目前系統只支援Big 5中文碼,Big 5中文碼沒有的中文字需要造字,但是需要造字的字在Unicode中文碼是有的,想請問Unicode中文碼可以轉換成Big 5中文碼嗎?
已邀請的邦友 {{ invite_list.length }}/5
以集合來描述看看
BIG5 = {A,B,C} -- 常用字, 罕用字, 日文假名與符號
UNICODE = {A,B,C,D,E,F,G,....} -- 常用字, 罕用字, 日文假名與符號, 簡體中文, 日文漢字, 真.日文假名
在 D 當中的文字, 在 BIG5 找不到時, 就只會出現原編碼代號或 ? , 除非有系統可以產生
BIG5 = {A,B,C,D',E'} -- 常用字, 罕用字, 日文假名與符號, 自建字D', 自建字E'
所以問題關鍵就是: 現有 BIG5 本身的限制, 造成 UNICODE 許多字無法在 BIG5 呈現, 所以:
a. 誰來自建這些字, 用哪個範圍的編碼, 如何把自建字佈署給全部要用到的電腦?
b. 相關資料進來時, 哪個系統來轉換?
c. 遇到新字或轉換失敗時, 是否會自動提醒?
不知道理解對不對,kenny大講的是常用的難字(BIG5外字),像是方方土堃的堃之類的,這類型標準Unicode 2.0系統字就有支援,但在BIG5則需要另外造字的?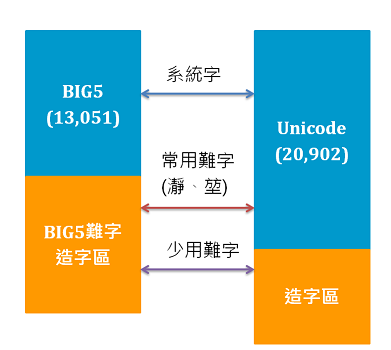
如果是,關於kenny大的提問:
Unicode中文碼可以轉換成Big 5中文碼嗎?
可以的,不過因為電腦轉換編碼時認字碼不認字形,如果要將這類的Unicode系統字對回BIG5造字區:
看過有一種解法,如果我們造字時是Unicode和BIG5同時按照兩邊造字區順序造下來,情況會有點不一樣了。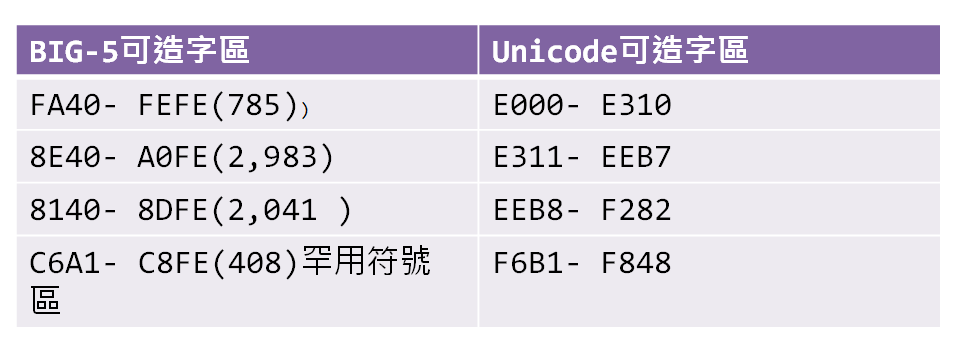
像是我們用注音輸入堃,左上角的是Unicode系統字,右上角的則是Uncode造字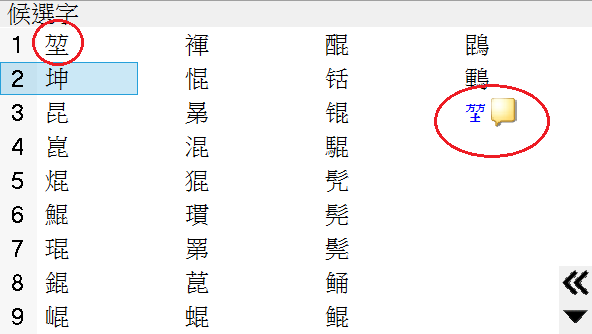
在沒有使用轉碼軟體的情形下:
如果只能選擇BIG5又想處理掉難字,找中文碼處理廠商比較快。
(http://)全字庫認識一下
https://www.cns11643.gov.tw/pageView.jsp?ID=2&
我的軟體也是早期fox只能打big5沒辦法輸入UNI的字(例如堃/喆),裝了全字庫後又麻煩了人家半天(一直email請教)才學會怎麼輸入這些特殊字和特殊符號~
基本上只要你肯用,什麼希臘文/拉丁文/泰文...都可以打得出來...

 iThome鐵人賽
iThome鐵人賽