tablea 與 tableb 的數據部分可能會不一致,所以利用索引加速搜索,
已知道用小表驅動大表,可是要蒐集 colb_4 的數據不過一直產生臨時表導致搜尋效率降低,
利用索引已經將tableB搜尋的行數降低了。
tablea 與 tableb 的 欄位資訊
CREATE TABLE `tablea` (
`tableA_ID` int(11) UNSIGNED NOT NULL AUTO_increment,
`cola_1` varchar(15) NOT NULL,
`cola_2` varchar(15) NOT NULL,
`cola_3` varchar(15) NOT NULL,
PRIMARY KEY (tableA_ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `tableb` (
`tableB_ID` int(11) UNSIGNED NOT NULL AUTO_increment,
`cola_1` varchar(15) NOT NULL,
`cola_2` varchar(15) NOT NULL,
`cola_3` varchar(15) NOT NULL,
`colb_4` varchar(20) NOT NULL,
`colb_5` int(15) NOT NULL,
PRIMARY KEY (tableB_ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 建立索引優化
ALTER TABLE `tablea` ADD INDEX col_a123(cola_1,cola_2,cola_3);
ALTER TABLE `tableb` ADD INDEX col_a123(cola_1,cola_2,cola_3);
ALTER TABLE `tableb` ADD INDEX col_b45(colb_4,colb_5);
測試函數與程序
DELIMITER $$
CREATE FUNCTION str_rand( t_count int ) -- 產生固定隨機字母
RETURNS varchar(255)
BEGIN
DECLARE str VARCHAR(255) DEFAULT "";
DECLARE randstr VARCHAR(100) DEFAULT "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
DECLARE t_str VARCHAR(1) DEFAULT "";
DECLARE i int default 0;
while i<=t_count do
SET str = concat(str,substring(randstr,FLOOR(1+RAND()*52),1));
SET i=i+1;
end while;
RETURN str;
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION num_rand() -- 隨機數字 100-110
