import pandas as pd
data = pd.dataframe.colname.('okok.csv')
data.drop_duplicates('okok.csv',"first",inplace = True)
我找到這個方法 可以清除連續重複的資料!!
我知道我語法錯誤,但我怎麼改都無法成功請問 dataframe 這錯誤是因為我要用上次跑出來的檔案來跑嗎? 怎麼改才是對的能給教教我嗎?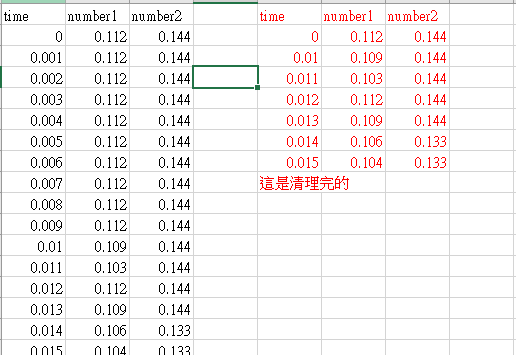
我想要把 這檔案變成這樣清理過後的
我今天使用linux 清理.txt 無法達成此效果改用python使用 不太常使用python不太知道怎麼半。 求教學了 感恩!!
已邀請的邦友 {{ invite_list.length }}/5
import pandas as pd
data = pd.read_csv('okok.csv') # 讀取csv,存入data變數
data.drop_duplicates(keep='first', inplace=False) # 刪除重複
參數是什麼意思請看上面參考資料。
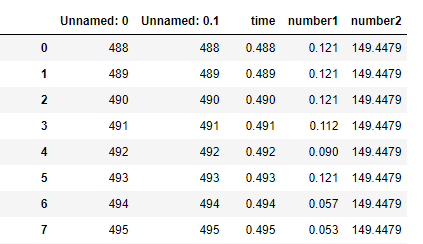
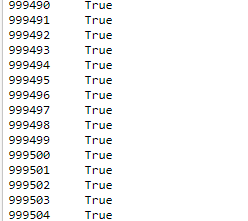
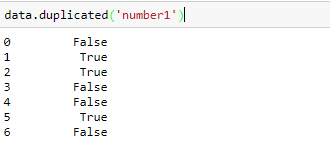
我知道R 語言可以 python可以 因為這樣刪除會直接到後來都判斷重複 請問有別的方法嗎??
看不懂,我覺得你應該要先想一下你問題要如何表達。
另外會用R就用R寫吧,程式語言只是工具而已,非一定要哪牌的工具才能做什麼事。
抱歉 不夠清楚。
我問題是 這個方法找重複數 到後來會全部顯示True因為等於全部有出現過的就算重複過了 python有可以只刪除連續重複然後留第一個重複的數,不要連後面因為出現一樣的值的也一起刪除? number1 那一行0.121 第5個也是0.121但因為不是連續所以不算重複 但他判斷成true所以也會刪除。
想法:
利用diff去和上一個row相減,然後得到一個要不要保留的series,利用loc去篩選出來。
import pandas as pd
n1 = [1,2,2,3,3,3,2,4,3]
n2 = [3,5,5,1,1,1,5,1,1]
data_dict = {
"n1": n1,
"n2": n2
}
data_df = pd.DataFrame(data_dict)
data_keep = data_df.diff().fillna(True).T.any() # 將與前項相減後都為0之index設為False,但因diff後第一項資料變為Nan,所以要用fillna()將Nan改為True,最後對每項內的資料取any()
data_df.loc[data_keep != 0]
我再試試看 感謝!!

 iThome鐵人賽
iThome鐵人賽