系列文章 : [6.1810] 跟著 MIT 6.1810 學習基礎作業系統觀念
在 trace code 之前,可以先學一些 RISC-V 的 CSR,這樣等一下看到 CSRs 的時候,就能知道他們是什麼樣的功能了!
我看的是這一個版本的規格書 : https://github.com/riscv/riscv-isa-manual/releases/tag/riscv-isa-release-8cf4af7-2026-02-28
ch 3.1.6
當一個 trap 發生,讓 y 特權級跳到 x 特權級的時候,mstatus.MPP 會被設為 y。
例如說,當我們從 S-mode 發生 trap 到 M-mode 的時候,那 mstatus.MPP 就會被設定成 S-mode。
另外一種使用方式是 boot 的時候,在 M-mode 可以對 mstatus.MPP 進行寫入,我們可以直接寫入 mstatus.MPP = S-mode,這樣我們使用 mret 指令的時候,就可以跳到 S-mode 了。
note : RISC-V 的世界裡,有三種觸發 trap 的方式
ch 3.1.14
當一個 trap 發生,並進到 M-mode 的時候,mepc 會記錄發生 trap 的 PC ( virtual address )。
另外一種用法跟 mstatus.MPP 很像,我們也可以寫入 mepc 一個位址,這樣子 mret 的時候,就可以去到目標的位址了。
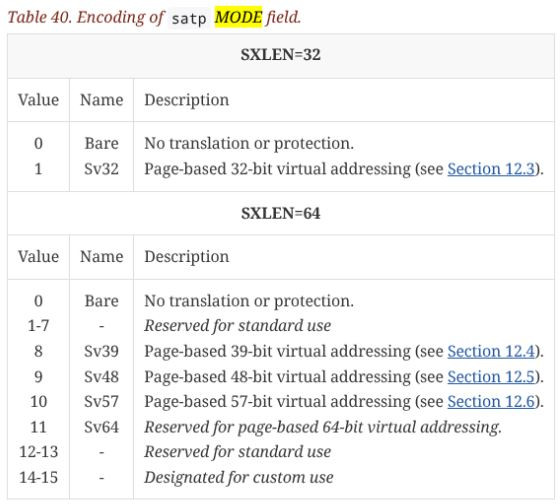
ch 12.1.11
當 satp 設為 0 ,表示 mode 被設為 0,也就表示 satp 沒有任何效果
ch 3.1.8
machine exception delegation register ( medeleg )
用來 delegate exception。當相對應的 bit 的 exception 發生的時候,不會進到 M-mode ( mtvec ),而是進到 S-mode ( stvec )。
ch 3.1.8
machine interrupt delegation (mideleg)
用來 delegate interrupt。當相對應的 bit 的 interrupt 發生的時候,不會進到 M-mode ( mtvec ),而是進到 S-mode ( stvec )。
note : RISC-V 的 trap 有三種方式
發生 trap 時,依照 delegation 的設定,可能會跳到 mtvec 附近或是 stvec附近 ( 看 Mode 是設定成 Direct 還是 Vectored )。
ch 12.1.3
當寫入特定的 bit 的時候,代表該 bit 的 S-mode interrupt 會被 enable。
ch 3.7
設定 Physical Memory Protection ( PMP ) 的屬性。RISC-V 可以透過硬體,來直接對 physical memory 進行保護。
// configure Physical Memory Protection to give supervisor mode
// access to all of physical memory.
w_pmpaddr0(0x3fffffffffffffull);
w_pmpcfg0(0xf);
因為 pmpcfg0 設為 0xf
這代表
因為使用 Tor,所以當 pmpaddr0 設為 0x3fffffffffffffull 的時候,代表位址 0 ~ 0x3fffffffffffffull 將會套用 pmpcfg0 的設定
對應到 general purpose register 的 x4,詳情可以參考 calling convention。
ch 3.1.9
當寫入特定的 bit 的時候,代表該 bit 的 M-mode interrupt 會被 enable。
ch 3.1.18
在 xv6-riscv 程式碼內,會將 bit 63 ( STCE, STimecmp Enable ) 給設起來,這表示要開啟 SSTC 的功能。 SSTC 可以讓我們去使用 stimecmp CSR.
