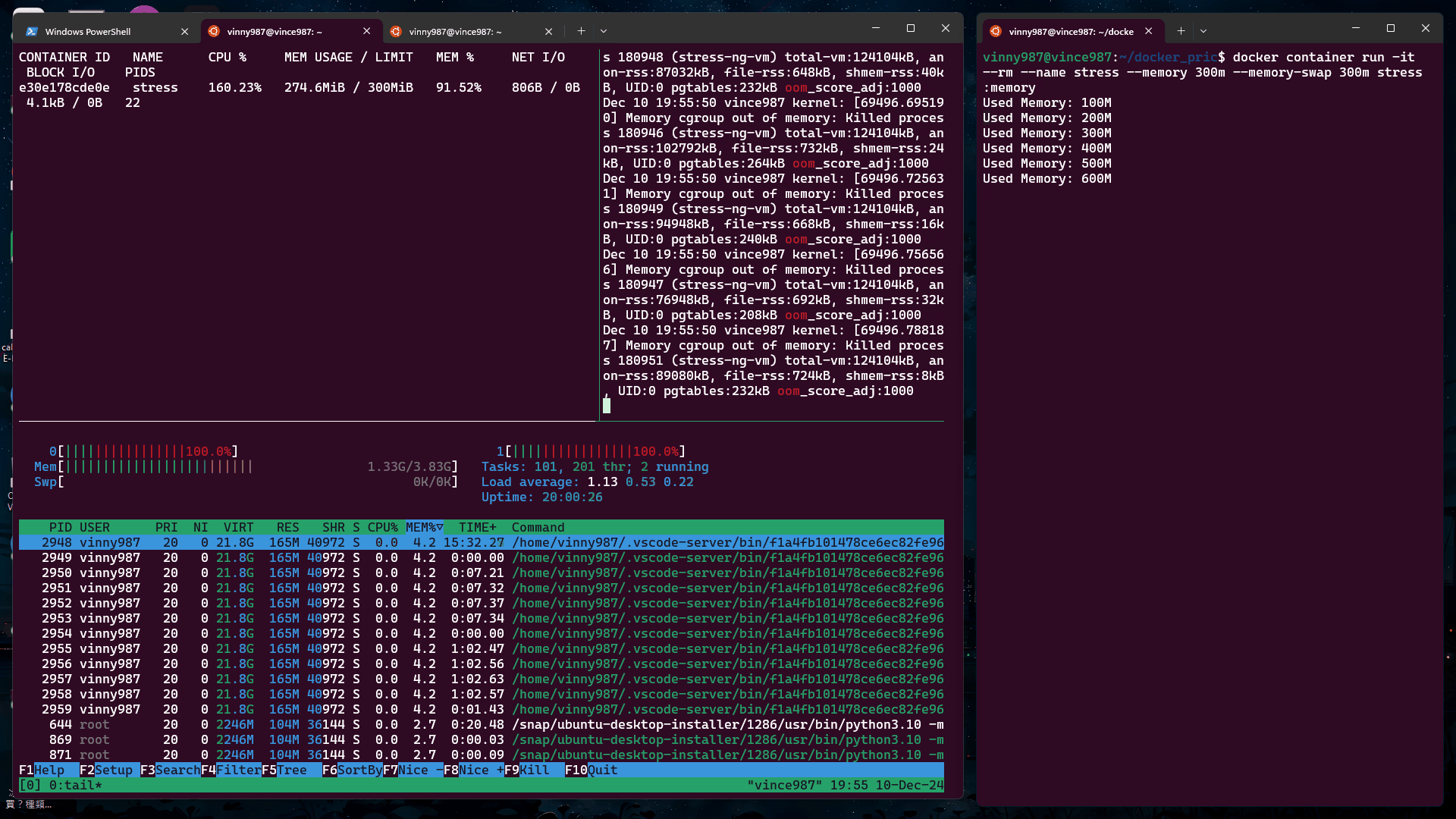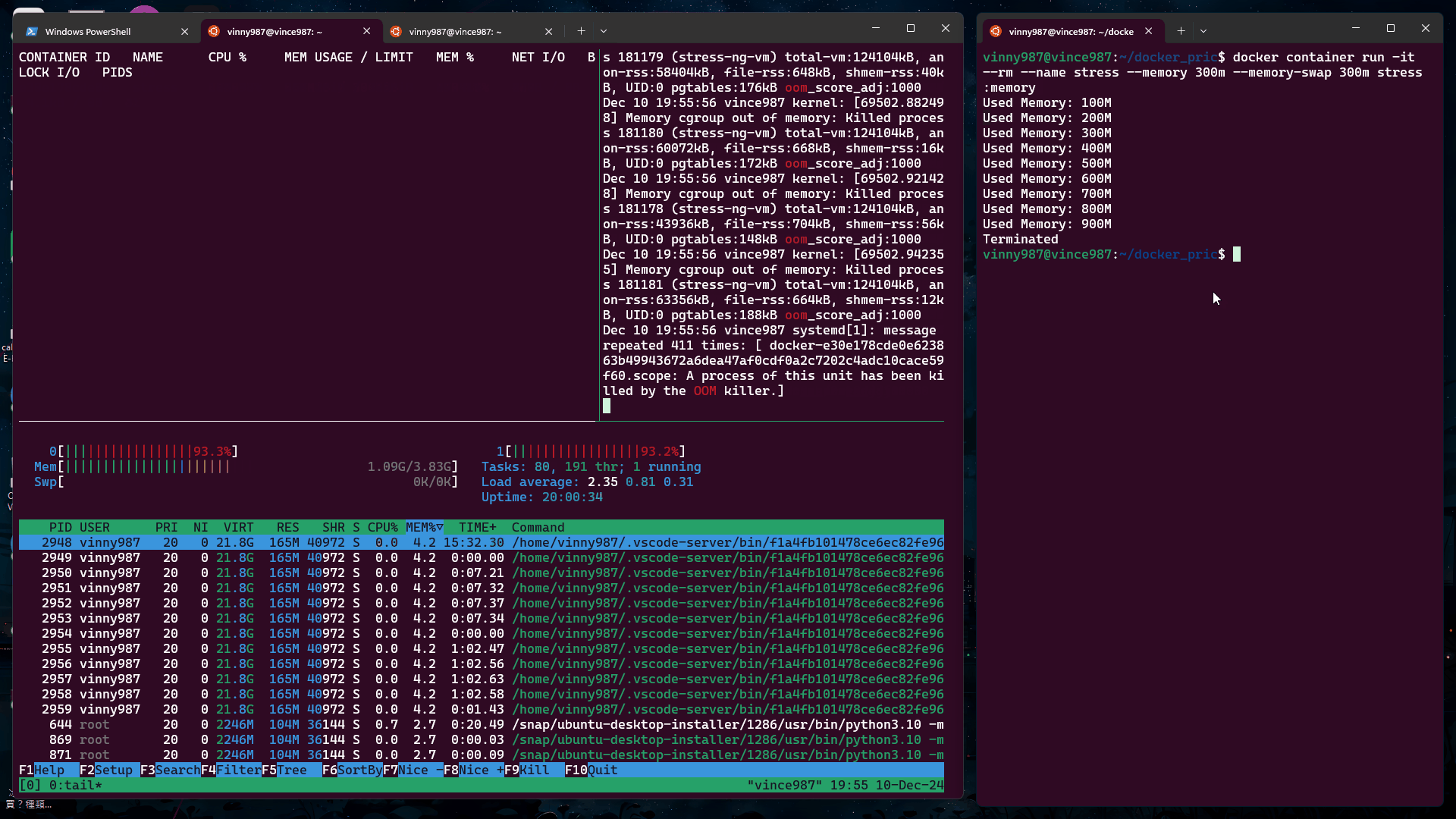
觀察現象:
這牽扯到兩個概念:
stress-ng 壓力測試工具時,它作為主進程(PID=1)啟動。壓力測試石的 Worker 則是 stress-ng 產生的子進程。也就是說,當我們使用 stress-ng 測試,發生 OOM Kill 的進程並不是主進程,而是其他子進程,難怪容器不會被殺掉。
為了驗證這個說法,我們進行下一個實驗。
為驗證主進程 OOM 時容器的行為,我們使用 Python 編寫腳本進行實驗。
memory_stress_test.py
import sys
import time
def trigger_oom():
# 創建一個巨大的列表來快速消耗記憶體
memory_list = []
current_size = 0
print("開始觸發 OOM...")
while True:
try:
# 每次分配約 100MB 的記憶體
chunk = ['x'] * (25 * 1024 * 1024)
memory_list.append(chunk)
current_size += 100
print(f"當前已分配記憶體: {current_size} MB")
time.sleep(0.5)
except MemoryError:
print("記憶體分配失敗")
break
if __name__ == "__main__":
trigger_oom()
Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY memory_stress_test.py .
