我們在Part 1提到AWS的大數據分析中會分為四個資料的收集,處理,儲存與分析。在收集,處理,分析階段都必需要從儲存的地方提取資料才能接下來後續的作業。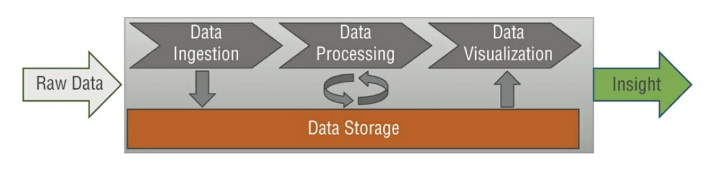
本篇我們將介紹AWS不同的儲存服務,像是 S3, DynamoDB, DocumentDB, Neptune, TimeStream, FXs fir windows, FSx for Lustre與 Storage Gateway。每一項的儲存服務都適用在不同的場景中。
下圖展示AWS不同的儲存服務適合的的應用。至於下圖中的General Storage我們只會介紹S3的部分。 EBS(像是VM掛載的HHD)與EFS(AWS提供的NAS服務)則不會討論,因為我們的焦點在於如何使用AWS的儲存服務來實現數據分析。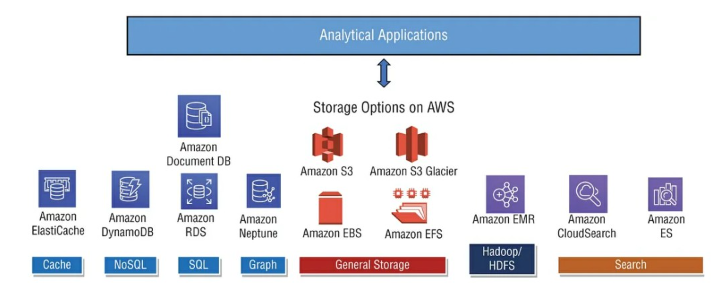
AWS S3(Simple Storage Service)
這是一個AWS提供的Web service,S3提供了 console與API的方式來讓我們與S3的服務互動。簡單的來說我們在S3的儲存中止會看到兩種東西,一個叫做bucket,我們可以把它看成是電腦中的資料夾(不過技術上不是只是使用邏輯看起來會是)。另一個則是object,我們真正把檔案放上S3的名稱。當然在bucket中我們可以再create類似子資料夾的目錄(不過技術上也不是這樣)。
甚麼是Bucket?
buckets的名稱必須具又全世界的唯一性,因為我們取的bucket 名稱後,S3會在這個名稱帶上網址。而每個bucket的範圍是region level。Bucket的命名規則是
甚麼是Object?
就是我們放上去的各類型檔案。每一個Object都會有一個稱為key,也就是這個Object的Full path。像是
<我們的bucket name>/my_file.txt
<我們的bucket name>/my_folder/sub_folder/mt_file.mp3
每一個單一Object(也就是我們放上的檔案)最高可以到5TB的szie。不過建議當我們要用網路上傳大於5GB的檔案時可以用multi-part upload的方式,這是一個用AWS提供的工具上傳時,它會把檔案分成多個部分同時上傳。不管哪個部分檔案先到S3,最後S3會在把所有的部分檔案組合起來。這麼做可以加快上傳速度。每個Object都會有metadata(key-value pairs),而我們也可以對Object貼上Tag來作為其他識別管理。而S3上的Object也可以有版本,意思是如果我們對同一個檔案再上傳一次(不論檔案內容有沒有不一樣),S3都可以幫我們保留上一個檔案版本。
S3的資料一致性模式
S3提供了對Object的 PUTs, GETs, HEADs, DELETEs等操作,但因此基於這些操作我們在S3上的Object的資料一致性會呈現不同的狀況(S3是一種分散式的儲存服務)。
PUTs 操作+ 新的Object,這種是 read-after-write consistency。所有人讀取的都是同一個檔案版本。
HEAD或GET Key name(通常是object有存在),S3提供的就會是read-after-write的最終一致性。
如果是用PUTs來overwrite object或是DELETEs,S3提供也是最終一致性。
若是Update 單一個Key,在S3這是屬於atomic,也因此當我們update單一的key的同時若有其他人來讀取資料,就可能會讀到舊的檔案。
為什麼會有以上這種現象呢?因為S3在底層是一種分散式架構,意思是當我們對S3做一些檔案操作時底層的storage需要時間將資料複製到其他實體的storage。所以造成了若對檔案replace 或delete之後又要立即再讀取該檔案的話,S3可能就會回傳一個舊的檔案,具體取決於變動傳播的狀態。以下會有幾種狀況發生:
List-after-Write 如果我們在放上一個Object(就是檔案),"立刻"要在S3 list key(也就是看到該檔案的列表)。但我們可能有時會看不到該檔案的列表,需要到整個檔案狀態的傳播完成。
Reads-after-write 當我們取代或更新一個object並立刻嘗試讀取它,如果傳播狀態還沒穩定時我們可能就會讀取到這個檔案。
Reads-after-deletes 當我們刪除一個object並立刻嘗試讀取它,如果傳播狀態還沒穩定時我們可能就會讀取到這個檔案。