ch 3.1.11
在 xv6-riscv 內會去設定 TM ( bit 1 ) ,可以讓我們去使用 stimecmp
ch 12.1.12
假如 time 超過 stimecmp 的話, CLINT 會發出一個 timer interrupt
ch 12.1.5
mtime 在 S-mode 下的映射,會根據特定頻率新增自己的值
我們可以使用 QEMU + gdb 來觀察 boot 的時候,實際上會去執行什麼指令。
有關怎麼 debug xv6,可以看之前的筆記 : [6.1810] 環境設置 ( QEMU 與 toolchain )
可以發現一開始會在 pc == 0x1000 的位址,這邊實際上是 QEMU 自帶的程式碼。
https://github.com/qemu/qemu/blob/v10.0.0/hw/riscv/virt.c#L1506
https://github.com/qemu/qemu/blob/v10.0.0/hw/riscv/boot.c#L444-L454
(gdb) x 0x1000
0x1000: 0x00000297
(gdb)
0x1004: 0x02828613
(gdb)
0x1008: 0xf1402573
(gdb)
0x100c: 0x0202b583
(gdb)
0x1010: 0x0182b283
(gdb)
0x1014: 0x00028067
(gdb)
0x1018: 0x80000000
走過這邊之後,就會正式走到 xv6 的 entry point。
因為我們預期會有多個 CPU 同時運行,所以多個 CPU 會同時抵達這個 entry point。
這邊希望給每個 CPU 有自己的 stack 空間。
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/xv6-riscv-rev5/kernel/entry.S#L8
# 將 sp 設為 stack0,stack0 有在 start.c 裡面被定義
la sp, stack0
# 將 a9 設為 1024 * 4 = 4095
li a0, 1024*4
# 將 a1 設為 hart-id + 1
csrr a1, mhartid
addi a1, a1, 1
# 原本 a0 是 4096
# 原本 a1 是 hartid + 1
# a0 = a0 * a1
mul a0, a0, a1
# 令 sp = (hartid+1) * 4096
# 讓 sp 只到該 CPU 的 stack 的位址
add sp, sp, a0
# 可以進入 c 語言所撰寫的程式碼中 !
call stack
定義了 stack0,每個 CPU 可以分到 4096 bytes。
// entry.S needs one stack per CPU.
__attribute__ ((aligned (16))) char stack0[4096 * NCPU];
設定 mstatus 的 MPP 值,使其為 Superviosr mode ( S-mode )。這樣在執行 mret 之後,當前 CPU 的特權級會被設定為 S-mode。
void
start()
{
// set M Previous Privilege mode to Supervisor, for mret.
unsigned long x = r_mstatus();
x &= ~MSTATUS_MPP_MASK;
x |= MSTATUS_MPP_S;
w_mstatus(x);
設定 mepc 的值,這樣當我們執行 mret 之後,會跳到 main
// set M Exception Program Counter to main, for mret.
// requires gcc -mcmodel=medany
w_mepc((uint64)main);
關掉 paging,讓 CPU 所使用的 address 等於 physical address。
// disable paging for now.
w_satp(0);
設定 medeleg 會將 exception 委託給 S-mode。當對應的 bit 被 asserted,並且對應的 exception 發生的時候
不會跳進 m-mode 以及 mtvec
而是跳進 S-mode 以及 stvec
設定 mideleg 會將 interrupt 委託給 S-mode。
// delegate all interrupts and exceptions to supervisor mode.
