我自己在日常的開發中比較常是會跟需求端討論需求,然後把成果用程式碼的方式進行呈現,所以不外乎遇到以下問題:
關於第一點的部分原本我是直接使用 Gherkin 作為與需求端的共通語言,但後來發現又會遇到幾個問題:
Gherkin 寫太細的話(跟測試一比一),需求端反而要看更多跟他不相關的內容,反而失去了原本我想拿他當共同語言的初衷Gherkin 很容易缺失 edge cases 或是有時候太專注在某個議題中容易漏掉 scenario
這部分我後來有兩個處理方法,首先是需求端文檔的部分,我根據 Design Docs at Google 的規範當作參考模板,會先將需求端文檔轉換成這種我覺得需求端好理解但是又能說明程式碼實作方向的文檔,這個文檔我將其稱之為北極星文檔 (desgin-doc.md)。
那再來就是如何讓 desgin-doc.md 到 Gherkin 這段更好銜接?我使用的是 OpenSpec。我覺得他在整個實作的過程可以一步一步地將要如何實作還有注意的 edge cases 擴展的更細,更好的無縫接上 Gherkin。至於 OpenSpec 在做什麼可以移駕到上面連結或是網路上有很多相關資源。當然我知道還有其他工具可以做類似的事情,但我覺得目前他的設計保持在中間,有我需要的基本規範,但是又不至於太過笨重。
至於 Gherkin 到測試,可以使用 pytest-bdd 等技術讓 feature 至少會有對應的測試程式碼,只是我也是剛使用沒多久還在習慣他的呈現方式。但在訊息不要在中途流失這點,這個工具算是有滿足我的需求。
至於生成的程式碼要怎麼維護品質?我是使用 python 進行開發,所以使用的是 ruff 與 pyright 等工具,然後跟資安相關的則是配置 Semgrep 在 CI 階段。當然如果是個人開源專案,可以考慮 sonarqube 等工具。不過因為我對於程式設計本身還沒有很全盤的鑽研過,所以對於好品味與好設計這件事情算是蠻苦惱的,而在 Boris Cherny的相關訪談 中則給我了很好的靈感,Boris Cherny 提到他需要大量的 code review 所以如果團隊中有常犯的錯誤他就會將其寫成 linter。那我順著這個思路先去看 ruff 有沒有一些人家已經寫好我又需要的規範再納入(我原本是比較輕度的使用 ruff 所以沒有研究太深入),但僅依靠類似 AST 的技術一樣沒辦法判斷諸如:這些方法的業務語意是什麼又或是整個系統的職責邊界在哪裡等等問題。
雖然我們上面還遺留一個小問題,但是還有一個問題是我要怎麼確保每一次開發都能穩定按照這個流程進行,不需要我在中間指揮呢?我試過使用 CLAUDE.md 來作為核心且長期的記憶手段,但發現效果真的很有限,而既然我每個節點該幹嘛都很清楚了,那是不是就可以用 skill 來補齊剩下的空缺呢?
既然現在每個節點需要的工具都有了——從文檔端的 OpenSpec、到行為規格的 Gherkin + pytest-bdd、到實際把關程式碼的 ruff 和 pyright 等等都有了——那剩下的就是如何讓 AI agent 每次都按照這個流程開發。
