在確定現在這個架構以前,我其實重構了很多次。最一開始的版本很混亂,我發現每次只要微調一點功能,就會因為組件之間黏得太死,導致整個程式碼都要大幅度改動。
為了解決這種「牽一髮而動全身」的痛苦,我花了不少心力進行解耦。以下就是我最終整理出來的系統分層與核心邏輯流向圖:
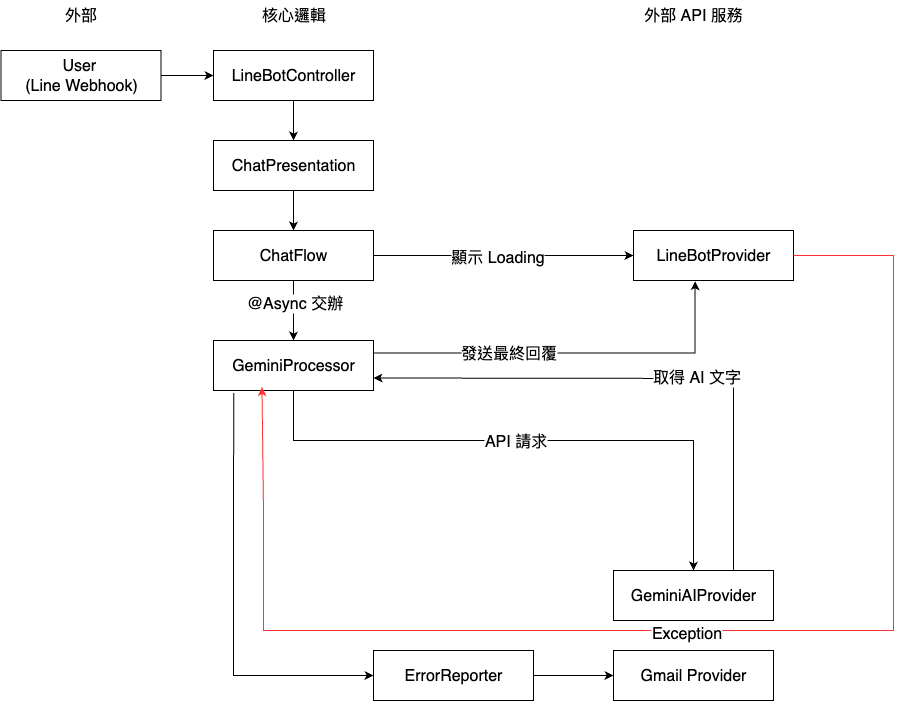
此次重構的幾個核心重點:
讓邏輯歸邏輯,SDK 歸 SDK:
我把所有關於 LINE 訊息包裝的技術細節都丟進了 Provider。現在我的核心業務邏輯(Flow)只負責處理純粹的字串。這對我最大的好處是代碼變乾淨了,如果未來想把機器人搬到 Discord 或 Web 介面,核心代碼幾乎不用動。
多加一個 Processor 當『總管』:
原本 Flow 這一層要做太多事了:要檢查重複訊息、限流、叫 AI、還要負責回訊息跟抓錯誤。我決定把異步處理這件麻煩事交給專屬的 Processor 來管理。
這樣做之後,錯誤處理變好寫了。我不需要在程式碼的每個角落都塞 try-catch,只要在 Processor 這個總管層級統一處理就好。
這是整個系統的「大門」。它的職責非常單純且明確:驗證身份、解析訊息、並監控流量狀態
程式碼實作:
@PostMapping("/callback")
public ResponseEntity<String> callback(
@RequestHeader("X-Line-Signature") String signature, @RequestBody String payload) {
try {
// 1. 安全驗證:透過 LINE SDK 確保請求合法性,避免非法調用
CallbackRequest callbackRequest = lineParser.handle(signature, payload.getBytes());
for (Event event : callbackRequest.events()) {
// 2. 系統診斷:監控 Webhook 網路延遲,這對 AI 即時回覆的體驗至關重要
log.info("Webhook 傳輸延遲: {} ms", (System.currentTimeMillis() - event.timestamp()));
// 3. 現代語法:使用 Pattern Matching 快速篩選文字訊息並交辦
if (event instanceof MessageEvent msg && msg.message() instanceof TextMessageContent text) {
chatPresentation.sendChatMessage(convertToDto(msg, text));
}
}
return ResponseEntity.ok("OK"); // 快速回應 LINE,避免超時重發
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.FORBIDDEN).build();
}
}
設計要點:
刻意引入 ChatPresentation 是為了將來自外部的請求轉化為系統內部的 Domain Command。這樣做能確保核心邏輯(ChatFlow)與通訊平台完全解耦,即便未來專案要從 LINE 遷移到 Discord 或自建 App,我也不需要動到任何核心的 AI 處理邏輯
ChatFlow 就是系統的調度中心。在 AI 應用的場景中,我們面臨兩個挑戰:
程式碼實作:
public void execute(Command command) {
String msgId = command.getMessageId();
String userId = command.getUserId();
// 1. 去重檢查 (Deduplication):10秒內重複的訊息 ID 直接擋掉,防止 Webhook 重試機制
if (duplicateLock.getIfPresent(msgId) != null) return;
duplicateLock.put(msgId, true);
// 2. 限流檢查 (Rate Limiting):5秒內禁止同一使用者重複請求
// 確保 AI 在生成回覆時,系統不會被同一人的新訊息干擾
if (userBusyLock.getIfPresent(userId) != null) {
log.warn("[限流] 使用者 {} 正在輸入中,跳過新請求", userId);
return;
}
userBusyLock.put(userId, true);
// 3. UX 優化:立即發送「顯示中...」動畫,提升使用者體驗
lineBotProvider.showLoading(userId, 30);
// 4. 異步派發:將耗時的 AI 運算交給 Processor,並在完成後釋放鎖定
geminiProcessor.processAsync(command, () -> {
userBusyLock.invalidate(userId); // 任務完成,允許下一次輸入
});
}
訊息去重機制:
狀態鎖定:
非同步與回調:
優化 UX 擬人化的互動細節:
 loby84625
loby84625

 iThome鐵人賽
iThome鐵人賽