單獨一個一個轉太慢了 , 怎樣可以很快轉 , 請問下面程式要怎麼改 , 迴圈要怎麼加
import pandas
with open('d:\weather\\a.txt','r') as f:
df = pandas.read_html(f.read().decode("gb2312").encode('utf-8'),encoding='utf-8')
print df[0]
bb = pandas.ExcelWriter('out.xlsx')
df[0].to_excel(bb)
bb.close()
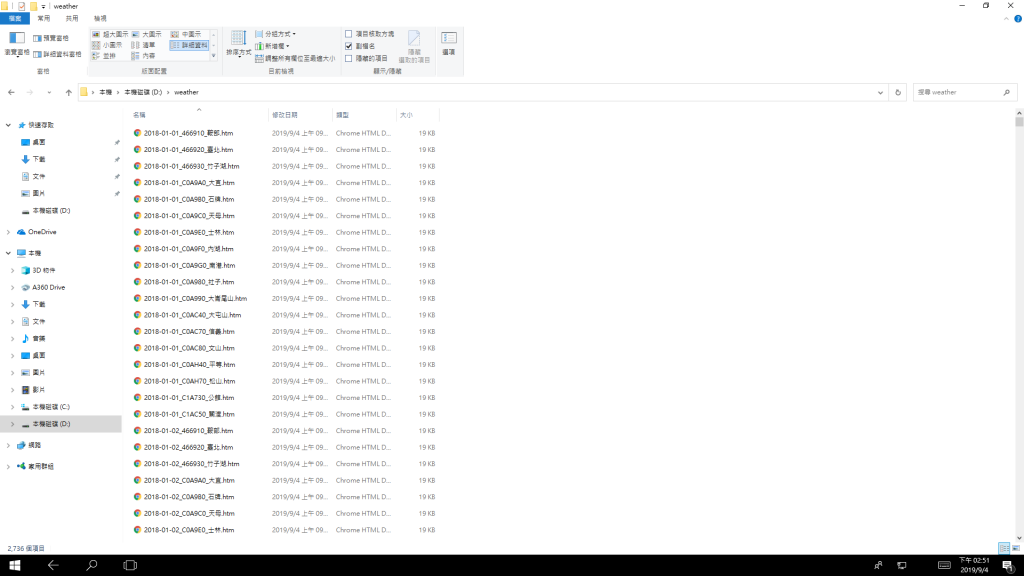
下面是要轉的 htm
已邀請的邦友 {{ invite_list.length }}/5
樓主先前問過如何用Python爬取氣象站的資料,
當時我在回覆的時候貪圖方便就把 stationID跟中文站名寫成陣列綁在一起,例如:
location_arr=['466910_鞍部','466920_臺北'...]
然後直接把這個陣列元素加上日期字串存成htm (如: '2019-08-01_466910_鞍部.htm')
後來我思考一下 用dictionary來處理可能會更適合這個案例,例如:
location_dict={'466910':'鞍部','466920':'臺北'...}
我這邊把先前給樓主的範例重新寫過,有包含下載錯誤html續傳,下載完成的檔名會是 日期_StationID.htm 範例在最下方 '1_get_weather_htm_data.py'
再來是樓主這裡問到的 已下載完成的htm檔案們如何整理成一個表格
這裡牽涉到的是你的資料要怎麼整理的問題,簡單來說你點
http://e-service.cwb.gov.tw/HistoryDataQuery/index.jsp
進去看 裡面是單日某氣象站從01到24時的記錄,如果你是直接把htm內容塞到xls,那每一筆的日期跟氣象站名要如何記錄? 這個是你需要先規劃好的(視你後續的應用需要哪些值,但日期&氣象站名是必不可少的欄位),這邊我規畫的就是把原本htm的17欄抓出來(第一欄是01~24把它跟日期合併為一個欄位,如'2019-08-01 01:00:00')在最前面加1欄存StationID
如果檔案名稱是未知的情況,dragonH邦友寫的那個方式是很好的方案,不過這邊因為原本我們存htm檔有固定的名稱 (日期_StationID.htm) 這裡的話就用跑廻圈的方式取得日期&StationID即可獲取全部htm檔名,加上前面說的欄位處理,我寫成 '2_read_htm_data_and_save_csv.py'
你先執行 '1_get_weather_htm_data.py'
再執行 '2_read_htm_data_and_save_csv.py'
然後用EXCEL開啟'weather.csv'就知道我說的意思了,以上。
weather.csv內容格式如下:
Station,ObsTime,StnPres,SeaPres,Temperature,Td dew point,RH,WS,WD,WSGust,WDGust,Precp,PrecpHour,SunShine,GloblRad,Visb,UVI,Cloud Amount
466910,2019-08-01 01:00:00,916.7,1486.1,22.2,19.3,84,4.5,190,14.4,200,0.0,0.0,...,0.00,...,0,...