RETURNS int(5)
BEGIN
DECLARE num int(5) DEFAULT 0;
SET num = FLOOR(100+RAND()*10);
RETURN num;
END $$
DELIMITER ;
DELIMITER $$ -- 生產測試數據 比例為 tablea:tableb = 1:3
CREATE PROCEDURE `insert_data`(IN START INT(10),IN max_num INT(10) )
BEGIN
DECLARE i int DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO tablea(cola_1,cola_2,cola_3)
VALUES
( CONCAT("cola1_",i),CONCAT("cola2_",i),CONCAT("cola3_",i) );
INSERT INTO tableb(cola_1,cola_2,cola_3,colb_4,colb_5)
VALUES
( CONCAT("cola1_",i),CONCAT("cola2_",i),CONCAT("cola3_",i),str_rand(5),num_rand() ),
( CONCAT("cola1_",i),CONCAT("cola2_",i),CONCAT("cola3_",i),str_rand(5),num_rand() ),
( CONCAT("cola1_",i),CONCAT("cola2_",i),CONCAT("cola3_",i),str_rand(5),num_rand() );
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
DELIMITER ;
-- 建立假數據
CALL insert_data(1,10000)
查詢的方式
EXPLAIN SELECT `colb_4`,avg(`colb_5`)
FROM
tablea a
INNER JOIN
tableb b ON ( a.cola_1 = b.cola_1 and a.cola_2 = b.cola_2 and a.cola_3 = b.cola_3 )
GROUP BY `colb_4`
結論
SHOW profiles 查詢結果
得知 Sending data 話費時間異常的高 經常在搜查硬碟的資料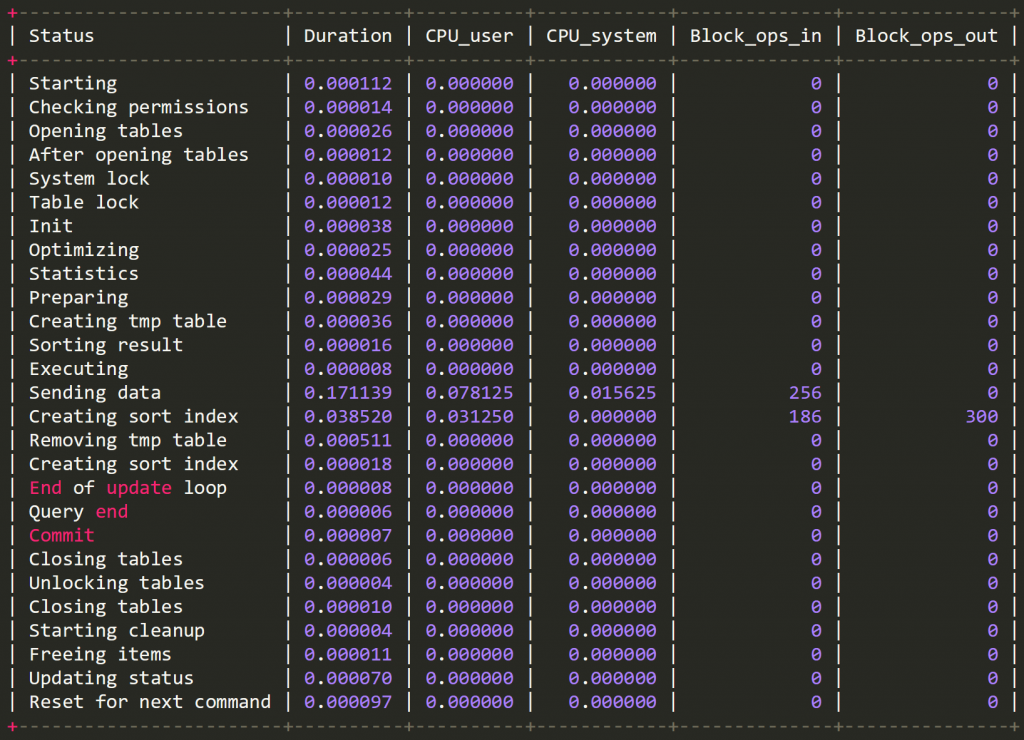
實際上 tableb.colb_4 的欄位更大,但是目前的結果導致搜尋時會使用到臨時表
目的是要尋找到相同的 tableb.colb_4 並運算統計 tableb.colb_5
想請問如果要優化且不會產生臨時表該如何調整
已邀請的邦友 {{ invite_list.length }}/5
優化30%,且不產生臨時表
EXPLAIN SELECT
b.colb_4,
b.avg
FROM
