請問一下各位前輩
問題1
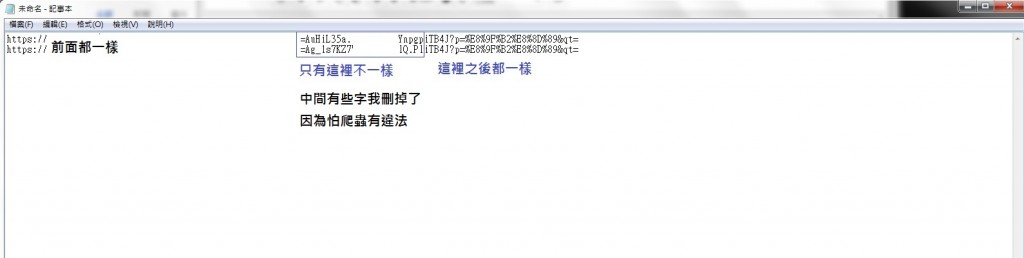
小弟要爬某個網站的所買的東西,第一頁已經可以成功的爬到了
但第二頁之後的,我卻找不到方法可以把
想用 scrapy 工具,但網址的規則卻在中間變化
小弟不知道該怎麼辦,請問有前輩高手可以教教我嗎?
問題2
另外還有一個網站國外的知名拍賣網
我下的語法,大概是前一秒鐘還可以爬到東西
相同的語法,再執行一次,沒有任何東西出來,也沒有錯誤
大概是他的網站,有時間的間隔,防止爬蟲
請問一下有什麼方法,可以抓他的時間間隔,或者是可以破解嗎?
已邀請的邦友 {{ invite_list.length }}/5