w_medeleg(0xffff);
w_mideleg(0xffff);
在這邊 enable 幾個 S-mode 的 interrupt
SEIE : Supervisor external interrupt
STIE : Supervisor timer interrupt
w_sie(r_sie() | SIE_SEIE | SIE_STIE);
上面有提到過了
將 pmpcfg0 設為 0xf 的話
A : 1,代表使用 Tor
X : 1,代表可以進行 instruction execution
W: 1,代表可以進行寫入
R : 1,代表可以進行讀取
因為使用 Tor,所以當 pmpaddr0 設為 0x3fffffffffffffull 的時候,代表位址 0 ~ 0x3fffffffffffffull 將會套用 pmpcfg0 的設定。
這代表了,0 ~ 0x3fffffffffffffull 的 physical memory protection 權限為 xwr。
// configure Physical Memory Protection to give supervisor mode
// access to all of physical memory.
w_pmpaddr0(0x3fffffffffffffull);
w_pmpcfg0(0xf);
初始化 timer 中斷
// ask for clock interrupts.
timerinit();
為求方便,將 mhartid 放進 tp register ( general purpose register 的 x4 )
// keep each CPU's hartid in its tp register, for cpuid().
int id = r_mhartid();
w_tp(id);
執行 mret
CPU 的特權階級會跳到 S-mode,因為我們事先將 mstatus.MPP 設為 S-mode
CPU 會跳到 main function,因為我們事先將 mepc 設為 main function 的位址
// switch to supervisor mode and jump to main().
asm volatile("mret");
// ask each hart to generate timer interrupts.
void
timerinit()
{
// STIE 指的是 `Supervisor timer interrupt`
// 這邊 enable 了 Supervisor timer interrupt
// enable supervisor-mode timer interrupts.
w_mie(r_mie() | MIE_STIE);
// bit 63 指的是 ( STCE, STimecmp Enable )
// 這邊將 STCE assert 之後,打開了 Sstc 的功能,讓我們
// 可以使用 stimecmp
// enable the sstc extension (i.e. stimecmp).
w_menvcfg(r_menvcfg() | (1L << 63));
// 允許 S-mode 去使用 stimecmp 以及 time CSR
// allow supervisor to use stimecmp and time.
w_mcounteren(r_mcounteren() | 2);
// 將下一發 timer interrupt 放在 timer tick 了 1000000 次之後。
// ask for the very first timer interrupt.
w_stimecmp(r_time() + 1000000);
}
scheduler functionscheduler functionhttps://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/xv6-riscv-rev5/kernel/swtch.S#L40
會跳到 ra ( x1 ) 所指向的位址。
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/proc.c#L93
去要一個 pid,這邊 pid 是從 1 開始嚴格遞增。
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/proc.h#L85
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/proc.c#L110
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/proc.c#L146
拿一個可用的 struct proc,ra 會設定為 forkret,這代表他們第一次被 scheduler 挑出來執行的時候,會先進入到 forkret function。
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/xv6-riscv-rev5/kernel/main.c#L31
初始化第一個要在 u-mode 跑的 user process
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/proc.c#L506
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/user/init.c
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/trampoline.S#L101
因為在 allocproc 的時候,會將 ra 設定成 forkret,所以 forkret 變成每一個 process 被 schedule 到的時候,會運行的一個 function。
這個 function 假如是第一次被執行到的話,就會執行 user/init.c。
在這個 function 的最後,會利用 userret( trampoline.S ) 回到 U-mode ( user-space )
https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/riscv/kernel/proc.c#L425
一個無窮迴圈
當有 process 發出 yield,準備放棄 CPU 的時候,會先到 swtch 的下一行 ( 看起來會像是從 swtch 這個 function 返回 ),並在這個迴圈裡面去尋找下一個可以執行的 process。
假如沒有 process 可以做,就會執行 wfi (Wait For Interrup),讓這個 CPU 休眠,直到 interrupt 發生。
不是 0,則回停留在 S-mode,利用 wfi ( wait for interrupt ) 進入休眠。沒有,只會有一個 init process。
其他 CPU 沒事做的時候,就待在 S-mode 的 sheduler() 裡面用 wfi ( wait for interrupt ) 發呆,等待 interrupt 的發生。
因為其他 a0, a1 是 caller-saved。
除了第一個 swtch 會 swtch 到 forkret 以外,其他的 swtch 理論上會回到呼叫 swtch 的地方。
例如說,現在只有一個 CPU,兩個 process,pA 以及 pB。
pA 目前正在執行,pB 是 runnable。當 pA 想要放棄 CPU 的時候,會去呼叫 swtch,在這個時候,pA 會把自己 caller-saved 的 register 存在自己的 stack,並跳進 swtch 這個 function,呼叫完後,會 context switch 到 pB 執行。
當 pB 想把 CPU 交給 pA 的時候...
