這一系列的文章我們會說明使用HANA modeler 為 HANA DB上的資料建模,這一套工具包含了圖形化的建模方式並且能讓你在建模過程中修改資料並儲存整個建模流程。
哪甚麼是資料建模?
簡單來說就是對資料”提取/精煉/裁切”成一個具有一的資料,這個有意義的資料能讓我們有依據的做出"決策/決定"。這個建模過程中會伴隨很多的資料模擬,可能有客戶/產品/銷售等等與之相關的資料。最後分析出來的資料在SAP這邊稱作 Information views。
這個Information views會依據我們的業務上的use case結合各式不同類型/型態的資料,最後產生的資料內容會分成兩種特性:
使用modeler除了可以做到一開始提到的功能之外,我們還可以使用這一套工具設定製作出來的模型那些人/角色可以使用它。還能建立決策表格,這一個決策表格是使用既有的商業規則套入建模程序中,這個方式可以讓我們達到組織的決策自動化。這個information view有三種型態,
SAP HANA是一套In-memory的DataBase(詳情有興趣的讀者可以看此blog其他的SAP HANA介紹)。使用SAP HANA平台的關鍵問題是:
你如何將在資料的移動最小化?
在HANA中你的分析資料如果都會是在Memory中(並能同時使用CPU的多核心同時處理資料),你的得到的分析效能將會比起你將分析資料在硬碟與memory搬來搬去的分析中快上很多倍。
Column based的儲存
HANA同時可以支援 row based and column based的資料型態。row based的資料型態就如大家所知的table(一個有順序的紀錄資料表)。但以電腦的memory結構 來說column based的分析效能會比row based的效能來得更好,並且能夠比row based的資料提供更有效的資料壓縮,因為column based的資料性質要嘛不是一直重複要嘛就是相近的值,可參考下圖範例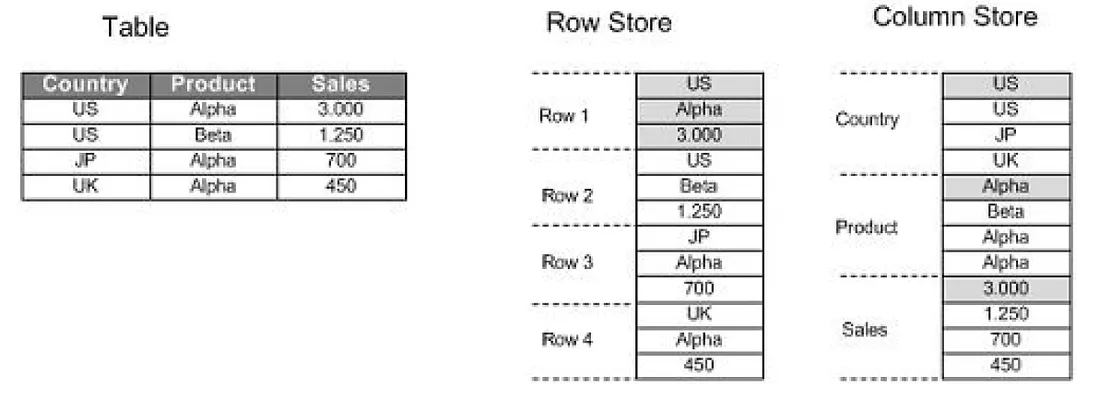
HANA使用了好幾種壓縮方式(run-length encoding/cluster coding / dictionary coding),像 dictionary coding儲存資料是用 sequences of bit-coded integers,這意味著可以對整數進行相對性檢查。例如在執行string vlaues的table scan or join時,它的效能會比用比對得來的快。
另外在大多數的狀況下column based的資料型態是不需要有"額外"的index,因為cloumn based本身的資料型態就已經"內含"index了(特別是dictionary 壓縮法)。在這種狀況下資料庫的讀取效能是非常高的。去除額外的index可以減少資料庫管理工作與定義與維護資料庫的metadata。