( SELECT tableb.colb_4, Avg( tableb.colb_5 ) AS AVG, colb_key FROM tableb GROUP BY tableb.colb_4) b
INNER JOIN tablea ON b.colb_key = tablea.cola_key
order by 1
#修改欄位結構,加上虛擬計算欄位並索引之
CREATE TABLE tablea (tableA_ID int(11) unsigned NOT NULL AUTO_INCREMENT,cola_1 varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL,cola_2 varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL,cola_3 varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL,cola_key varchar(45) GENERATED ALWAYS AS (concat(cola_1,cola_2,cola_3)) STORED,
PRIMARY KEY (tableA_ID),
KEY cola_key (cola_key)
) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE tableb (tableB_ID int(11) unsigned NOT NULL AUTO_INCREMENT,cola_1 varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL,cola_2 varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL,cola_3 varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL,colb_4 varchar(20) COLLATE utf8mb4_unicode_ci NOT NULL,colb_5 int(15) NOT NULL,colb_key varchar(45) GENERATED ALWAYS AS (concat(cola_1,cola_2,cola_3)) STORED,
PRIMARY KEY (tableB_ID),
KEY colb_key (colb_key),
KEY colb_4 (colb_4)
) ENGINE=InnoDB AUTO_INCREMENT=30001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
經過測試tableb的數量只要一大反而效率會比原先的還要差更多,原因出自於查詢的比數沒有減少,將tableb筆數拉大到30萬筆後進行的測試
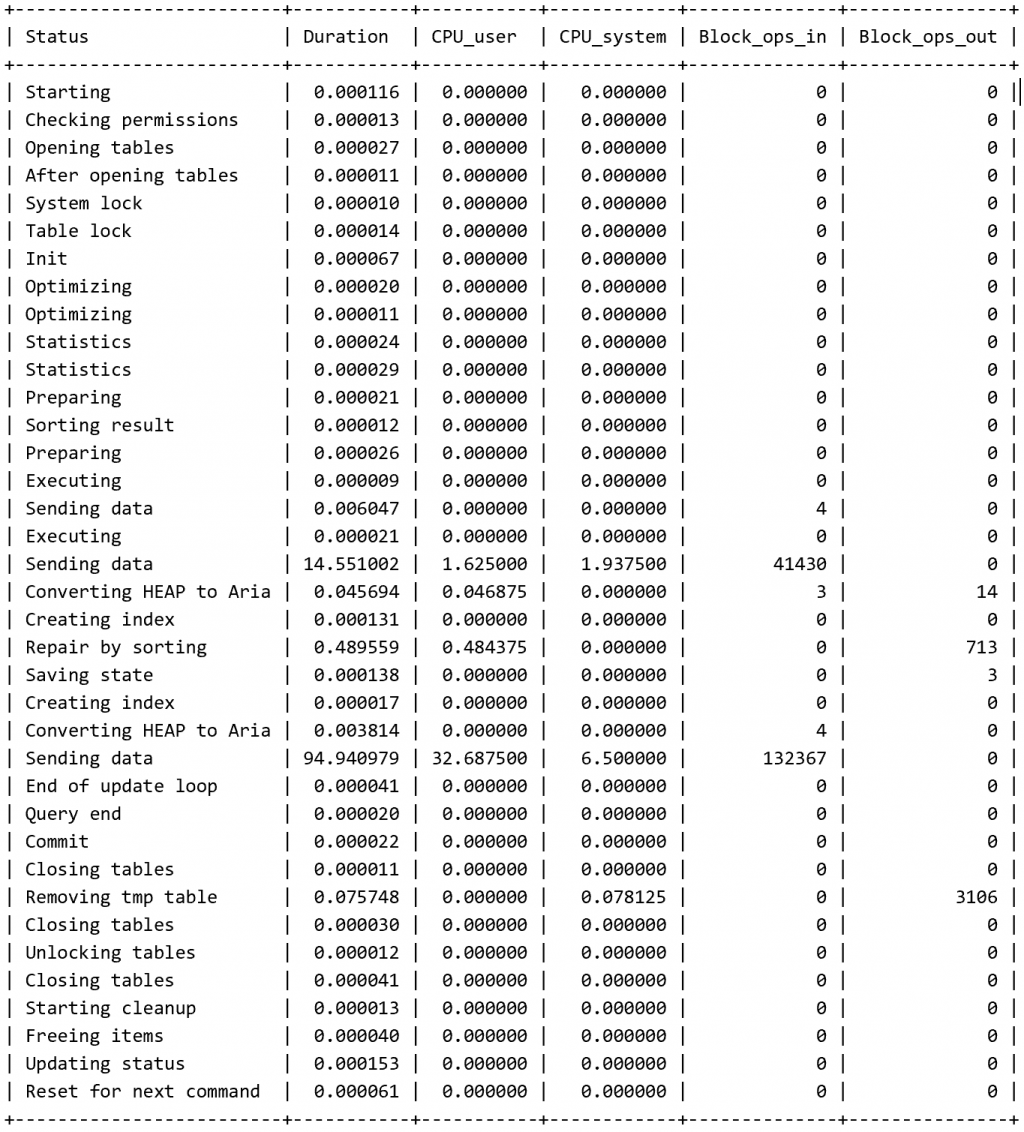
原先的語法
您好:
這個網站一直說我是新手,不給我回應,我有很不受尊重的感覺,但也不知如何是好。
(還沒遇過這麼折磨人的網站,助人如此為難?)