466910,2019-08-01 02:00:00,916.5,1484.1,21.7,19.3,86,5.2,180,12.9,170,0.0,0.0,...,0.00,...,0,...
CSV用Google Sheets開啟demo:
https://docs.google.com/spreadsheets/d/1j2lqR8TSiBTL_IkPtWiyucktg9ZwF89L-3GiHFmxMG8/edit#gid=1412818063
1_get_weather_htm_data.py
import datetime as dt
import requests,time,pathlib,os,re
#######################################################################
#自訂函式區
def get_url_filename(arg):
return re.sub(r'^.*?station=(.*?)&stname=&datepicker=(.*?)$',r'\2_\1',arg)
def log(arg):
with open('log\\event.log','a',encoding='utf-8') as f:
f.writelines(arg+'\n')
f.close()
#######################################################################
base_dir = os.path.dirname(os.path.realpath(__file__))
#判斷log資料夾是否存在,若不存在則建立log資料夾
pathlib.Path(base_dir+"\\log\\").mkdir(parents=True, exist_ok=True)
with open('log\\event.log','w',encoding='utf-8') as f:
pass #這裡用意是把event.log內容清空
f.close()
location_dict={'466910':'鞍部','466920':'臺北','466930':'竹子湖','C0A980':'社子','C0A9A0':'大直','C0A9B0':'石牌','C0A9C0':'天母','C0A9E0':'士林','C0A9F0':'內湖','C0AC40':'大屯山','C0AC70':'信義','C0AC80':'文山','C0AH40':'平等','C0AH70':'松山','C1AC50':'關渡','C1A730':'公館','C0A9G0':'南港','C0A990':'大崙尾山'}
#print(location_dict.keys()) 測試列出location_dict所有key:466910,466920...
startdate = dt.datetime(2019, 8,1)
enddate = dt.datetime(2019, 8,1)
totaldate = (enddate - startdate).days + 1
data_folder='HTML_DATA'
#判斷HTML_DATA資料夾是否存在,若不存在則建立HTML_DATA資料夾
pathlib.Path(data_folder).mkdir(parents=True, exist_ok=True)
#######################################################################
#下載全部html資料到HTML_DATA資料夾
for daynumber in range(totaldate):
datestring = str((startdate + dt.timedelta(days = daynumber)).date())
print(datestring)
#取得單日_全部地點.htm
for i in location_dict.keys():
url="https://e-service.cwb.gov.tw/HistoryDataQuery/DayDataController.do?command=viewMain&station=%s&stname=&datepicker=%s" %(i.split("_")[0],datestring)
#print(url)
try:
r=requests.get(url)
print("Download: "+datestring+"_"+i+".htm")
with open(data_folder+"\\"+datestring+"_"+i+".htm",'w',encoding='utf-8') as f:
f.write(r.text)
f.close()
except:
print("Error: "+datestring+"_"+i+".htm")
log(url)
finally:
time.sleep(5)
print("1. HTML資料下載完畢.")