平行處理
HANA是被設計來使用分散式系統下的數百顆CPU平行處理來做一些基本分析計算,像是analytics joins/scans/aggregations等。以單一的column來說,在memory 內處理searching/aggregation效能會比row based好(因為記憶體的連續性的儲存資料更適合column based)。若是high spatial locality的資料,CPU的cache處理效能也會比row based的效能好。因為row based是集合很多coulmn的,在處理單一個row時不像處理單一個column,這個row內的coulmn是被分散到不同的cpu/memory處理後再將資料集合起來。
在coulmn based儲存方式中資料已經是vertically partitioned,意思是雖然處理多個coulmn可以同時被多個CPU處理,但若同一個column過大我們還可以再切開給另一個CPU處理(如下圖)。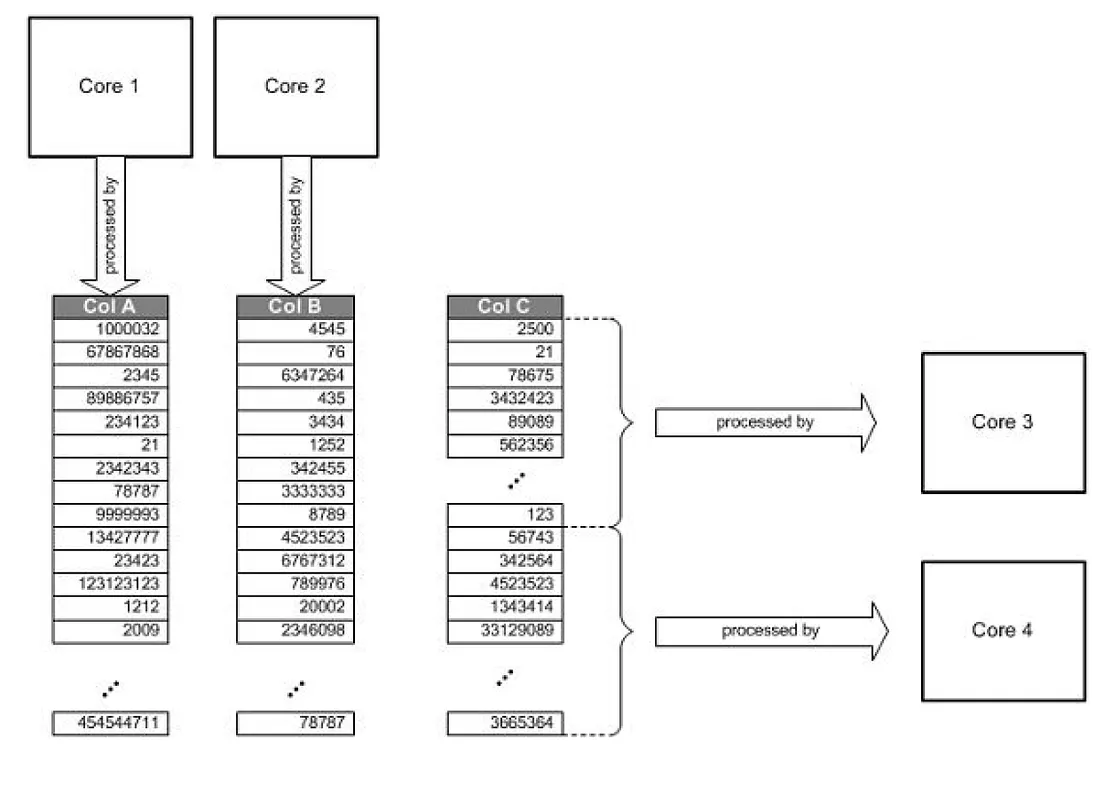
HANA使用了好幾種壓縮方式(run-length encoding/cluster coding / dictionary coding),像 dictionary coding儲存資料是用 sequences of bit-coded integers,這意味著可以對整數進行相對性檢查。例如在執行string vlaues的table scan or join時,它的效能會比用比對得來的快。
另外在大多數的狀況下column based的資料型態是不需要有"額外"的index,因為cloumn based本身的資料型態就已經"內含"index了(特別是dictionary 壓縮法)。在這種狀況下資料庫的讀取效能是非常高的。去除額外的index可以減少資料庫管理工作與定義與維護資料庫的metadata。
平行處理
HANA是被設計來使用分散式系統下的數百顆CPU平行處理來做一些基本分析計算,像是analytics joins/scans/aggregations等。以單一的column來說,在memory 內處理searching/aggregation效能會比row based好(因為記憶體的連續性的儲存資料更適合column based)。若是high spatial locality的資料,CPU的cache處理效能也會比row based的效能好。因為row based是集合很多coulmn的,在處理單一個row時不像處理單一個column,這個row內的coulmn是被分散到不同的cpu/memory處理後再將資料集合起來。
在coulmn based儲存方式中資料已經是vertically partitioned,意思是雖然處理多個coulmn可以同時被多個CPU處理,但若同一個column過大我們還可以再切開給另一個CPU處理(如下圖)。
