這一篇我們來介紹SAP HANA高可用度(High Availability) 及 擴充性(Scalability)
一般IT系統的運作針對高可用度我們會分為兩類,預期性與非預期性。預期性就如同大家知道的IT系統的軟硬體升級維修等等日常作業。非預期性就是軟硬體無預警的跨調,甚至是地端機房電力/水/火災等等問題。所以建立系統的高可用度就非常重要。
一般這種兩個指標可以參考,就是RPO and RTO。這兩種指標會根據每個公司的要求不同而有所差異。關於這兩種指標的詳細描述有興趣的讀者可以參考網路上其他資料。以下簡圖可簡易解釋這種兩指標
哪HANA在高可用方面有哪些supports呢?
SAP HANA有 Fault recover and Disaster recovery,如下圖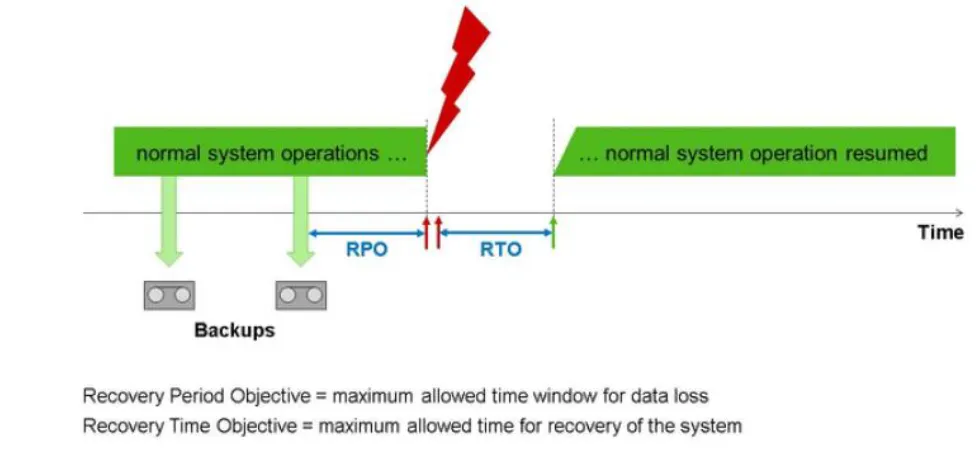
哪甚麼是高可用度?底下一些術語及其描述可共參考
哪HANA在高可用方面有哪些supports呢?
1.準備階段: 定期備份以及有第二套系統存在於同個機房或不同機房
2.偵測階段: 能夠"快速且正確"的偵測有問題發
3.回復階段: 開始將資料與系統服務於可用的系統上恢復
4.服務逐漸正常階段: 服務開始逐步正常
若最後原始的軟硬體修復就可將服務轉回原系統,但需要有更多的測試與確認。當然這個也可以是非必選項,取決於每間公司的政策。
SAP HANA有 Fault recover and Disaster recovery,如下圖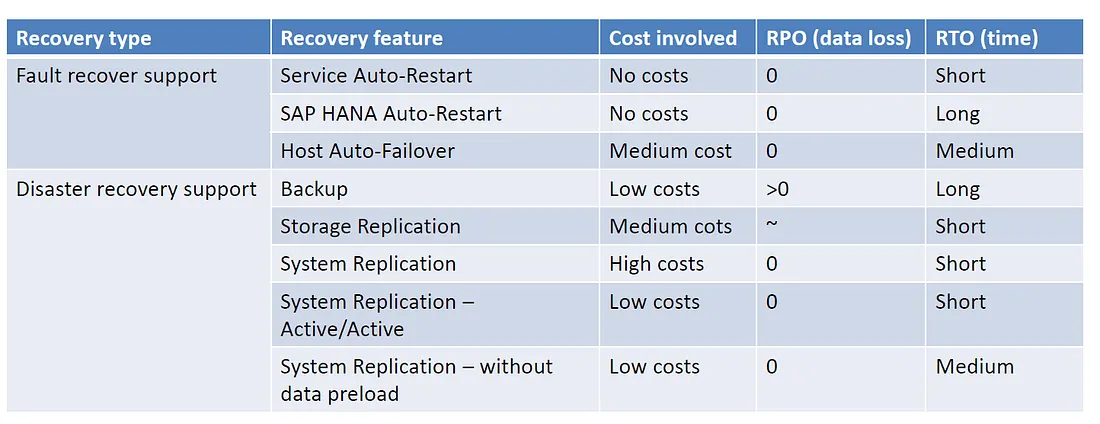
上圖中,Fault recovery的第一項是HANA中的Servic restart(HANA有watchdog系統).這個重啟很快RPO/RTO大都不會很有因為重啟特定服務只會重新載入該項服務的data進到memory,但若是整個HANA系統重啟哪RTO就要花費很多時間了。至於為什麼會花時間可以參考其他HANA的篇章。最後是主機的failover,花費的時間不會比System restart還要多。不過最後還是要說這一切取決於我們的硬體,效能越好當然開機時間越快。但也與整體架構設計有關。Disaster Recovery就比較多樣了,另外System Replication後面會提及。