#######################################################################
#檢查event.log是否為空或有內容,有則表示有資料下載失敗需要重新下載
log_file = (open("log\\event.log", "r"))
download_error_url = log_file.read().split('\n')
log_file.close()
#若download_error_url陣列長度為1時表示是沒有錯誤(只有一列空白行)
#大於1表示有下載錯誤的記錄
if (len(download_error_url))>1:
with open('log\\event.log','w',encoding='utf-8') as f:
pass #這裡用意是把event.log內容清空
f.close()
for i in download_error_url:
if i!='':
try:
r=requests.get(i)
print("Download: "+get_url_filename(i)+".htm")
with open(data_folder+"\\"+get_url_filename(i)+".htm",'w',encoding='utf-8') as f:
f.write(r.text)
f.close()
except:
print("Error: "+get_url_filename(i)+".htm")
log(i)
finally:
time.sleep(5)
print("2. 下載錯誤HTML資料補下載完畢.")
else:
print("2. 檢查完畢,無下載錯誤HTML資料.")
2_read_htm_data_and_save_csv.py
import datetime as dt
import re
#######################################################################
#自訂函式區
def parse_html(arg):
with open(arg,'r',encoding='utf-8') as f:
content=f.read()
f.close()
content=content.replace(' ','').replace(' ','').replace('\t','').replace('\n','').replace(' ','')
hours_data=re.findall('<tr><td nowrap>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td><td>([^<]+)</td></tr>', content)
return hours_data
#######################################################################
location_dict={'466910':'鞍部','466920':'臺北','466930':'竹子湖','C0A980':'社子','C0A9A0':'大直','C0A9B0':'石牌','C0A9C0':'天母','C0A9E0':'士林','C0A9F0':'內湖','C0AC40':'大屯山','C0AC70':'信義','C0AC80':'文山','C0AH40':'平等','C0AH70':'松山','C1AC50':'關渡','C1A730':'公館','C0A9G0':'南港','C0A990':'大崙尾山'}
#print(location_dict.keys()) 測試列出location_dict所有key:466910,466920...
startdate = dt.datetime(2019, 8,1)
enddate = dt.datetime(2019, 8,1)
totaldate = (enddate - startdate).days + 1
data_folder='HTML_DATA'
#######################################################################
#讀取HTML_DATA資料夾內全部html文件,解析HTML源碼後存為weather.csv
with open('weather.csv','w',encoding='utf-8') as f:
f.writelines('Station,ObsTime,StnPres,SeaPres,Temperature,Td dew point,RH,WS,WD,WSGust,WDGust,Precp,PrecpHour,SunShine,GloblRad,Visb,UVI,Cloud Amount\n')
for daynumber in range(totaldate):
datestring = str((startdate + dt.timedelta(days = daynumber)).date())
#print(datestring)
#取得單日_全部地點.htm
for i in location_dict.keys():
print(datestring+str(i))
hours_arr=parse_html(data_folder+"\\"+datestring+"_"+i+".htm")
for j in hours_arr:
print("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n"%(i,datestring+' '+(j[0] if j[0]!='24' else '00')+':00:00',j[1],j[2],j[3],j[4],j[5],j[6],j[7],j[8],j[9],j[10],j[11],j[12],j[13],j[14],j[15],j[16]))
f.writelines("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n"%(i,datestring+' '+(j[0] if j[0]!='24' else '00')+':00:00',j[1],j[2],j[3],j[4],j[5],j[6],j[7],j[8],j[9],j[10],j[11],j[12],j[13],j[14],j[15],j[16]))
f.close()
2_read_htm_data_and_save_csv.py 裡面的自訂函式
def parse_html(arg)
傳入值arg就是從htm檔取得的原始碼,裡面可以看到我用 re.findall(...) 取得符合
<tr><td nowrap>...</td>......</tr>
的全部結果,傳回值是一個陣列:
hours_arr=parse_html(...)