List-after-deletes 當我們刪除一個object並立刻嘗試list它,如果傳播狀態還沒穩定時我們可能就會list到這個檔案。
S3 storage 的級別
S3 storage依據不同的使用狀況會有不同的使用級別,會分這麼多級別最重要就是費用的問題。你越不想分得哪麼清楚使用S3的服務費用就會越多,相反的你分得越清楚使用狀況費用就會降低。以下為S3的sotrage 級別
S3 Standard-General Purpose
這是預設的使用級別,資料存放在這個級別的Durability是99.999999999%(資料會同時存在於AWS region的三個AZ中)。11個九的durability意味著要65萬九千年我們才會損失一個檔案,並提供 99.99%(per year)的availability。這種級別的storage適合放Production會用到的資料。
S3 Standard- Infrequent Access (IA)
顧名思義就是我們不會經常用的的檔案,但是要取得時是很快的。但意味著放在這裡的檔案我們的對data 的access cost會比general purpose還要高,但儲存費用低於General purpose。它的data durability的等級與general purpose 一樣是11個9,並橫跨三個AZ。Availability是 99.9%。這種級別的storage適合放Backup或Disaster recovery會用到的資料。
S3 One Zone- Infrequent Access
Durability一樣是11個9,但因為資料只存放在一個Zone,所以Availability只有99.5%。但它提供的效能與前面兩種一樣都是low latency and high performance。費用基本上會比 Standard-IA便宜個20%。這種級別的storage適合放你可以重製的資料,意思是這個級別的資料損失了也沒有甚麼關係。
S3 Intelligent Tiering
這種算是懶人用的或是組織對資料的週期管理沒有Policy的,又想省錢的就可以用這種。這個服務會根據資料的使用狀況自動移動資料到便宜或貴的storage。Durability與General Purpose級別是一樣的,Availability則是99.9%。
S3 Glacier
這是檔案需要長期歸檔的使用級別。若讀者跟我一樣是IT的老鳥可以想成我們以前在傳統機房用的磁帶,備份完成後要叫快遞拿到特殊的倉庫存放的哪種服務。這個服務通常是為了法規法令或組織業務的要求長期存放的(可能一放要放10年的哪種)。提供的Durability一樣是11個九,但儲存費用便宜很多(每GB是0.004 USD)。但相對的要資料取出來就要收你比較多的錢了,而且取出資料的時間需要等待。
在Glacier有兩個術語概念,一個是Archive另一個是Vault。Archive是Glacier裡最基本的單位(你可以把它看成是一個個的磁帶),可以是任何類型的檔案。每一個Archive 都會有一個unique ID與optional description。
另一個是Vault,這是一個為archive製作出來的容器。我們可以把它想成地端機房磁帶的防潮箱,通常這樣的分類是依專案,任務或部門來分別的。
S3 Glacier Deep Archive
這種歸檔服務儲存費用又比Glacier在便宜。但資料取出的時間就比Glacier更久。
S3 Glacier有三種取資料的選擇
資料在這至少要放90天
S3 Glacier deep archive有兩種取資料的選擇
下圖為我們的資料存取頻率來決定我們應該放在哪種級別的S3 storage
另外根據不同級別的比較表如下
另外我們剛剛提到,若組織對資料的生命週期管理已經有良好的政策與規則,我們可以使用S3的 lifecycle configuration根據組織的政策與規則自動的移動這些資料到不同級別的storage。
在S3 lifecycle Rules中有兩種動作,一個是transition actions另一個是Expirtion action。 transition是根據規則將資料移動到不同級別的storage,expiration則是根據到期的時間刪除資料。像是刪除放了365天後的資料或黨的舊版本。
而S3的檔案版本功能預設是沒有開啟的,通常在production環境中開啟它會是一個好的作法,防止有人不小心的刪除或修改到檔案讓我們可以回復回來。版本功能的啟用會是在Bucket level。