而storage replication則是經過storage哪一個layer直接做replication(就是一般大家使用storage replication的solution一樣,只是這個storage要經過SAP認證過)但這個方案有丟失資料的可能性。如果是跨地端機房實行storage replication, SAP建議兩地的距離要在100公里內。
Fault Recovery
我們來看一下整個HANA在OS中的開機流程(這個需要對Linux系統面有稍微的了解)就可以知道為什麼HANA可以驅動OS執行Services or System restart
關於Linux的部分在此不提了,我們看到在經過一連串的服務啟動後”sapstartsrv”會去讀取相關的參數檔(profile)啟動一連串前端的服務(Web Service)跟啟動”sapstart”這個服務也會去讀取profile並啟動HDB daemon服務。
所以我們可以比對cockpit 的Process ID於OS中的PID是相同的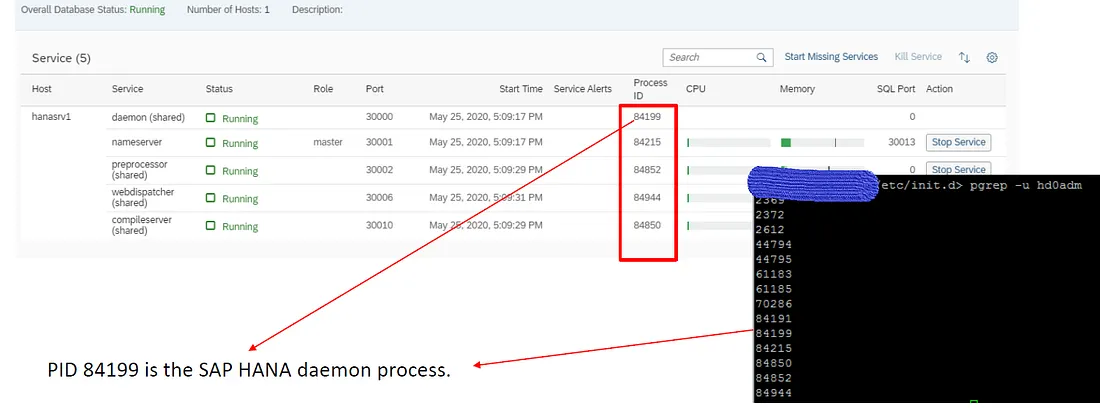
另外在scale out的架構下,主機的 Auto failover是需要有備用機的(如下圖),在這個架構下standby Host是沒有任何資料也不接受任何服務要求的。而有問題的主機一但被修復後可以重新加入這個群組內變為standby的主機。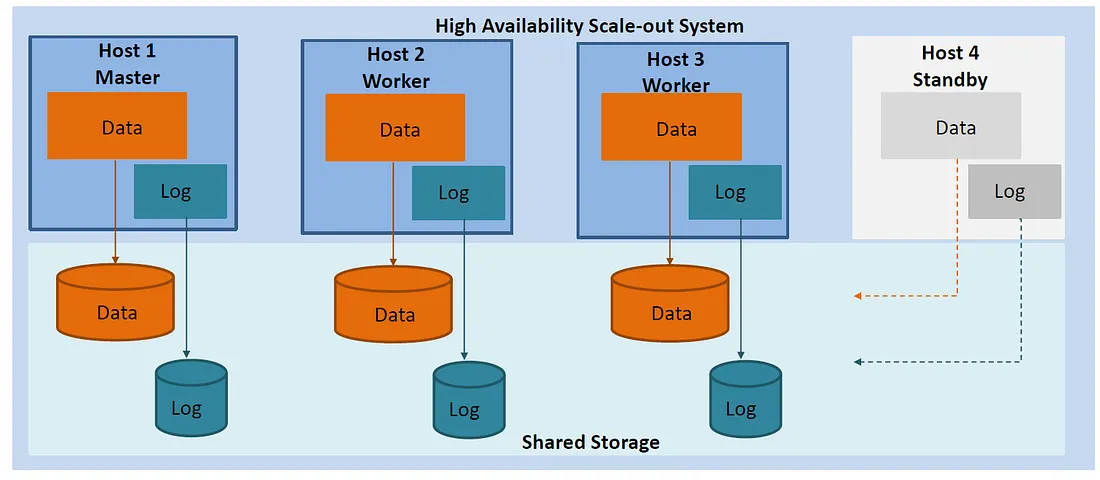
接下來我們來看一下scale up and scale out的高可用度有甚麼不同
一般我們會使用scale out的架構無非是為了突破hardware/OS的極限,以達成效能與資料的擴增(不過hana的架構是需要shared storage不管是NAS or SAN).哪如果是scale up的HA會使用到system replication而scale out通常都會有備用機(如上圖)否則你的scale out架構就沒有HA的功能了。相對system/services recovery來說 scale out就會比較快。