CMD ["python", "memory_stress_test.py"]
構建指令:
docker build -f Dockerfile.stress.memory.python -t stress:memory-py .
測試指令
docker run -it --memory=500m stress:memory-py
結果:
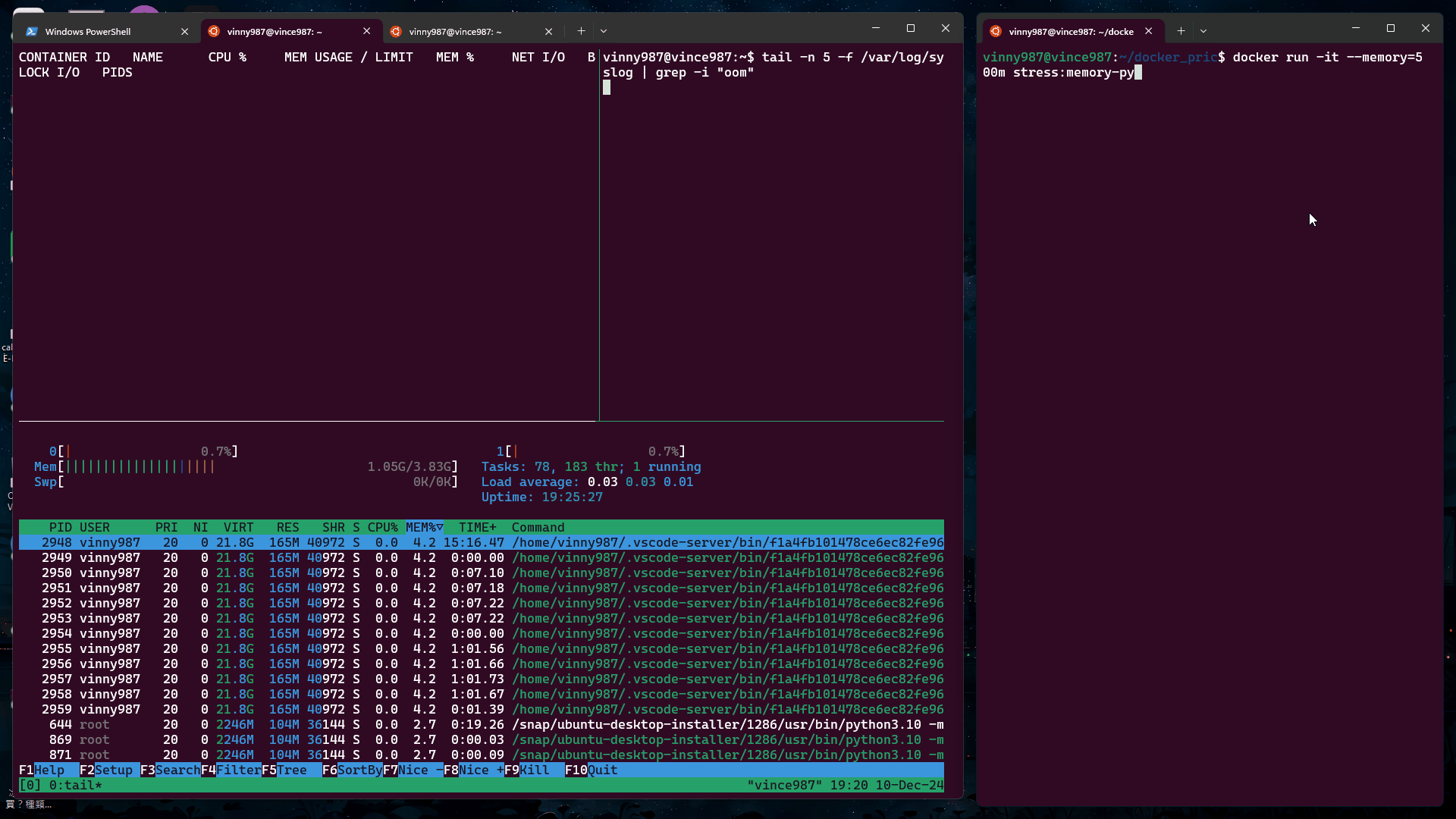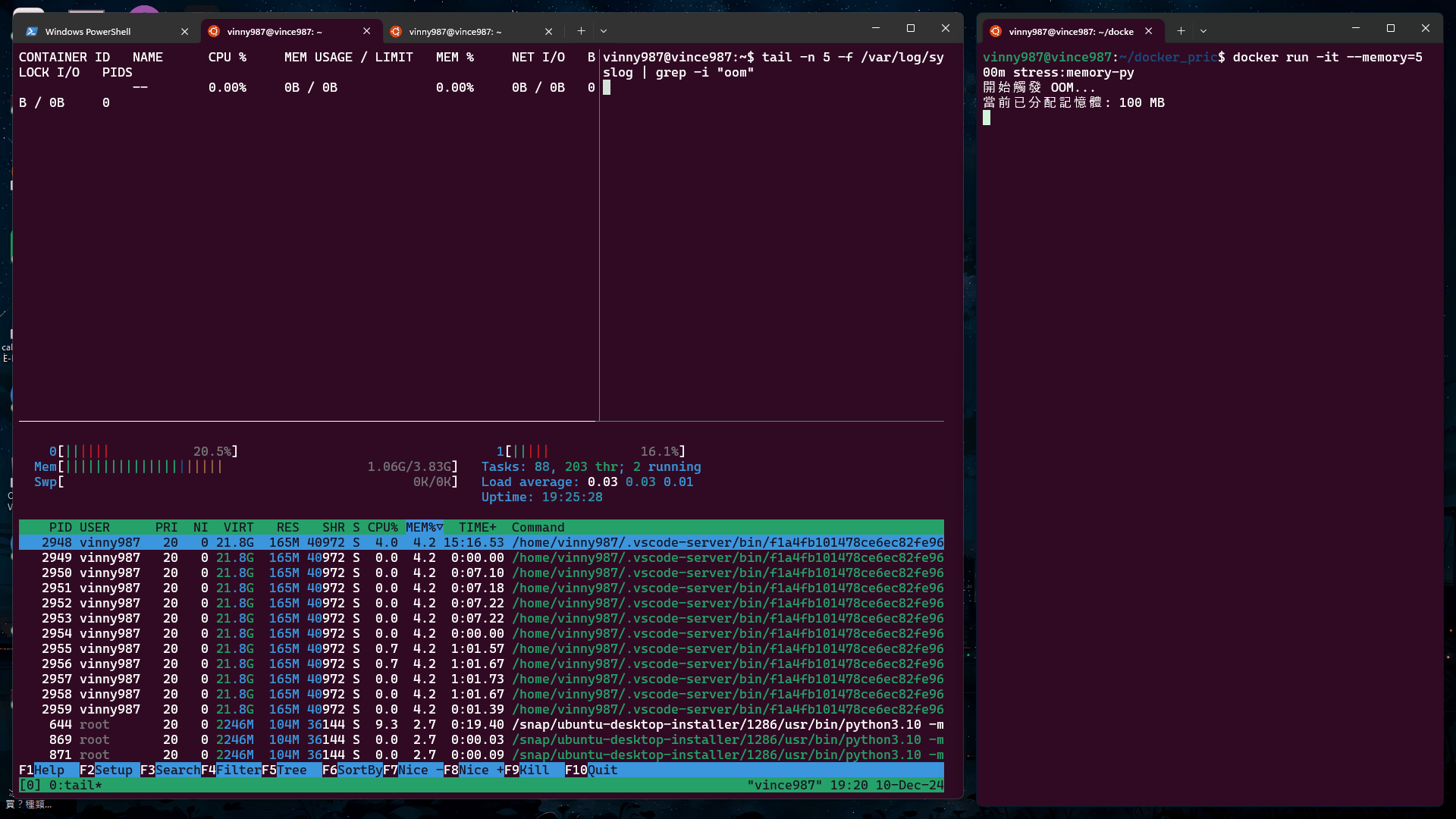