我要使用 cat 993.csv | uniq -f1
想法:uniq可以換列去搜尋有沒有重複的值嗎?我要用中間number1那個值找尋重複刪掉重複的一整行。但我-f 1並不會換列去尋找出來的值都很奇怪 是我語法錯誤嗎?還是uniq 並不能處理這樣的東西。
我txt csv都是過了!我要用比對的是中間的number1那個值!!
我要清出重複值用過了 R Python(他們都只要出現過一次就會判斷是重複的)但都沒有unip這樣只清除連續重複的值功能 所以我想使用linux uniq試試?還是有什麼方法可以建議一下感謝!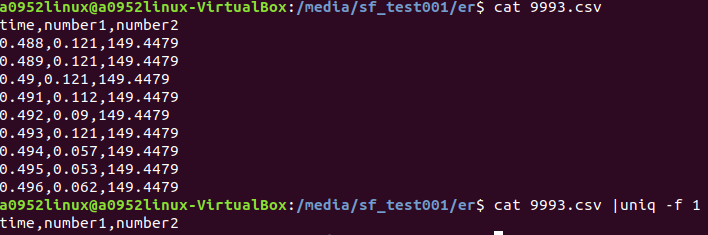
已邀請的邦友 {{ invite_list.length }}/5
把 data.txt 替換成你要讀取的 csv
把兩個 $F[1] 換成你要 uniq 的欄位, 1 = 第二欄
perl -anF, -e '$n ne $F[1] && print; $n=$F[1];' data.txt

 iThome鐵人賽
iThome鐵人賽