在RAG系統裡,Embedding是分開編碼(Bi-Encoder),是靠向量相似度找出語意接近的文件。
但這種方法只會算查詢與每個句子的整體語意相似度,並不會精確考慮查詢與文件內容的句法或細節關聯。
這時就需要Reranker(重排序模型)來進行第二階段的精準排序(Re-ranking),重新評估查詢與每個候選文件之間的語意關係。它的工作不是取代Embedding,而是在初步相似度搜尋之後,更精準地篩出真正最相關的句子。
CrossEncoder是一種重排序模型 (Reranker),用來重新評估查詢與文件之間的語意相關性。
我們可以使用SentenceTransformers提供的CrossEncoder進行更準確的語意排序。
Reranker實作: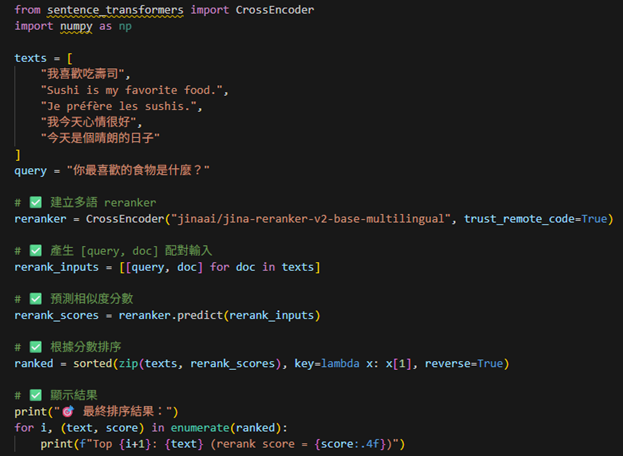
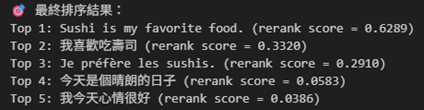
可以看到上一篇我們做Embedding搜尋時,我喜歡吃壽司排在第一。
Reranker加入後,CrossEncoder判斷英文句子Sushi is my favorite food.與查詢你最喜歡的食物是什麼?語意最貼近,所以將它排到第一名。
這代表Reranker能理解跨語言語意,並在第二階段讓搜尋結果更準確。
 妤
妤

 iThome鐵人賽
iThome鐵人賽