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret
自己想不出來,網路上也找不到資料,於是問了 Gemini,不確定正確性如何,但感覺上蠻正確的 XD。又再一次地感嘆 Gemini 的強大。
這邊假設一個情況,所有 process 都去等待 disk operation 了,都不是 RUNNABLE,於是所有 CPU 都在等待著 { interrupt 發生 + 進入 trap handler 處理 }。
那假如這時候每一個 CPU 都沒有啟用 interrupt 的話,就不會有任何人進入 trap,就會發生 deadlock ( 就算 disk 處理完了,並發給 CPU interrupt,因為全部的 CPU 都 disable interrupt,於是沒有人可以進入 trap handler )。
所以在 scheduler 裡面,勢必要打開 interrupt,讓 CPU 有機會進入 trap handler 處理。
又因為接下來需要取用 spinlock,而當我們在使用 spinlock 的時候,需要 disable interrupt。
於是在 scheduler 裡面,intr_on 與 intr_off 中間有微小的時間差,在這個時間差裡面,讓 trap handler 有機會執行,並且又為了 spinlock 的取用,所以又馬上把 interrupt 給關掉了 ( intr_off )。
是 gcc 的 built-in function,意思是 full memory barrier ( 或可以稱為 memory fence )。
那什麼是 memory barrier, memory barrier 是做什麼用的呢 ?
memory barrier 可以讓指令的執行依循一定的順序。因為現在的 CPU 實在是太厲害了,有時候執行的順序並不會依照執行檔內顯示的指令順序 ( 於是被稱為亂序執行,Out-of-Order, OoO ),但有時候我們會希望對於記憶體的操作的順序是固定的,這時候我們就會需要使用到 memory barrier!
memory barrier 就像是劃出一條界線,這條界線確保了在這個界線之前的所有操作,都會比這條界線之後的所有操作更快完成,更快被其他 CPU 觀測到。
這邊給一個簡單的,沒有 memory barrier 的範例。
CPU 1
data = 42;
ready = true;
CPU 2
while (!ready) {}
print(data);
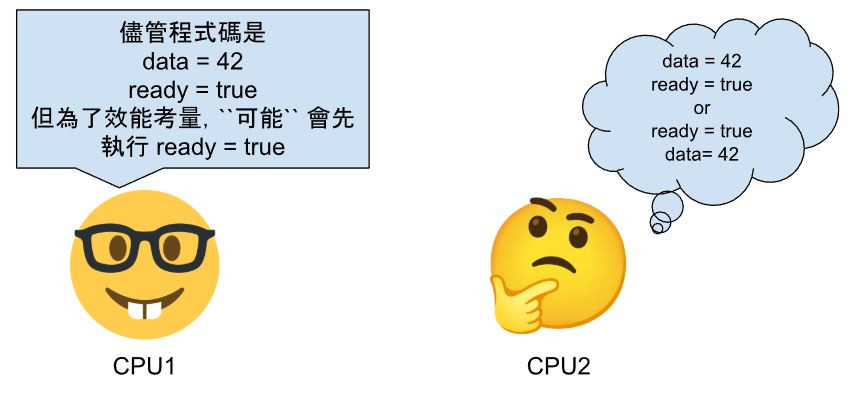
這會導致什麼問題呢 ?
