各位大大們你們好,小弟我剛踏入寫程式這個坑不到一個半月的時間,目前正在學習爬蟲還有下載檔案。
過去曾成功下載過<國北>的考古題,但是我發現有一些考古題並未被下載下來,找了半天才發現原來並非所有的pdf檔前都是以http為開頭,所以便呈現出無法讀取,僅有http開頭的pdf被我下載了。
當遇到這樣的問題時該如何解決呢?
以下為我的程式碼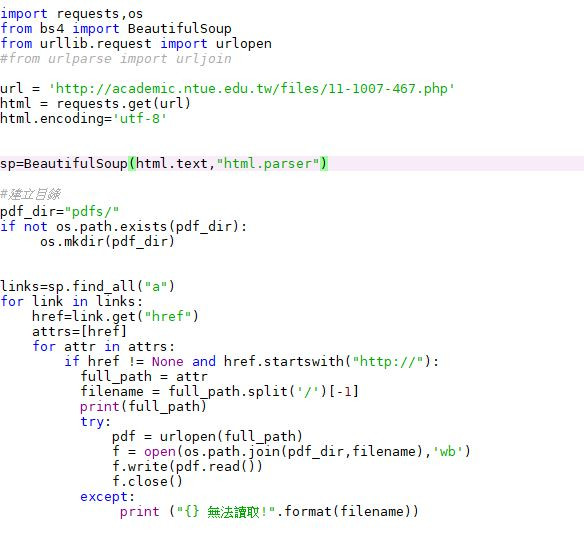
還請各位多幫忙,謝謝!!
已邀請的邦友 {{ invite_list.length }}/5
當前網頁:http://academic.ntue.edu.tw/files/11-1007-467.php
如果連結的網址是「/」開頭,代表實際網址要前面加上 http://academic.ntue.edu.tw
如果連結的網址開頭就直接是英文字,那麼實際網址要加上 http://academic.ntue.edu.tw/files/
好的我會去試試看!!
謝謝指導!
更改程式碼後,那些[/]開頭的連結還是下載不下來,想請您幫我確認一下我是否有打錯的地方:
import requests,os
from bs4 import BeautifulSoup
from urllib.request import urlopen
#from urlparse import urljoin
url = 'http://academic.ntue.edu.tw/files/11-1007-467.php'
html = requests.get(url)
html.encoding='utf-8'
sp=BeautifulSoup(html.text,"html.parser")
#建立目錄
pdf_dir="pdfs/"
if not os.path.exists(pdf_dir):
os.mkdir(pdf_dir)
links=sp.find_all("a")
for link in links:
href=link.get("href")
attrs=[href]
for attr in attrs:
if href != None and href.startswith("http://academic.ntue.edu.tw"):
full_path = attr
filename = full_path.split('/')[-1]
print(full_path)
try:
pdf = urlopen(full_path)
f = open(os.path.join(pdf_dir,filename),'wb')
f.write(pdf.read())
f.close()
except:
print ("{} 無法讀取!".format(filename))
links=sp.find_all("a")
for link in links:
href=link.get("href")
#不用再多一層 attr 迴圈,href 已經是連結了
#如果不是 .pdf 結尾,直接跳過不處理
if(href == None or href.split('.')[-1]!='pdf'):
continue;
#關於網址的處理
if(href[0:4]=='http'):
full_path = href
elif(href[0]=='/'): #這邊要處理開頭為 / 的網址
full_path = "http://academic.ntue.edu.tw" + href
else: #其他的是相對路徑
full_path= "http://academic.ntue.edu.tw/files/" + href
print(full_path)
#後面就是抓 full_path 並儲存
另外提醒一下,他有不同資料夾但是相同檔名的狀況
所以如果單純用
filename = full_path.split('/')[-1]
作為儲存的檔名,會有後面覆蓋前面的情形
似乎還是有點問題 不過有進展了 我再研究看看 先謝大哥!
都成功了,感謝解答! 感激不盡!