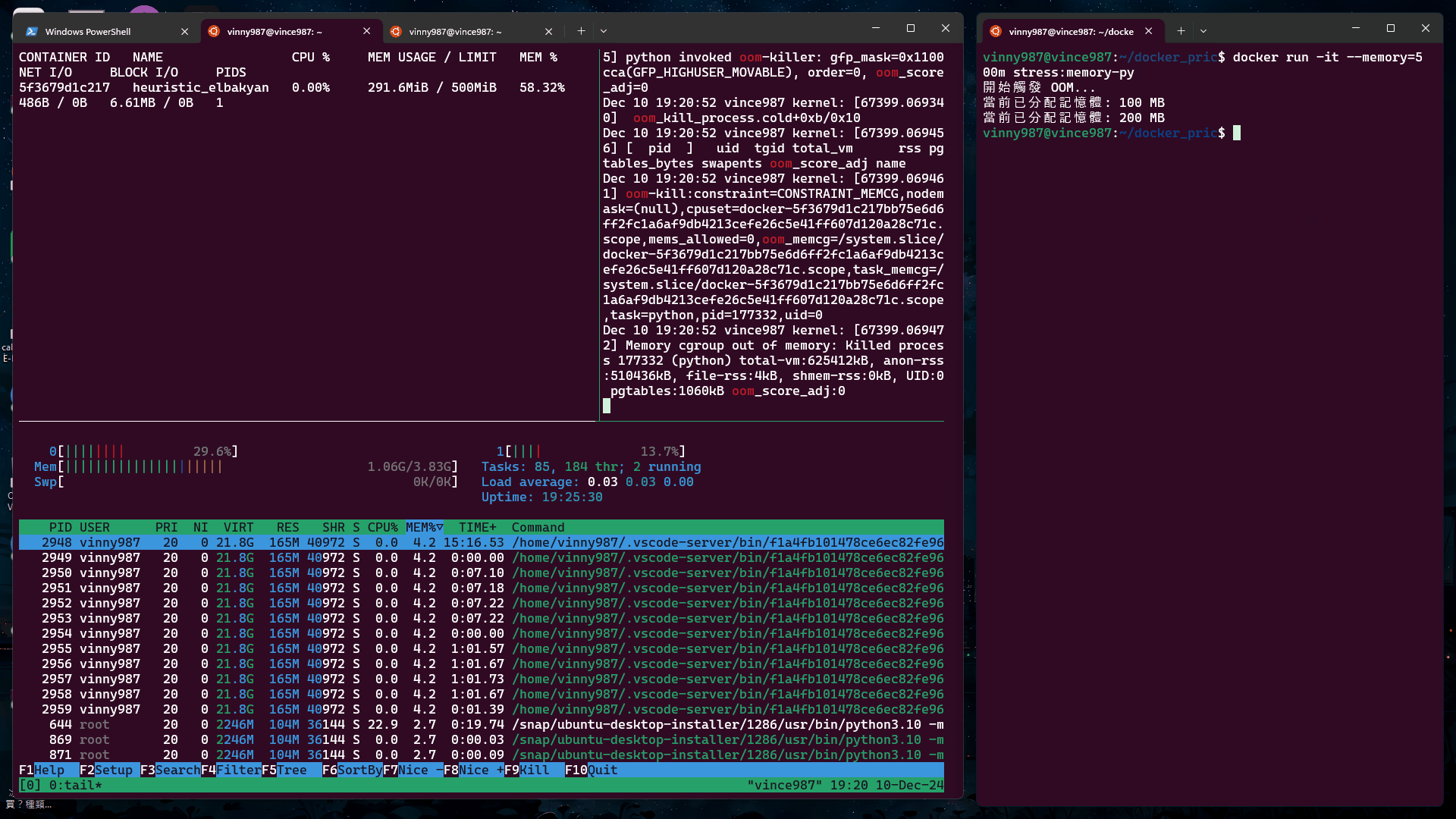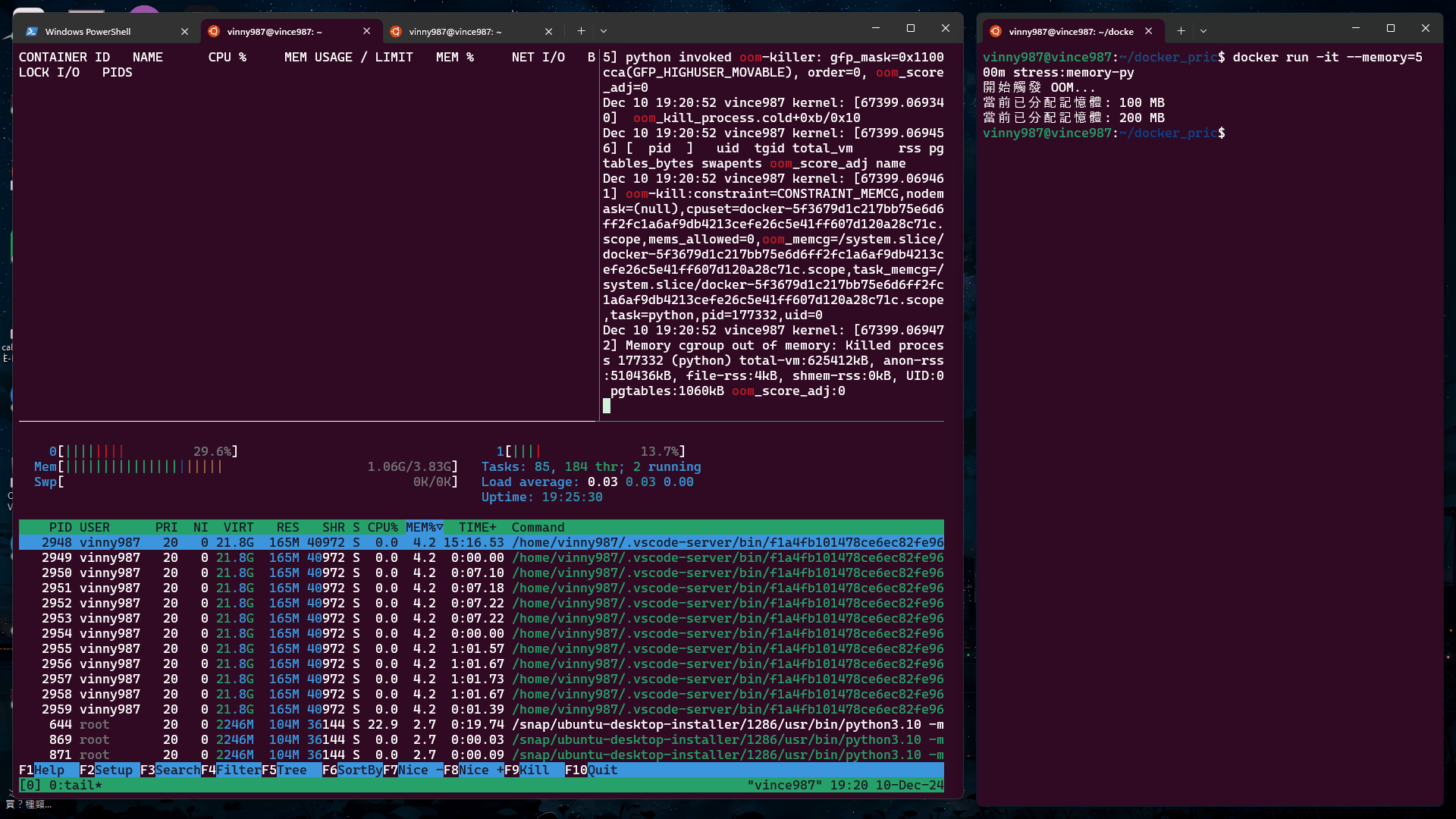
確認 OOM 狀態
檢查容器的狀態:
docker container ls -a
輸出範例:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5f3679d1c217 stress:memory-py "python memory_stres…" 34 seconds ago Exited (137) 31 seconds ago heuristic_elbakyan
查看詳細資訊
使用 docker inspect 查看容器的結束狀態:
docker container inspect 5f3679d1c217 --format '{{json .State}}' | jq
結果範例:
{
"Status": "exited",
"Running": false,
"Paused": false,
"Restarting": false,
"OOMKilled": true,
"Dead": false,
"Pid": 0,
"ExitCode": 137,
"Error": "",
"StartedAt": "2024-12-10T11:20:50.956018772Z",
"FinishedAt": "2024-12-10T11:20:52.491126925Z"
}
解讀:
OOMKilled 為 true,證明主進程觸發 OOM 導致容器被終止。通過上述實驗,我們證實了容器內的資源限制功能如何影響應用運行:
希望這篇文章能幫助你更深入理解 Docker 的資源限制機制,並靈活應用於實際場景。
 vincentlin2447
vincentlin2447

 iThome鐵人賽
iThome鐵人賽