假如 CPU2 觀察到的順序是
data = 42
ready = true
那 print 出來的值會是 42
假如 CPU2 觀察到的順序是
ready = true
data = 42
那 print 出來的值就不一定是 42 了
因為會先觀察到 ready = true,CPU2 跳出迴圈後就 print(data);
這導致程式的輸出結果並不是決定性的 ( deterministic ),每次執行的結果可能會不同。
這邊給一個簡單的,有 write memory barrier 的範例。
CPU 1
data = 42;
write_memory_barrier();
ready = true;
CPU 2
while (!ready) {}
print(data);
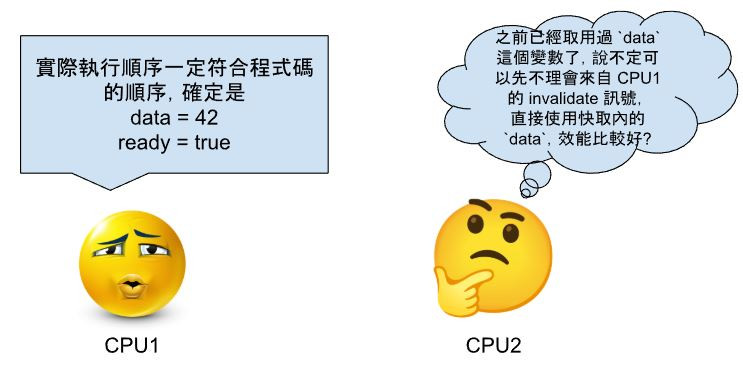
就算 CPU1 已經有了 write_memory_barrier,這邊還是有問題,導致 CPU2 仍舊會輸出 data 的值為 0,用到舊的 data 值。
還沒有處理完時,就讀取變數 data 的話,有機會取得舊的快取值。假如可以在讀取 data 之前插入 read_memory_barrier 的話,就可以確保這部分可以處理完,並刷新快取的資料。這邊給一個簡單的,有 read memory barrier 的範例。
CPU 1
data = 42;
write_memory_barrier();
ready = true;
CPU 2
while (!ready) {}
read_memory_barrier();
print(data);
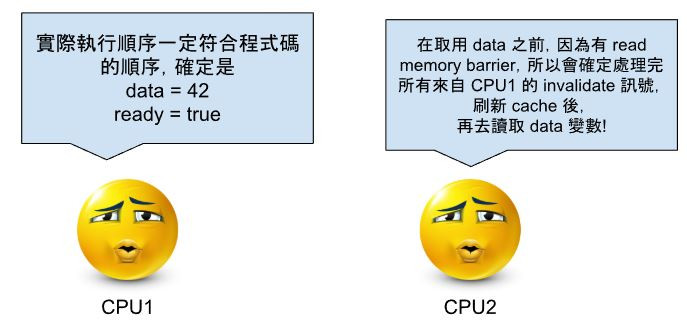
至此就不會有問題了,CPU2 永遠可以取得最新的,來自 CPU1 的 data 值 ( 除非硬體出現 bug 了 )
{ https://github.com/TommyWu-fdgkhdkgh/xv6-riscv/blob/xv6-riscv-rev5/kernel/main.c }
trapinit(); // trap vectors
trapinithart(); // install kernel trap vector
plicinit(); // set up interrupt controller
plicinithart(); // ask PLIC for device interrupts
binit(); // buffer cache
iinit(); // inode table
fileinit(); // file table
virtio_disk_init(); // emulated hard disk
userinit(); // first user process
__sync_synchronize();
started = 1;
} else {
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging
trapinithart(); // install kernel trap vector
plicinithart(); // ask PLIC for device interrupts
現在回頭看看 xv6-riscv 的程式碼,
__sync_synchronize 是確保說,所有的初始化完成後,才會對 started=1 設值。__sync_synchronize 希望確保 started 讀取完並跳出迴圈後,所有的記憶體讀取都結束( 需要被 invalidate 的快取也都處理完了 ),再開始初始化,避免初始化的過程中 ( e.g. kvminithart, trapinithart, plicinithart ) 拿到舊的值。Reference
 wtommy_fdgkhdkgh
wtommy_fdgkhdkgh

 iThome鐵人賽
iThome鐵人賽