您的問題,在於您的提問方式不太理想,您舉例是10000筆,
於是我就用10000筆的方式去思考,但當資料量到300000筆時,
設計方式就會不一樣,
建議,下回您提問時,最好把實際情況說清楚,最大資料量可能有多少筆,回答者的思考角度會不一樣。
SQL 博大精深,優化加速一定有方法,要憑經驗,
我把資料加大到900000筆,
用您的方式,要跑約26秒,
用我的方式,則約7秒,速度快了3倍。
CREATE PROCEDURE select_data()
BEGIN
drop TEMPORARY table if exists tablec;
create TEMPORARY table tablec as
SELECT tableb.colb_4, Avg( tableb.colb_5 ) AS AVG, colb_key FROM tableb GROUP BY tableb.colb_4 order by 1;
SELECT
tablec.colb_4,
tablec.AVG
FROM
tablec
INNER JOIN tablea ON tablec.colb_key = tablea.cola_key ;
END
#執行查詢
CALL select_data();
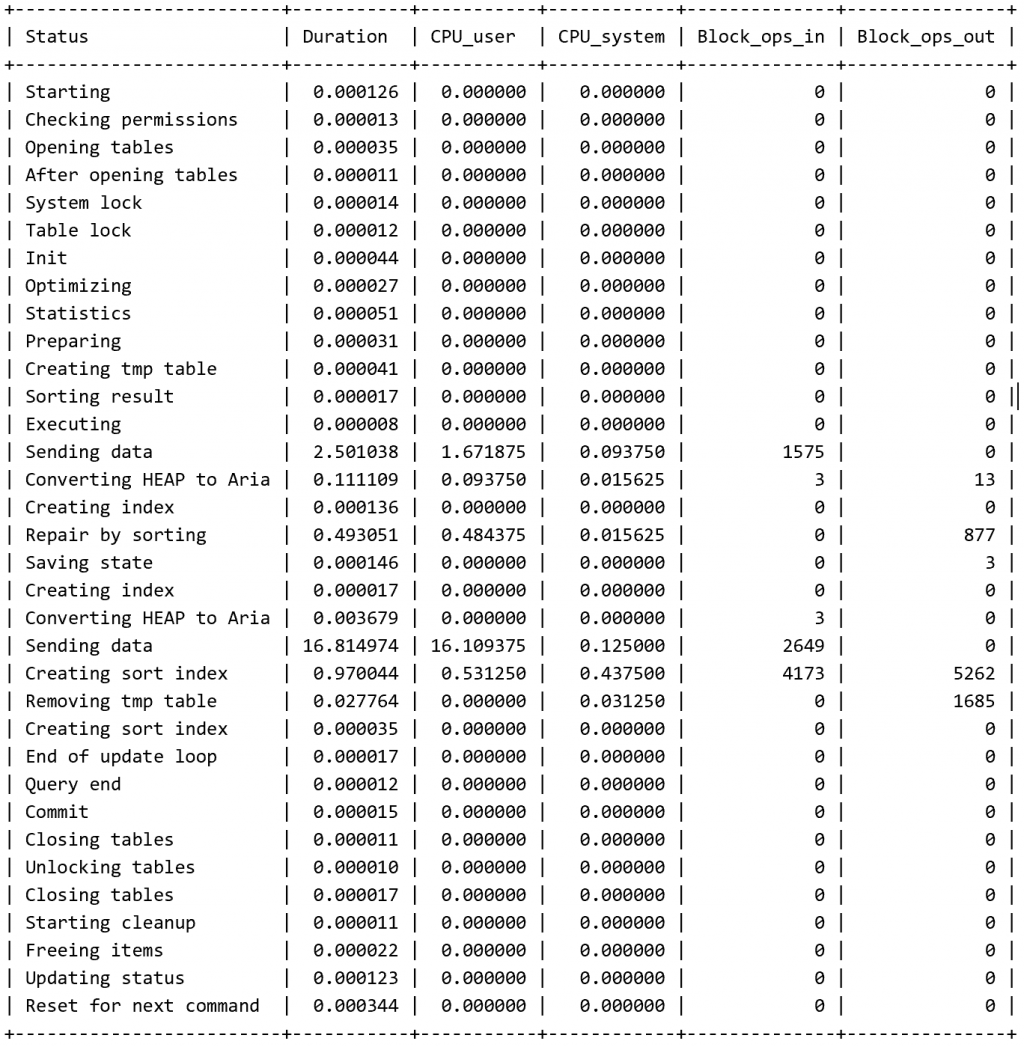
好,我下次會在注意的
使用您的方法速度有變得比較快雖然沒有到7秒,
您的方法測試的結果為4分鐘14秒
原本的方式則沒結果(查詢時間過長),
謝謝您解決我的疑惑
您好:
我測了90萬筆,很多次,都在7-10秒之間,
如果,您要跑4分鐘的話,那麼,您的實際資料是幾筆呢?