這裡的hours_arr(陣列)就可以用for...in...取得全部的陣列內容,而且是已經把htm裡面不需要的部份剔除掉的內容。
關於re怎麼寫能取到你要的內容,那個牽涉到html源碼長怎樣還有你對RegularExpression的掌握度,這邊就先不說明了。
謝謝你每次這麼熱心回答 , 程式內容迴圈部分不太懂 , 還要仔細註解後才能明白 , 我主要是要看 1/1~5/31 , 6/1~6/30 沒資料可下載 , 所以只能取到 5/31 , 我只要是看有沒有下雨 , 這個天氣要跟 UBIKE 資料搭配來參考 , 因為下雨比較沒有人會租 UBIKE , 來看 UBIKE 的使用率 .
那每一筆的日期跟氣象站名要如何記錄 , 我是想要把 1/1~5/31 弄成一個 EXCEL 檔案 , 主要是站名日期與下雨欄位 , 然後將 UBIKE 資料也加入到這個 EXCEL 檔案 , 最後做樞紐分析 , 感覺資料還不需要寫程式分析 , 另外也是因為樞紐分析比較簡單
不客氣~ 在執行2_read_htm_data_and_save_csv.py 整理之後產生的weather.csv文件,每一列的第一個欄位就是站名啊(StationID 例如466910),假如你想要的是存成中文的站名,那只需把
2_read_htm_data_and_save_csv.py 裡的
f.writelines("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n"%(i,datestring+' '+(j[0] if j[0]!='24' else '00')+':00:00',j[1],j[2],j[3],j[4],j[5],j[6],j[7],j[8],j[9],j[10],j[11],j[12],j[13],j[14],j[15],j[16]))
改成:
f.writelines("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n"%(location_dict[i],datestring+' '+(j[0] if j[0]!='24' else '00')+':00:00',j[1],j[2],j[3],j[4],j[5],j[6],j[7],j[8],j[9],j[10],j[11],j[12],j[13],j[14],j[15],j[16]))
然後再重新跑一次 2_read_htm_data_and_save_csv.py
你的weather.csv的每一列第一欄就會是中文站名了..
如:
鞍部,2019-08-01 01:00:00,916.7,.....後略
備註: i 是 location_dict的key值,location_dict[i]就會得到該key值的value,例如:
i為:'466910'時,location_dict[i]即為:'鞍部'
CSV格式可以直接用EXCEL開啟,後續如果你是要用excel去整合的話,應該是自己動動腦就能解決了。
有空可以幫我看寫的註解是否正確與回答問題嗎 ? 想要用紅色標示註解與問題 , 但沒有顏色可選擇
import datetime as dt #將函數 datetime 指定給 dt
import requests,time,pathlib,os,re
#######################################################################
#自訂函式區
def get_url_filename(arg): #取得網頁檔案
return re.sub(r'^.*?station=(.*?)&stname=&datepicker=(.*?)$',r'\2_\1',arg)
#返回用於替換字符串中的匹配項。這是什麼意思
def log(arg):
#返回 x 的自然对数,要解析的命令行參數列表。這是什麼意思
with open('log\\event.log','a',encoding='utf-8') as f: #打開event.log 'a'新的內容將會被寫入到已有內容之後。如果該文件不存在,創建新文件進行寫入。 utf-8 中文編碼
f.writelines(arg+'\n') #寫入行並換行
f.close() #f是代表 file 嗎 ? 關檔
#######################################################################
base_dir = os.path.dirname(os.path.realpath(__file__))
#判斷log資料夾是否存在,若不存在則建立log資料夾
pathlib.Path(base_dir+"\\log\\").mkdir(parents=True, exist_ok=True)
with open('log\\event.log','w',encoding='utf-8') as f:
pass #這裡用意是把event.log內容清空
f.close()
location_dict={'466910':'鞍部','466920':'臺北','466930':'竹子湖','C0A980':'社子','C0A9A0':'大直','C0A9B0':'石牌','C0A9C0':'天母','C0A9E0':'士林','C0A9F0':'內湖','C0AC40':'大屯山','C0AC70':'信義','C0AC80':'文山','C0AH40':'平等','C0AH70':'松山','C1AC50':'關渡','C1A730':'公館','C0A9G0':'南港','C0A990':'大崙尾山'}
#print(location_dict.keys()) 測試列出location_dict所有key:466910,466920...