S3 Replication(複製)
AWS S3提供了以bucket level為基礎的data replication。 要起用replication功能bucket的版本功能必須要被啟動。這個replication可以在同一個AWS region(SRR-same region replication)或不同的Region(CRR- Cross region replication),可以是同一個AWS account或是不同account。這個replication的資料是非同步(asynchronous)的方式。
複製檔案(object)時會一起把object的metadata一起複製過去,且可以複製到不同的storage級別,有可以在replication過程中變更ownership。通常會使用到CRR通常是法規法令的要求或是在不同的國家或區域對access同樣的資料要求同等的低延遲。而使用SRR則是因將logs aggregate到單一個bucket中以進行更簡單的處理,或是為了測試環境所需要的資料replicate一份出來。
S3的存取效能
AWS可以根據存取的需求自動擴展資料的存取需求的(提供的延遲性會在100–200ms之間),但是要根據一些規則才可以,不然會有hot partition的狀況發生。也就是資料的存取全都集中在同一個partition。
S3提供給我們的資料存取操作在一個Bucket中的每一個prefix(就是檔案路徑)的每秒鐘會有至少 3,500次 PUT/COPY/POST/DELETE與 5,500次的 GET/HEAD。而prefix的數量則是沒有限制, 例如我們有以下四個prefix
bucket1/folder1/sub1/file
bucket1/folder3/sub3/file
bucket1/2/file
bucket1/4/file
在同一個bucket下有四個prefix,所以如果我們讀取資料(GET/HEAD)在這四個prefix是平均的話我們就可以有 5,500 x4 = 22,000request(每秒)get/head資料的能力。
S3的Partitioning, 壓縮, 與檔案格式
之前我們提到S3提供高效能的存取與較低存取費用,最主要的技術是靠partitioning,壓縮與選擇最佳的檔案格式。最佳的檔案格式應該是可以被壓縮的,這樣儲存空間才會佔比較小,並且這樣做實質上也會增加在進行資料分析的查詢效能(例如用Athena查詢在S3裡的資料)。在S3中儲存的最佳格式的檔案是Apache Parquet(我們當然也可以存放CSV,JSON等其他任何的檔案在S3中),這是一個用來設計查詢大量資料的壓縮的columnar storage 格式。當我們要對在S3裡的資料做查詢(Query)時會有兩種費用產生。
對資料進行partition對效能和成本有類似的影響,因為通過對資料進行partition,我們可以限制每次查詢掃描的資料量,從而提高效能並降低成本。 雖然我們可以使用任何column來對資料進行partition,但基於資料和時間進行partition通常是一種好的做法,這會產生多個等級的partition。 例如,我們可以將信用卡交易存儲在S3中,並且我們可以基於年、月、日和小時進行partition。 這種partition模式將改進在特定時間變量上過濾資料的查詢,從而減少掃描的資料並提高性能。 測試顯示,這可以使查詢速度提高 70%,掃描成本降低 90%。
壓縮提供了類似的效能提升,因為要掃描的資料較少,因此 S3 和分析工具之間產生的網路流量也較少,從而也降低了總體成本。然而,選擇可拆分的壓縮格式很重要,因為拆分檔案允許execution engine通過使用多個讀取器拆分檔案的讀取,進而增加查詢的整體parallelism。不可拆分的檔案會對查詢效能產生負面影響,因為只有一個讀取器可以讀取資料,而其他讀取器則處於閒置狀態。這是分佈式運算中最常見的問題之一,其中worker之間的工作負載不均勻且嚴重傾斜,並影響系統的整體效能。下表列出了最常見的壓縮演算法、它們支援的壓縮比、壓縮過程中算法的速度以及它們的最佳使用。例如,Gzip 是一種非常常用的壓縮方式,它最適合raw存儲,因為它具有很高的壓縮率;然而,由於其不可分割的性質,它不適合平行處理。
加速上傳至S3
AWS提供了以下兩種方式(使用網路)加速我們檔案的上傳,若覺得還是不夠快可以使用AWS的Snowball系列。
