小弟是剛剛接觸Python爬蟲的小白
1.我想要擷取圖片中文字的部分,卻怎麼樣也擷取不到,是我的程式碼有誤嗎?
2.還有圖片中 黑色圓圈 (text) 是指我想擷取文字部分嗎?
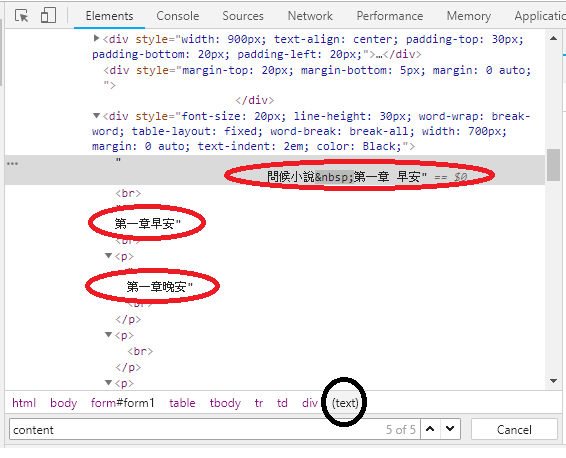
以下是我的程式碼:(2個都使用過)
content = soup.select('html body #form1 table tbody tr td div')
content = soup.select('html body #form1 table tbody tr td div p')
※因為小弟是自學所以很多東西不是很了解,請各位大神不吝賜教
已邀請的邦友 {{ invite_list.length }}/5
在python遇到問題我常用的解決方式:
1.print() 這應該不用我說
2.dir() 和print結合可以看到物件裡的所有屬性和方法
3.type() 回傳這個物件的類型
HTML裡的node,因為有很多屬性,像是innerText、attribute、property等,不可能select出來你的content就是innerText。
另外請放code全部,只放那兩行code沒人能搞懂你是哪裡出問題。
最後建議改用 requests-html,相對簡單很多。我很久沒直接用bs4了。