我認為,若要跑4分鐘的話,那還有改進空間,可能要再換別種寫法。
我的mysql版本為 10.3.15-MariaDB
在建立tablec的臨時表就花了3分半鐘的時間,
tableb的數據有90萬,有建立索引colb_4,
tablea的數據有30萬,有於使用avg 會造成錯誤提示所以改成整數型態
DROP PROCEDURE IF EXISTS `select_data`;
DELIMITER $$
CREATE PROCEDURE `select_data`()
BEGIN
drop TEMPORARY table if exists tablec;
create TEMPORARY table tablec as
SELECT tableb.colb_4, FLOOR(Avg( tableb.colb_5 )) AS AVG, colb_key FROM tableb GROUP BY tableb.colb_4 order by 1;
SELECT
tablec.colb_4,
tablec.AVG
FROM
tablec
INNER JOIN tablea ON tablec.colb_key = tablea.cola_key ;
END$$
DELIMITER ;
運行結果如下
單獨查詢的效能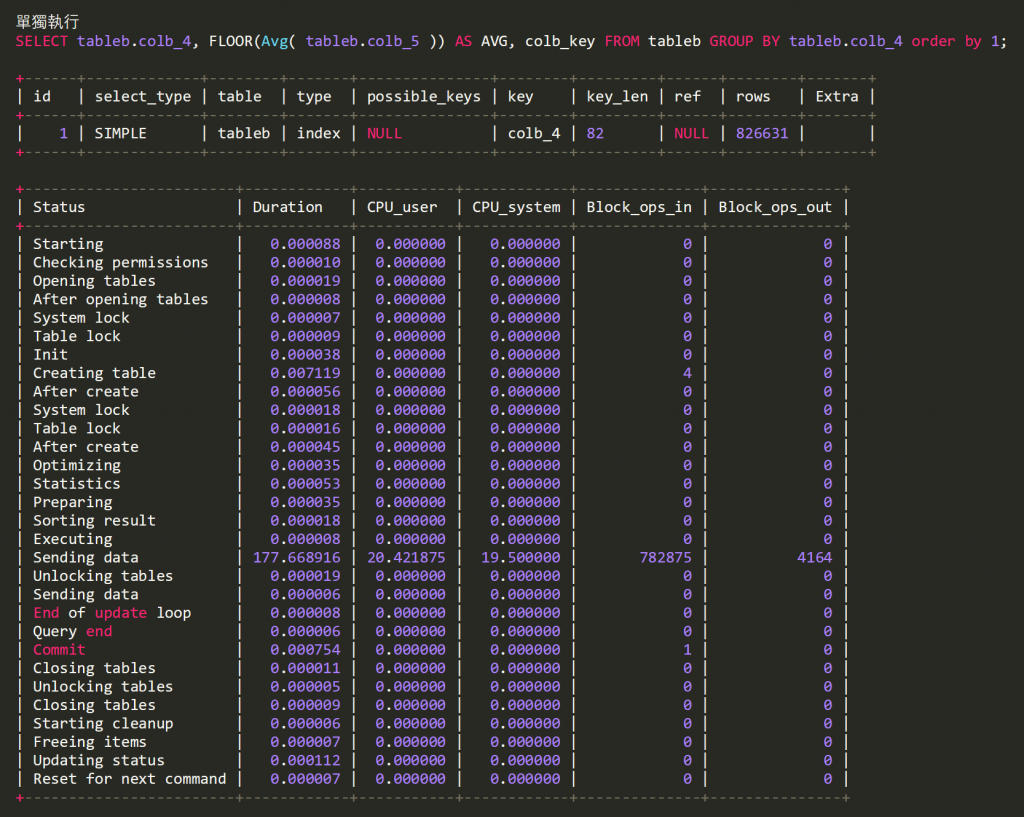
使用程序的效能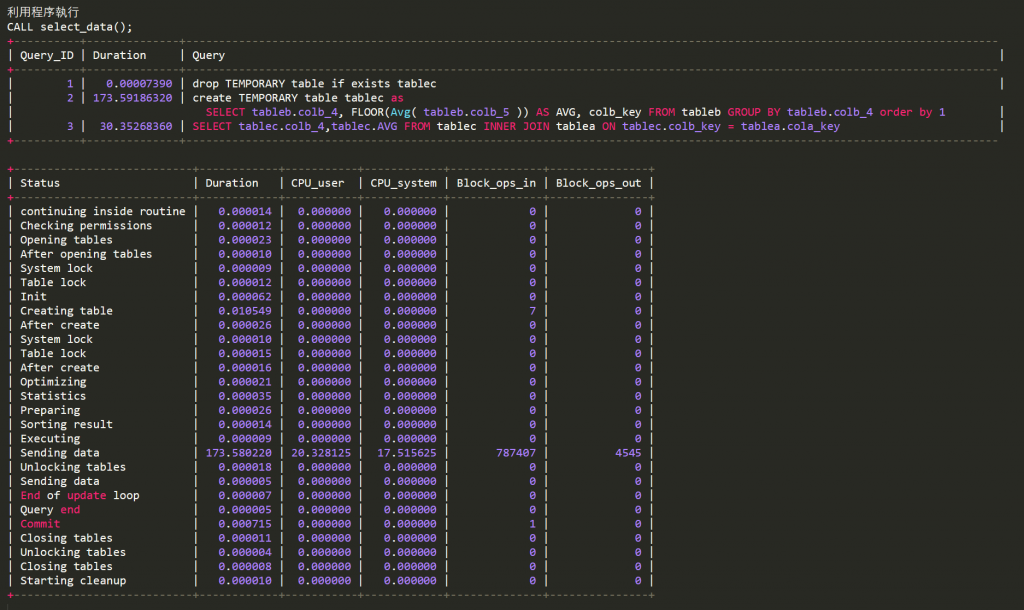
顯示出來的效能 最後顯示出來的 explain分析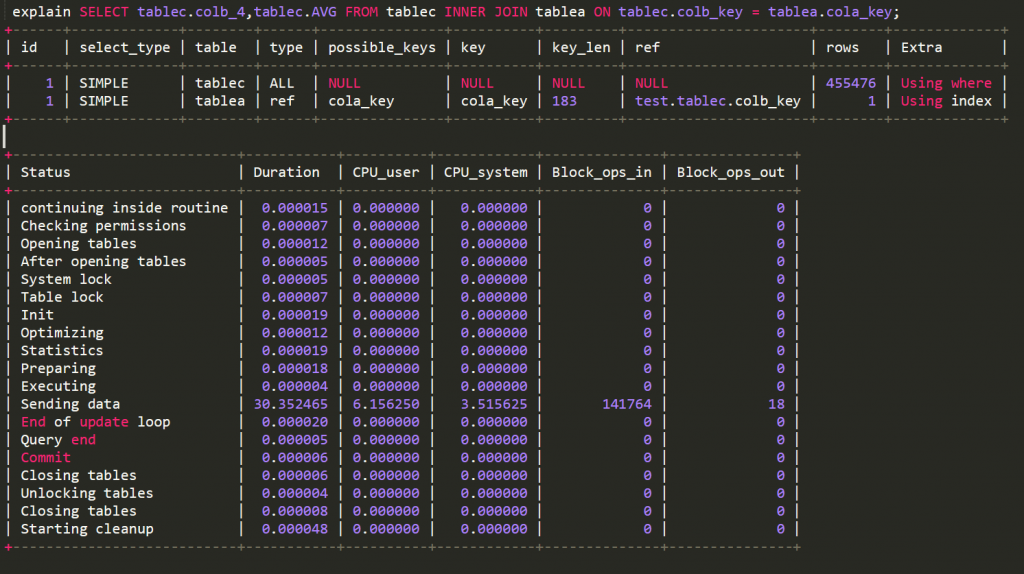

 iThome鐵人賽
iThome鐵人賽