startdate = dt.datetime(2019, 8,1)
enddate = dt.datetime(2019, 8,1)
totaldate = (enddate - startdate).days + 1
data_folder='HTML_DATA'
#判斷HTML_DATA資料夾是否存在,若不存在則建立HTML_DATA資料夾
pathlib.Path(data_folder).mkdir(parents=True, exist_ok=True)
#######################################################################
#下載全部html資料到HTML_DATA資料夾
for daynumber in range(totaldate): #迴圈 日期數目在全部日期的範圍內
datestring = str((startdate + dt.timedelta(days = daynumber)).date())
#將日期轉換為字串
print(datestring)
#取得單日_全部地點.htm
for i in location_dict.keys(): # 迴圈 i 從監測站起點到終點下載資料
url="https://e-service.cwb.gov.tw/HistoryDataQuery/DayDataController.do?command=viewMain&station=%s&stname=&datepicker=%s" %(i.split("_")[0],datestring)
#print(url)
try: #異常狀況處裡 ,避免當機產生 r=requests.get(url) 為什麼要設定 r 變數 , 後面沒有引用 r
print("Download: "+datestring+"_"+i+".htm") #列印下載日期 , 當 i 迴圈中斷的地方
with open(data_folder+"\\"+datestring+"_"+i+".htm",'w',encoding='utf-8') as f:
#打開檔案目錄與日期在 i 迴圈
f.write(r.text) #寫入 r.text 檔案
f.close() # 關閉
except:
print("Error: "+datestring+"_"+i+".htm")
#列印錯誤日期在迴圈 i 的何處停止
log(url)
finally:
time.sleep(5)
print("1. HTML資料下載完畢.")
#######################################################################
#檢查event.log是否為空或有內容,有則表示有資料下載失敗需要重新下載
log_file = (open("log\\event.log", "r"))
download_error_url = log_file.read().split('\n')
log_file.close()
#若download_error_url陣列長度為1時表示是沒有錯誤(只有一列空白行)
#大於1表示有下載錯誤的記錄
if (len(download_error_url))>1: #假如下載錯誤網址長度>1
with open('log\\event.log','w',encoding='utf-8') as f:
pass #這裡用意是把event.log內容清空
f.close()
for i in download_error_url: # 迴圈 i 在 下載錯誤網址
if i!='': #假如 i 不等於空白
try: # 異常處理同上
r=requests.get(i)
print("Download: "+get_url_filename(i)+".htm")
with open(data_folder+"\\"+get_url_filename(i)+".htm",'w',encoding='utf-8') as f:
f.write(r.text)
f.close()
except:
print("Error: "+get_url_filename(i)+".htm")
log(i)
finally:
time.sleep(5)
print("2. 下載錯誤HTML資料補下載完畢.")
else:
print("2. 檢查完畢,無下載錯誤HTML資料.")