傳統上的應用程式都會使用materialized aggregates的方式在每次對aggregate data進行write的操作時都會立即或定期的將這些資料計算並儲存。這麼做的原因是為了在讀取資料時的效能能更快速,不用再每次讀取資料時重新計算一次。但HANA在大部分的狀況下可以免除這種做法,簡化了資料建模與寫程式時多出來需要考慮的資料聚合問題(HANA的聚合資料永遠都是最新的)。而之前提到的三種information views也都是non-materialized views。
SAP HANA Database Architecture
HANA系統包含了多種的資料連結服務(像是一般ODBC/JDBC等)與使用SQL語法管理與查詢資料,下圖為一般的Application要連結到HANA DB時的架構圖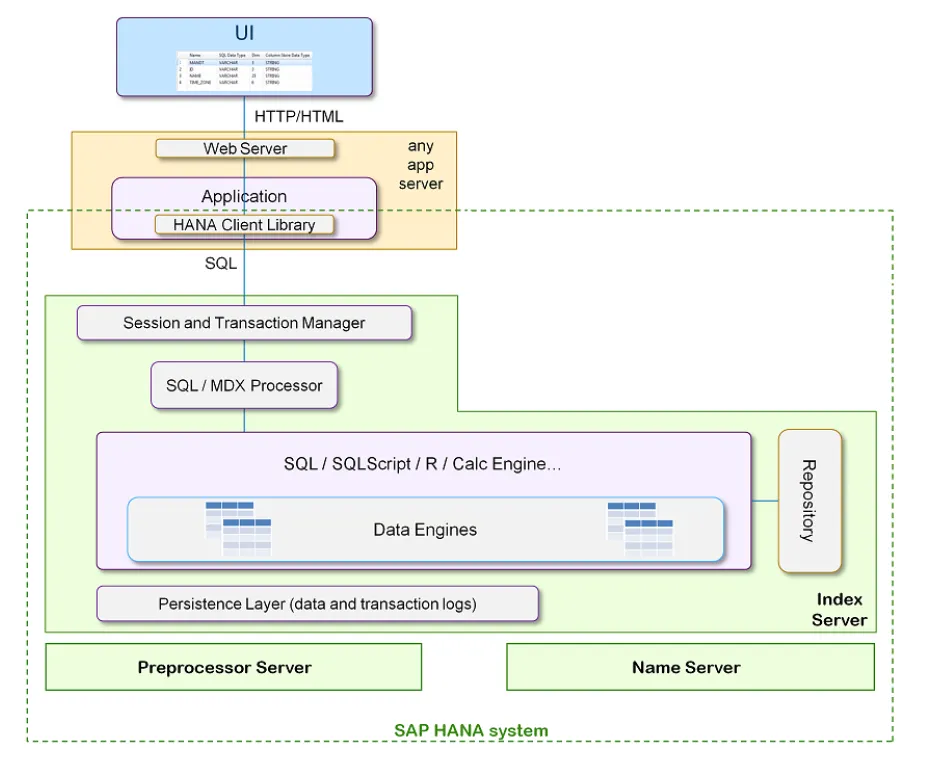
上圖中,Index server是實際儲存資料並有engine來處理資料。 index server可以使用處理SQL 或 MDX(Multidimensional Expressions)語法來處理資料。HANA也有自己的scripting language稱作 SQLScript,它是用來處理"資料密集"的Application logic。傳統的應用程式習慣將資料copy 到Application server處理後再傳送回DB,這造成了程式效能不彰的問題。比較好的作法是將所有資料要運算的事全部都在資料庫中處理,Application只要得到最後的運算結果就好。為了達到這樣的功能,HANA提供了兩種functional libraries讓Application能夠運用SQLScripts的功能將所有資料運算處理的需求全部都在HANA DB中完成。這兩種方式是SAP HANA Business Function Library (BFL) 與SAP HANA Predictive Analytics Library (PAL)。我們在上圖中也可以看到HANA DB也支援R語言分析。
建模流程
HANA的建模基本流程如下
資料特性: Attributes and Measures
我們之前提到information views的資料特性有這兩種(Attributes and Measures),而這兩種特性可以再細分成以下這幾種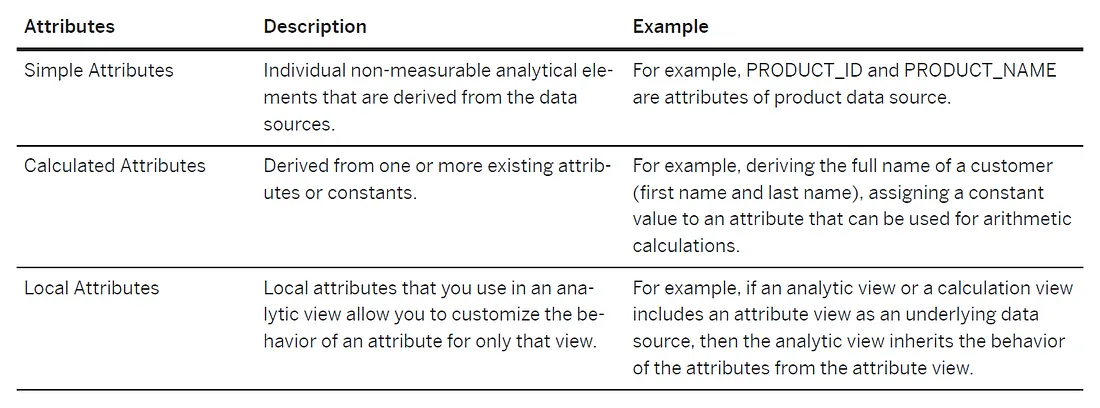
定義來源端的Table Definitions(table schema資料表結構)
通常透過ODBC到source system去取得資料表結構,這邊有兩種模式:Mass import and Selective。 Mass 就是來源端有甚麼欄位就ㄧ併複製過來,selective就是可以選擇要複製的欄位。