Multi-Part upload
這是將檔案拆分成小的檔案同時傳送至S3,檔案本身有100MB以上就可以拆分了,若是5G以上就一定要強制拆分。
S3 Transfer Acceleration
簡單來說就是將檔案傳送到離你最近的AWS Edge location,然後AWS會用自己的專線送回Bucket,這個方式也能跟Multi-Part upload搭配加速傳送
DynamoDB
這是AWS的全託管式,具高可用(HA — replication across 3 AZ)的NoSQL DB服務。可以承受大規模工作負仔的分散式DB。每秒百萬次的request,每次request可以存取萬億(trillions)的row。
Data Type
DynamoDB的table支援不同屬性資料型態,主要分為三種: scalar, document, 與Set
Scalar Data Types
它呈現的是一個value(exactly one value)。scalar type會有number, string, binary, Boolean跟null。下表為每個data type的詳細說明。
Document Data Types
這種呈現的是一種具nested attributes的複雜結構 — 像是我們常看到的JSON結構資料。document type有兩種: list與map。雖然DynamoDB可以支援這種的資料型態,在這種資料形態裡的數字(number)就不會像scalar中的Number有其限制。唯一的限制就是DynamoDB的每一個Item最多只能有400KB。
attribute value不可以是empty set(string set, number set, binary set),但 empty list 與 maps是允許的。下表為每個data type的詳細說明。
Set Types
這裡呈現的其實是多個scalar values,所以才說是一個Set。 set types有 string set, number set, 與binary set。同一個Set裡的Value屬性需要一樣不可以混不一樣屬性的value。這裡跟document type一樣 number的長度沒有限制,並限制在一個Item不能大於400KB。在Set裡的value都是要unique的。set中value的順序不保留; 因此,我們的Application不得依賴於set中元素的任何特定順序。empty sets是不支援的。以下是一個string set, number set, binary set的範例
[“A”,”B”,”C”]
[123,456,78,999]
[“U3Vubnk=”, “UmFpbnk=”, “U25vd3k=”]
DynamoDB的核心觀念
Tables/items/attributes/partition keys and sort key為DynamoDB的四個核心概念。
Tables 這跟一般其他的DB概念差不多,是一群資料的集合(collection)。一樣是將資料存在table裡,並包含了很多個items.
Items 概念像是一個row,一個 tuple或是關聯式DB中的records,items是一組多個屬性,這些屬性(attributes)在tables中的其他items中是唯一可識別的。
Attributes 每個item可能都會有一個以上的屬性。attribute類似關聯式DB中的field or column概念,attribute可以有null。
Partition Keys and Sort Keys 在Item中的第一個屬性是partition keys。從效能角度來看,partition keys非常重要,因為它被用作內部hash function的input,其output決定了這個item在 DynamoDB infrastructure上的物理存儲位置。 item中的第二個屬性是sort keys,它是選用的,用於按sort keys/values順序對資料進行排序。 具有相似partition keys的items存儲在一起以提高效能。 如果兩個items具有相同的partition keys/values,則它們需要具有不同的sort keys/values。
所以parition keys 或 (partition keys + sort keys)這兩種都可以是我們DynamoDB table的Primary keys.