取得所有 htm 結尾的檔案
code
import os
htmlFiles = [];
for file in os.listdir():
htmlFiles.append(file) if file.endswith('.htm') else None
for file in htmlFiles:
print(file)
# do something
當然你想在第一個迴圈裡寫你的 code 也是可以
感謝你的熱心回復 , 看 99 乘法或是比數字大小的程式就有想法 , 但下面就沒想法 , 只能註解看看是否能搞懂 , 但還是不太懂
import os # 引入作業系統
htmlFiles = []; # 變數 htmlfile = d:\weather\*.htm
for file in os.listdir(): # 迴圈 file in d:\weather\*.htm
htmlFiles.append(file) if file.endswith('.htm') else
# 不知怎麼解釋
None
for file in htmlFiles:
#迴圈 file in htmlfiles
print(file)
# do something
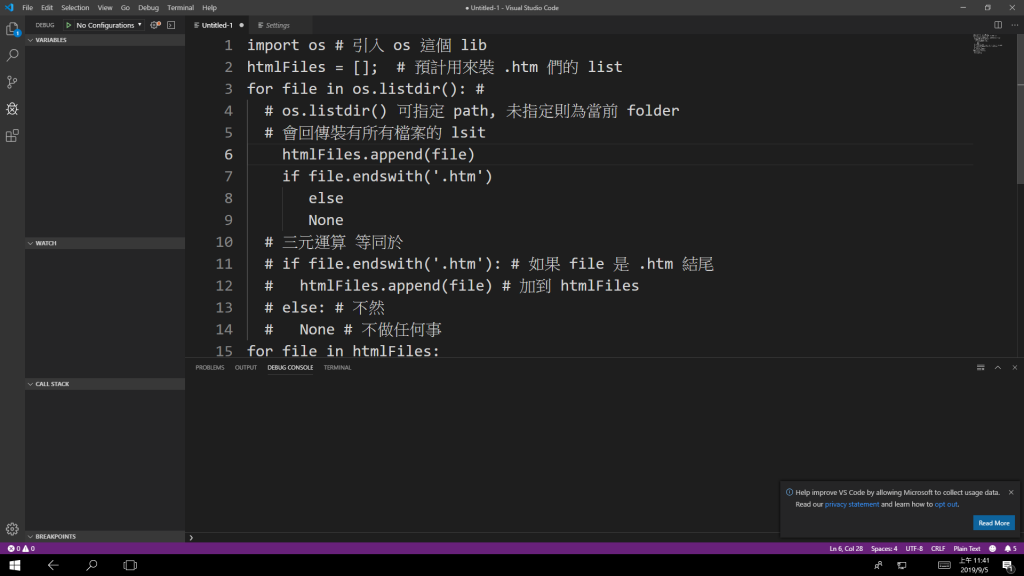
import os # 引入 os 這個 lib
htmlFiles = []; # 預計用來裝 .htm 們的 list
for file in os.listdir(): #
# os.listdir() 可指定 path, 未指定則為當前 folder
# 會回傳裝有所有檔案的 lsit
htmlFiles.append(file) if file.endswith('.htm') else
None
# 三元運算 等同於
# if file.endswith('.htm'): # 如果 file 是 .htm 結尾
# htmlFiles.append(file) # 加到 htmlFiles
# else: # 不然
# None # 不做任何事
for file in htmlFiles:
#迴圈 file in htmlfiles
print(file)
# do something
謝謝你幫我註解 , 我把了解的內容再寫出來如下
import os # 引入 os 這個 lib
htmlFiles = []; # 預計用來裝 .htm 們的 list
是指要轉檔 htm 的目錄嗎 ?
for file in os.listdir(): #
# os.listdir() 可指定 path, 未指定則為當前 folder
# 會回傳裝有所有檔案的 lsit
也是要轉檔 htm 的目錄嗎 ?
htmlFiles.append(file) if file.endswith('.htm') else
None
轉檔 htm 的目錄內的檔案一直增加類似 a+=1 , 判斷是否到最尾端檔案否則不動作
# 三元運算 等同於
# if file.endswith('.htm'): # 如果 file 是 .htm 結尾
# htmlFiles.append(file) # 加到 htmlFiles
# else: # 不然
# None # 不做任何事
for file in htmlFiles:
迴圈在 d:\weather 內搜尋 *.htm
#迴圈 file in htmlfiles
print(file)
轉出 xls 檔案
# do something
是指要轉檔 htm 的目錄嗎 ?
不是..
os.listdir()會回傳所有的檔案名稱
htmlFiles 是預計用來裝後面篩選完後
檔名結尾為 .htm 的檔案名稱
也是要轉檔 htm 的目錄嗎 ?