載入資料
有了資料表結構後就可以載入資料了。這邊有兩個階段
另外HANA也可以讓你上傳一般的檔案資料表(csv/xls/xlsx等)至HANA DB。這裡會有兩種狀況:
實作 Information Views
Information View是用來作為分析資料之用,我們之前提到三種Information View : attribute view, analytic view, and calculation view。
你可以在SAP HANA Modeler執行這件事(non Materialized View) 。
大多數的商業分析都與時間順序有關所以我們需要先在HANA上產生 Time Data以便在製作informatiom view時加入 time dimension。你可以在system schema中的 _SYS_BI schema中產生。在HANA Studio中的Quick View尋找 Generate Time Data開始製作,過程中你可以選擇的Calendar type(有兩種,Gregorian 與 Fiscal)然後選擇一定的時間區間。
若是 Gregorian最後你會看到有這幾個table會出現:
M_TIME_DIMENSION_YEAR,M_TIME_DIMENSION_MONTH,M_TIME_DIMENSION_WEEK, M_TIME_DIMENSION。
Fiscal calendar則會是: M_FISCAL_CALENDAR。
Attribute Views
基本上這就是將兩個(或以上)有關係(attribute data一樣的)的table join在一起,最終會是一個single dimension view。這個attribute view可以再加入fact table變成Analytic View。
舉例來說這個attribute view可能是員工資料join部門資料,再加上銷售資料就會變成是analytic view,在這過程中你可以將分析的資料階層化以方便視覺化與分析。你可以根據資料的attributes來分階層,HANA提供了兩種階層方式(分別是Level hierarchies and Parent Child hierarchies)。Attribute View中的data不會包含有任何的measures(這在analytics view才會出現),attribute view就是單純的把一些描述性的資料join起來並做一些欄位的篩選而已。HANA在這裡support三種attribute View:
Standard:
來源的table的attributes 是甚麼在這個join出來的結果該欄位的attributes你是可以修改的。
Time:
前面提到了關於時間方面的attributes.