下圖為單獨使用partition keys當作我們的primary keys,在partition keys中的每一個item都是unique。partition keys必須要是diverse,資料才能有效的分佈。
Partition keys + sort keys ,資料是被partition keys給群組起來的。而sort keys就像是range key。例如我們如果經常查詢的資料是依據user id + game id就可以這樣設計(如下圖範例)
secondary index是一種資料結構,它包含來自table的屬性subset和支援Query operation的alternative key。我們可以使用 Query 從index中檢索資料,這類似於對table使用 Query。一個table可以有多個secondary index,這使我們的應用程式可以存取許多不同的query patterns。每個secondary index都與一個table相關聯,從中取得資料。這稱為index 的base table。創建index時,我們可以為index定義一個alternative key(partition keys與sort keys)。還可以定義要從base table project或複製到index 中的attributes。 DynamoDB 將這些attributes與base table中的primary key屬性一起復製到index中。然後,我們可以像query或scane table一樣query 或scan index。
每個secondary index都由 DynamoDB 自動維護。當我們在base table中添加、修改或刪除Item時,該table上的任何index也會update以反映這些更改。
DynamoDB支援兩種型態的 secondary index:
Local Secondary Index(LSI)
LSI 是與base table具有相同partition keys但sort keys不同的index。 LSI中的是"本地"的,因為LSI的每個partition都限定為具有相同partition key/value的base table partition。 任何一個partition key/value的indexed items的總量不能超過 10 GB。 LSI與為被index的table提供的throughput相同。 每個table最多可以定義五個LSI。LSI在create table就要決定要不要使用。下圖為一個具LSI的table範例
Global Secondary Index(GSI)
GSI 是一個帶有partition keys和sort keys的index(其實在DynamoDB裡它也是個table),可以與base table上的keys和sort keys不同。 GSI被認為是“全域的”,因為對index的Query可以跨越base table中的所有資料,跨越所有partition。 GSI沒有像LSI那樣的大小限制,它有自己的provisioned 的read/write throughput,與原始table分開。可以在table create後對其新增或修改。最多可以為每個table定義 20 個GSI,所以我們可以根據我們會經常Query的attribute(也可以視作欄位conlumn)。以下為一個使用不同的attribute作為partition key來建立index。
甚麼是Partition
Partition是DynamoDB存放資料的地方。所謂的partition是table的存儲分配,底層是SSD硬碟,並在 AWS region內的多個AZ之間自動複製。DynamoDB會完全進行partition的管理,我們不需要知道如何管理partition,只要知道如何選擇/設計良好的partition keys與 sort keys。DynamoDB使用hash keys(使用partition key來hash產生的),並根據資料的大小與已經provision的throughput總量來自動畫分partition。
DynamoDB的 Read/Write Capacity
DynamoDB提供對table的大量資料的讀取能力(Read and Write)並提供兩種對資料的read/write模式: on-demand(彈性變動) 與provisioned(fixed capacity)。
On-Demand Capacity Mode
簡單的說就是我們對Application的需求搞不清楚要多少資源時,DynamoDB就提供我們要多少就給多少的data read/write能力(幾個ms 的latency)。這個模式在create table後也可以事後調整,調整時不須需要變動Application任何東西。所以算是懶人用的。在這邊我們不需要特別計算read/write的能力,DynamoDB會掌控一切,但費用可能會很高(因為我們懶得去計算)。
在這模式下的read / write,DynamoDB把它定義為 Read Request Unit與 Write Request Unit。雖然在這模式是自動的,但是沒有算好的話你的AWS帳單可能會爆掉
Read Request Unit
每個request的Read 資料的大小最大是4KB,如果超過4KB就要額外一次的read request。所以我們的計算我們的資料到底需要多少次的request的因素如下
Item size
Read type(Eventually consistent 與 strongly consistent)
舉例,我們有一個Item 的Size是 8KB,我們可能需要的read request如下
Write Request Unit
每次寫入資料的大小最高是1KB,所以如同read 一樣,Iteam資料寫入超過1KB就需要額外的 write request次數。寫入的資料是1KB的話
On-Demand模式下Dynamodb都會假設你的Application traffic會是兩倍來應對。例如我們的Apllication traffic介於10,000 strongly consistent reads per second 到20,000 strongly consistent reads per second 之間,哪麼DynamoDB就會為我們準備 40,000 strongly consistent reads per second的capacity。如果最高曾來到40,000,DynamoDB就會為我們準備80,000的capacity。
