DB內使用非常大量的CLR元件來解析入參 , 雖然目前公司使用的SQL SERVER版本已經有蠻多內建函數可以達到相同效果 , 但物件實在太多所以短期內沒有改寫函數的打算。
近來發生查詢以及更新的sp執行時間都有緩滿甚至time out的情況 , 回頭仔細查看才知道都是跟CLR有關。
這邊先建立大約18萬筆測試資料 , 並建立一個非叢集索引供後續查詢比較效能。
DROP TABLE IF EXISTS IDXS
CREATE TABLE IDXS (
ID INT IDENTITY(1, 1) PRIMARY KEY,
OBJECT_ID INT,
NAME VARCHAR(64),
TYPE_DESC VARCHAR(64),
)
CREATE INDEX IDX_IDXS_NAME ON IDXS (NAME) INCLUDE (OBJECT_ID)
INSERT INTO IDXS (OBJECT_ID, NAME, TYPE_DESC)
SELECT object_id, name, type_desc
FROM sys.indexes
WHERE name is not null
GO 1000
環境內CLR元件解析是把字串輸入後依符號切斷變成直行的資料表 , 比如執行這樣會得到該行資料。
DECLARE @string VARCHAR(MAX) = 'ci_block_id,cl,clidx1,clst,clust'
SELECT *
FROM CLRCutString(',', @string)
| Item |
|---|
| ci_block_id |
| cl |
| clidx1 |
| clst |
| clust |
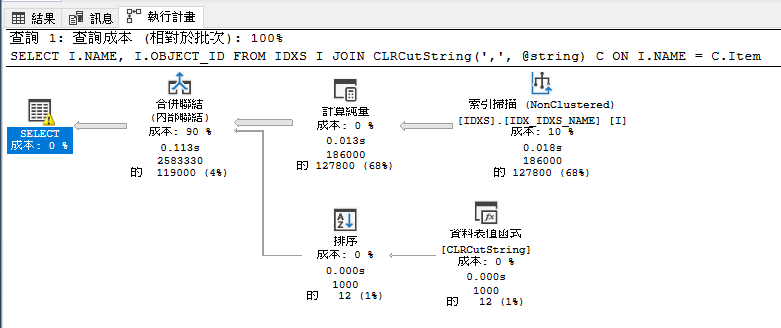
若直接與測試表JOIN其實是無法善用索引的 , 因為CLR透過Table-Valued Function 回傳的欄位型別,必須是 Unicode 型別 (NVARCHAR) 或其他「安全對應」型別,不能直接用非 Unicode 的 VARCHAR。
DECLARE @string VARCHAR(MAX) = 'ci_block_id,cl,clidx1,clst,clust,FFtUpdateIdx,FSTSClusIdx,FSTSNCIdx,IDX_IDXS_NAME,nc,nc1,nc2'
SELECT I.NAME, I.OBJECT_ID
FROM IDXS I
JOIN CLRCutString(',', @string) C ON I.NAME = C.Item
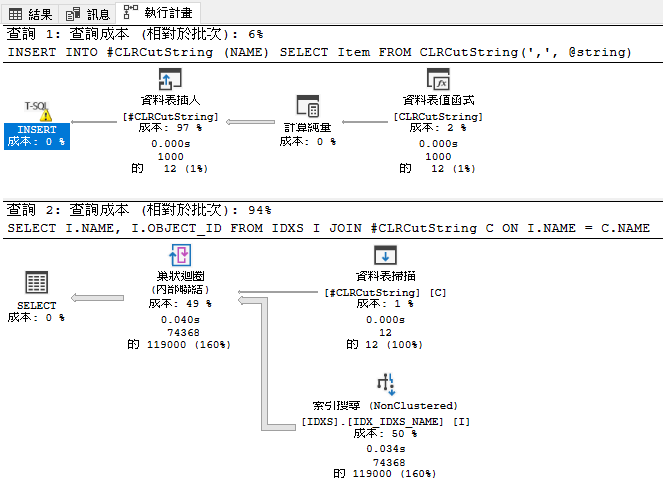
換個做法先把切好的字串寫到暫存表 , 定義好欄位型別與主表吻合就可以避免隱轉 , 查詢自然可以善用索引 , 從SCAN -> SEEK
DROP TABLE IF EXISTS #CLRCutString
CREATE TABLE #CLRCutString (
NAME VARCHAR(64)
)
INSERT INTO #CLRCutString (NAME) SELECT Item FROM CLRCutString(',', @string)
SELECT I.NAME, I.OBJECT_ID
FROM IDXS I
JOIN #CLRCutString C ON I.NAME = C.NAME
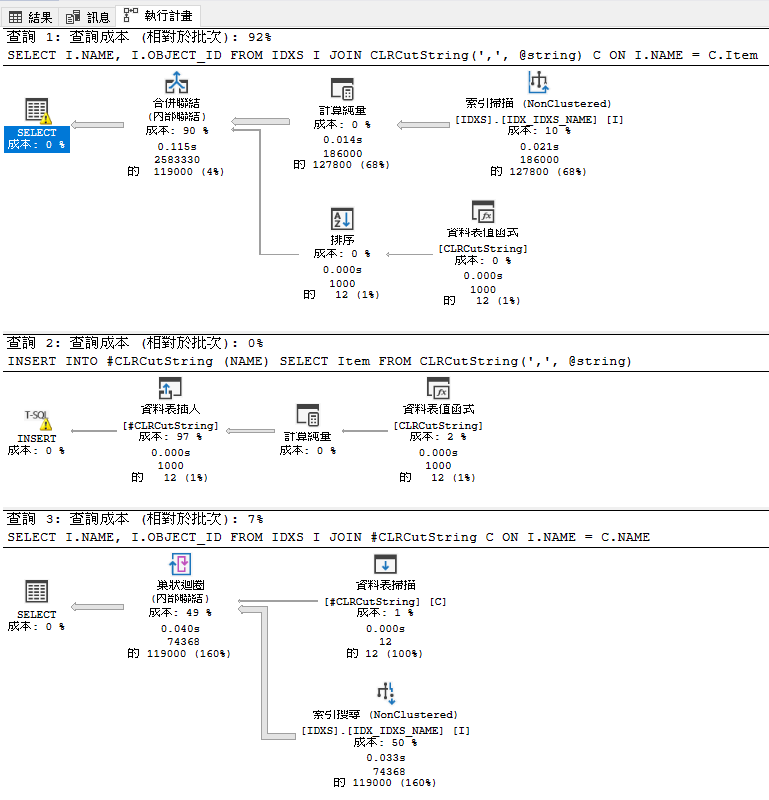
最後附上2者相比的效能圖 , 速度與時間都是優化後的來的好 , 遇到巨量資料情況下這絕對是致命的效能瓶頸或是直接使用string_split() 函數也可以達到相同目的。
 混口飯吃的南部人
混口飯吃的南部人

 iThome鐵人賽
iThome鐵人賽