Derived:
這與Standard不一樣的是join出來的欄位attributes是不可以修改的,唯一可以修改的是對於該attributes的描述。
Analytics views
之前提到Analytics View就是attribute view加上measures, measures其實就是使用SQL語法對欄位中的資料做計算或是一些限制,measures是要被aggregate起來的。例如使用SQL功能中的SUM(<欄位名稱>)/MIN(<欄位名稱>)/MAX(<欄位名稱>)。一般的欄位可以把它當作常規屬性不需要去aggreate它。在過程中,Property中的Data Category可以選擇 Cube or Dimension兩種,差別在於若是選擇Dimension則不會有多一個aggregation 欄位可以讓你對資料做運算。
Native HANA Models
前面提到的attributes views and Analytics views都是一般傳統所有DB都可以做的事情,但這兩種方式在HANA studio中都會有效能上的問題並且有時需要高度的SQL語法技巧來協助完成分析,而Native HANA models使用了 HANA的 XS Advanced(XSA)環境內的 Web IDE提供了視覺化的calculation view的功能來完成複雜的 OLAP資料分析(像是視覺化的拖拉建立分析的 data pipeline),這種方式提供了非常多的選項來增強分析效能(因為提供了calculation engine)。有關於此種模式我們會在其他文章中說明。
Calculation Views
此種方式是結合attribute views and analytics views的所有功能與特點,並多了advanced data modeling logic的功能是前面兩種information views做不到的。例如,你可以做出階層式的邏輯/數學運算來自多個不同的tables。calculation view可以使用視覺化的模式拖拉所有的功能/資料來建立,另一種是用SQL scripts腳本式的方式來製作。calculation views的基本特徵如下
1.同時support OLAP與OLTP models
2.支援複雜的SQL語法(如 IF, Case, Counter)
3.可以針對Attributes/Analytics views或其他的calculation views重複使用這些資料再次分析成新的views.
4.支援analytics view的privileges views(例如限制某個使用者看到某個table的columns資料)
5.支援SAP ERP的特殊功能(例如: client handling, language, currency conversion)
6.可以從多個table中combine facts
7.支援額外的資料流程處理功能(例如: union, explicit aggregation)
8.leverage row and column tables
剛剛提及到的calculation engine雖然可以加強分析效能(因為跑在runtime),但是它有時的分析結果有時會與一般典型使用SQL法使用者所期望得到的結果會不相同。主要在於calculation views是一個instantiation process。原因在於在instantiation process中會簡化分析過程中所需要的資料。
在使用視覺化的calculation views的過程中HANA提供了不同的view node功能如下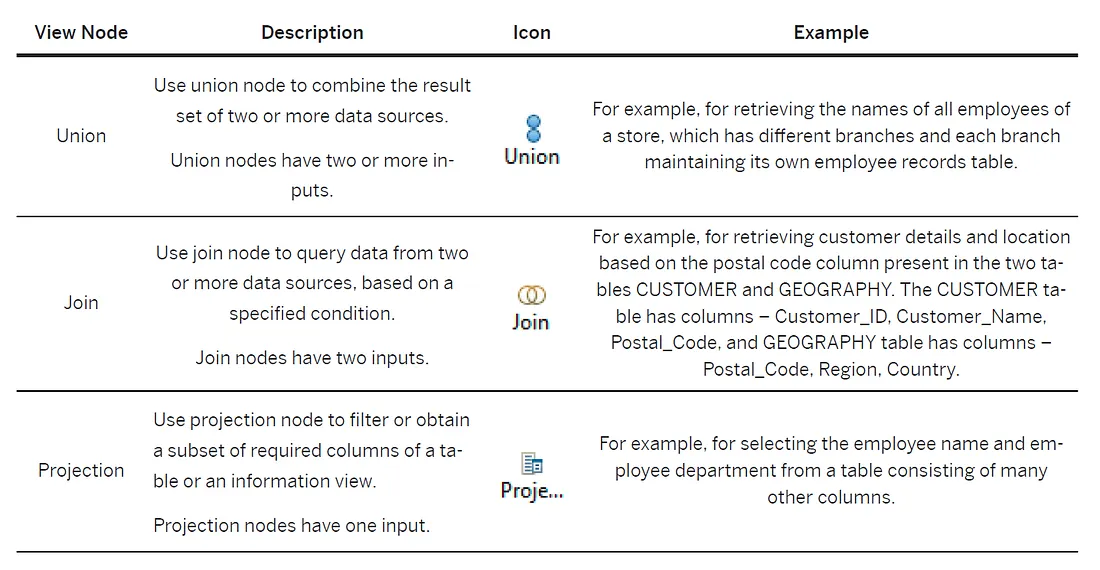
 不明
不明