哪為什麼不選彈性的on-demand而有人會選擇provisioned(fixed capacity)呢?除了provisioned可以控制費用不要花太兇,另一個原因在於 "throttling”。因為剛剛講到DynamoDB會為我們準備之前peak time的兩倍的量,但是是在30分鐘的時間區間內,意思是如果Application traffice在30分鐘內是超過兩倍的話,哪DynamoDB就會會進行節流(throttling)。有些Application無法處理這種狀況。
Provisioned Capacity Mode
這跟on-demand mode不一樣,這是固定的資料讀寫的capacity。這表示我們對自己Application讀寫需求是很明確的,並且這麼做也能節省費用。在這個模式下DynamoDB對其table read/write的單位分別是 RCU(Read Capacity Unit)與WCU(Write Capacity Unit)。
Read Capacity Unit(RCU)
因為這是需要先計算好我們Application所需的read能力,所以考慮的因素如下
read capacity與On-demand 一樣每次最大是4KB, 所以讀取4KB所需的read request是
RCU計算範例
舉例一 : 每秒 10 次strongly consistent reads,每次 4 KB的. 這樣要多少RCU呢? 10 * 4KB/ 4KB = 10RCU
舉例二: 每秒 16次eventually consistent reads,每次 12KB的. 這樣要多少RCU呢? (16/2) * (12/4)= 24 RCU
舉例三: 每秒 10次strongly consistent reads,每次 7KB的. 這樣要多少RCU呢? 10 * 7KB / 4 = 20 RCU (其中 7/4無條件進位)
DynamoDB的Read consistency
DynamoDB提供的是region level的服務。也就是DynamoDB中的資料會同時存在一個region的多個AZ中。而這樣就會有資料複寫的問題存在,資料的最終一致性通常會在低於一秒內在所有的AZ中完成複寫。也因為這種資料的寫入延遲,DynamoDB提供了兩種資料一致性的模式,Eventually consistent reads與 strongly consistent reads。
eventually consistent reads我們上面提到因為要等資料複寫完成(約一秒內)如果在這個模式下我們是write-after-read,我們會get到未預期的錯誤,因為底層的data replication還沒跑完。所以read-after-write會有錯誤的狀況發生。但是好處Eventually consistent reads以可能以過時的資料為代價而得到最大throughput。
Strongly Consistent Read: 如果是這種模式做write-after-read就會得到正確的值。在Strongly Consistent Read的情況下,DynamoDB 會返回對最新資料的回應,並反映所有先前成功操作的update。 Strongly Consistent Read的問題在於,如果存在網路延遲或中斷,並且我們無法從global secondary index(GSI)進行Strongly Consistent Read,則該read可能不可用。 GetItem、Query、Scan等read operation提供了ConsistentRead參數,可以設置為true,保證DynamoDB在操作過程中使用Strongly Consistent Read。
Write Capac 10ity Unit(WCU)
這邊一樣是每次write 資料的大小是1KB。而若要達成transactional write request(一次寫入1KB)則需要兩個WCU。
哪當如果我們Application的RCU/WCU超過我們當初的設定呢?這時我們跟on-demand mode一樣會遭遇到節流(throttling)。我們會get到一個an HTTP 400 (Bad Request | ProvisionedThrougputExceededException)的error code。這時我們就需要進行retry的機制。不過如果我們有使用AWS SDK的話,這個retry機制已經寫在裡面了,我們的Application不用處理這一個邏輯。
WCU計算範例(標準的write)
舉例一 : 我們每秒寫入 10個object,每個object 2 KB,這樣需要多少WCU呢? 2* 10 = 20 WCU
舉例二 : 我們每秒寫入 6 個object,每個object 4.6 KB,這樣需要多少WCU呢? 6* 5= 30 WCU(4.6要無條件進位)
舉例三 : ,我們每分鐘寫入 120個object,每個object 2KB這樣需要多少WCU呢? 120/60 * 2= 4 WCU
DynamoDB的Auto Scaling與Reserved Capacity
我們可以選擇使用 DynamoDB 的auto scaling來管理table 和global secondary index(gsi) 的throughput容量。 我們可以定義RCU/WCU的範圍(upper-lower),或該範圍內的目標利用率百分比。 隨著工作負載的增加,DynamoDB Auto Scaling 會嘗試維持我們的目標利用率。
AutoScaling可幫助我們獲得預先配置容量的優勢,同時還能在流量突然激增時進行擴展,以避免應用Application受到限制。 如果我們使用 AWS console創建table或GSI,則預設情況下會啟用 DynamoDB Auto Scaling。
根據前面介紹的RCU與WCU還有甚麼是partition。我們舉以下個圖示範例。每個partition的capacity是固定的(10GB大小,3000 RCU,1000 WCU)。而計算公式如下
 不明
不明

 iThome鐵人賽
iThome鐵人賽