核心概念很單純:把我的開發流程拆成 6 個 Claude Code skill,用前置條件串起來,強制按順序走。
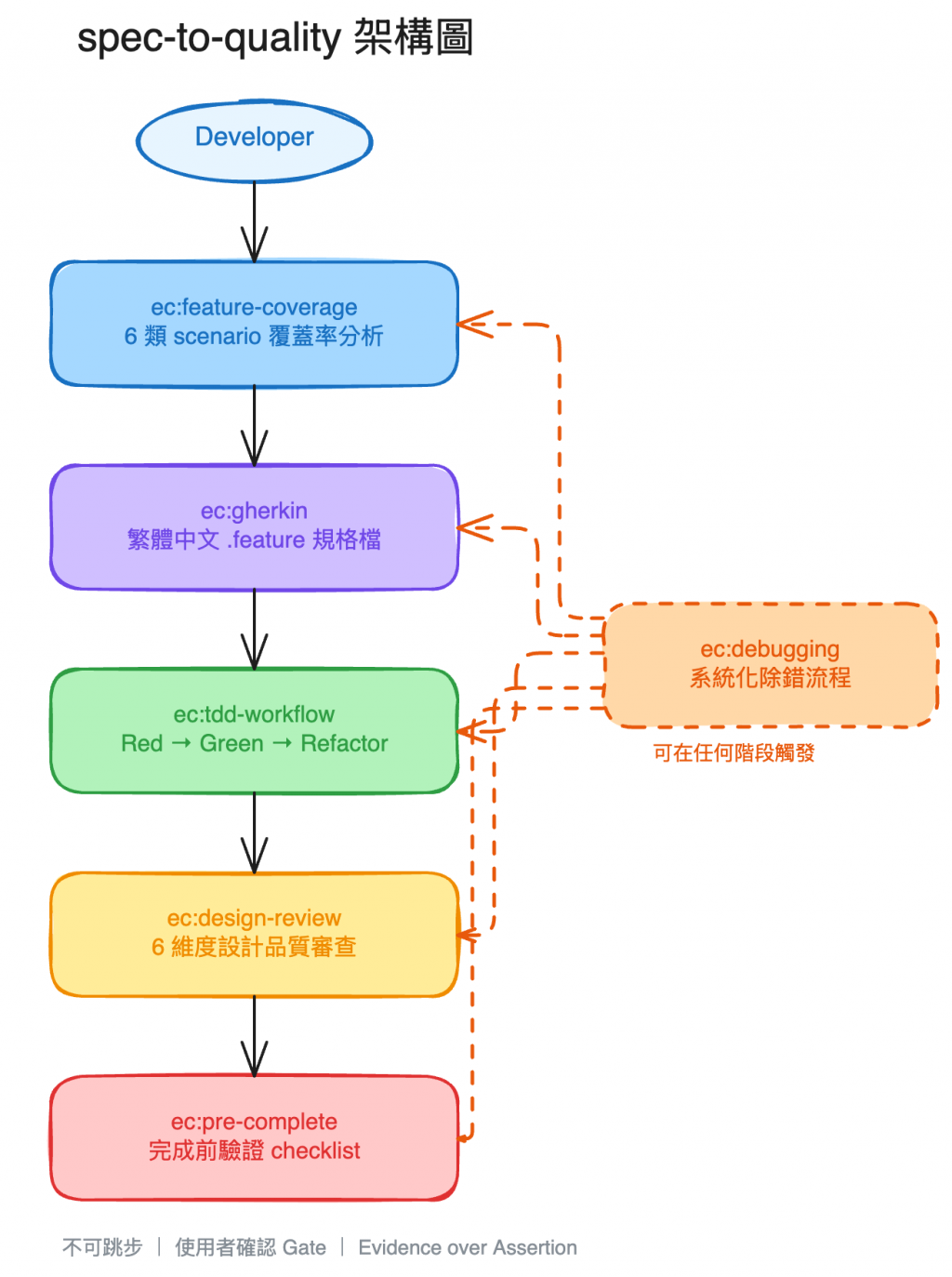
| Skill | 做什麼 |
|---|---|
| ec:feature-coverage | 寫 .feature 之前,強制對 6 類 scenario 逐一分析,避免漏掉情境 |
| ec:gherkin | 照著覆蓋率分析的結果寫 .feature,遵循 Feature / Rule / Scenario 結構 |
| ec:tdd-workflow | 嚴格的 Red → Green → Refactor,紅燈沒確認不能開始寫 code |
| ec:design-review | 綠燈之後的設計審查,用提問方式引導思考,不是直接叫你改 |
| ec:debugging | 遇到 bug 先收集證據、建假說、驗證,不准猜著改 |
| ec:pre-complete | 要說「完成」之前,跑完測試 + lint + type check,拿到實際輸出才算數 |
跟把規則全部寫在 CLAUDE.md 裡不同的地方在於,skill 是在特定時機被完整載入的指令集。CLAUDE.md 是全域背景知識,在比較長的 context 裡容易被蓋過去;skill 則是在你觸發對應的 slash command 時,整份 instructions 才會注入到當下的 context,確保該階段的規則不會被忽略。當然你觸發了關鍵字時也會自動進行觸發,總之就是相比於 CLAUDE.md 比較能夠讓 Agent 專心(上下文即是一切!)
而前置條件的設計讓流程不是靠 Agent「記得」要做什麼,而是在結構上強制:沒做完覆蓋率分析就不能寫 .feature,TDD 沒綠燈就不能做 design review。
跟這個 skill 比一定有更適合你的其他選擇,或是在每個階段都有更深入、思考更全面的其他 skill,甚至是其他 CI 工具也說不定。但它就相當於是我把我平日開發流程的過程去嘗試更自動化一點,但我也沒有想要 100% 全自動化——畢竟我覺得我還沒有厲害到能不看程式碼,或是只看一些指標就有全局觀、掌握 codebase 的程度。
這個 skill 相當於是我對軟體開發流程的寫照,但才剛寫出來,沒做多少次完整的 feature 到 code 的開發,但其中的內容跟我平常自己手打下指令的內容差異不大,並且參考了 官方文檔 去稍微看一下自己做 skill 時有哪些地方需要注意。不過使用一段時間後也許覺得需要調整的話也會不斷地的去迭代這個 skill。
但也不知道 skill 這個概念會不會很快又被迭代掉呢 XD
最後是專案連結~
GitHub repo:class83108/spec-to-quality
 blank
blank

 iThome鐵人賽
iThome鐵人賽