scale up 的效能就是取決於該台的機器效能,但scale out就會有很多參數可以設定。因為你可能不是每台主機的規格大小一樣,有時可能會用到既有設備與新設備混和。所以每台的處理能能力可能不同。在更進一步講述HANA的HA之前我們要來稍微解釋一下在scale out的架構下table的分散模式。
Table Partitioning
如下圖,我們可以將table 分散到各個主機處理,例如依日期分配(可能是年份在table某個欄位有記載年份)或是地點。懶一點的話可以用hash的方式(但需要有某個欄位加料進去)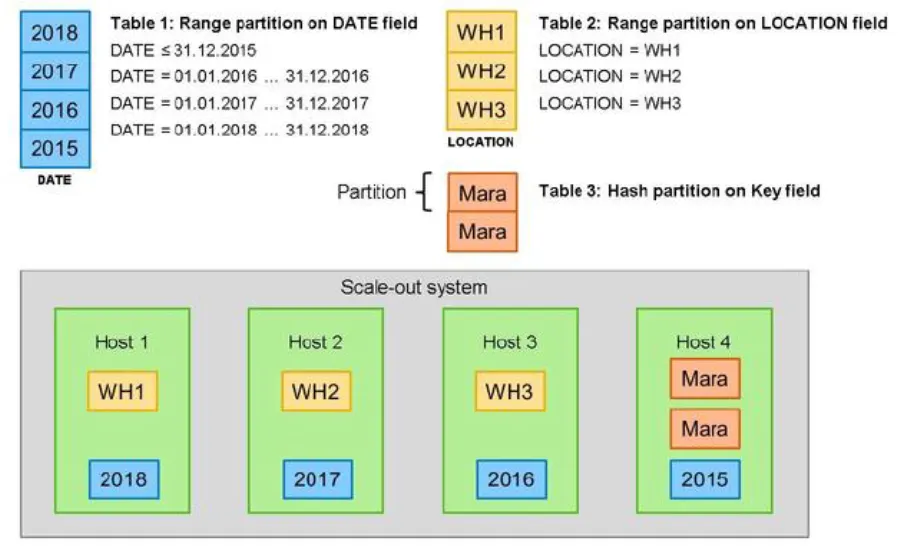
根據這樣的方式table partitioning有幾個好處
分散負載,如同時讀取大量資料
1.column table的size可以被限制,單台主機每個column最多能處裡20億筆資料,也就是說如果你是scale up架構只能到這個極限。
2.利用多主機的多個CPU同時處理資料
3.因為多主機分散資料,我可以讀取我只想要的資料(針對某些主機)
4.因為多主機所以Delta merge的效果更好(有關Delta Merge可參考其他篇章)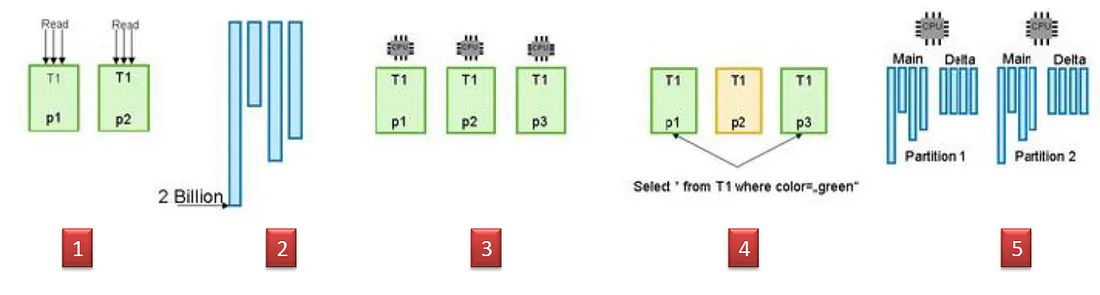
哪Best Practices是甚麼呢?
1.每個partation 的資料筆數不要超過 1–2億筆
2.每個table的partation "最好"不要超過八個
3.若你有某個column會經常用來做 SQL “Where”的篩選,哪你應該用這個當作range partition的主要區分
4.經常會用到join的同一個table schema與你在使oin多個column時會用到 "ON"語法的都應該要做partation
以上都是SAP文件中建議的最佳實踐,但這也只是建議。若要不遵守這個建議當然也可以,就是用更大更多的CPU/Memory/HDD/網路卡來撐。
 不明
不明