同上
轉檔 htm 的目錄內的檔案一直增加類似 a+=1 , 判斷是否到最尾端檔案否則不動作
file.endswith('.htm')
是判斷 file(檔案名稱)是否結尾為 .htm
迴圈在 d:\weather 內搜尋 *.htm
找檔案在上面已經結束了
這個迴圈是把過濾完成的檔案們
也就是 htmlfiles
裡面裝的都是 .htm 的檔案
一個一個抓出來看
這些 code並沒有什麼轉不轉檔的東西
基本的上你不知道
os.listdir()
file.endswith('.htm')
htmlFiles
分別會有什麼功用
print() 出來就知道了
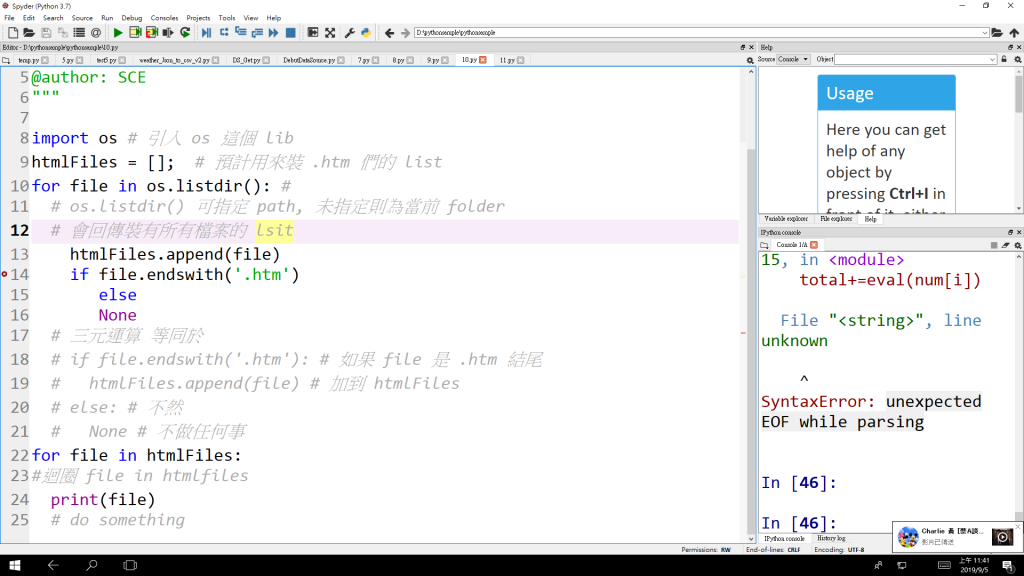
我還以為有轉檔 , 只是要抓出來看 , 是看看是否都是 htm 檔案嗎 ? 執行語法錯誤 , 沒看出來哪裡錯
runfile('D:/pythonsample/pythonsample/10.py', wdir='D:/pythonsample/pythonsample')
Traceback (most recent call last):
File "D:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2961, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-36-0ba421cdb323>", line 1, in <module>
runfile('D:/pythonsample/pythonsample/10.py', wdir='D:/pythonsample/pythonsample')
File "D:\Anaconda3\lib\site-packages\spyder_kernels\customize\spydercustomize.py", line 668, in runfile
execfile(filename, namespace)
File "D:\Anaconda3\lib\site-packages\spyder_kernels\customize\spydercustomize.py", line 108, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "D:/pythonsample/pythonsample/10.py", line 13
htmlFiles.append(file) if file.endswith('.htm') else
^
SyntaxError: invalid syntax
File "D:/pythonsample/pythonsample/10.py", line 13
htmlFiles.append(file) if file.endswith('.htm') else
^
SyntaxError: invalid syntax
SyntaxError: invalid syntax
是
語法錯誤
他已經指出來哪裡有問題了
建議你在看一下我的 code
然後可以的話
挑個有基本 debug 功能的 editor
e.g.
vs code + python plugin
有這種功能的 editor
這種錯誤基本早已被下畫紅線
是 else 後面沒有 code ?
你是說用這個 , 執行是按 ctrl+shift+B 嗎 ?
我是用這個

 iThome鐵人賽
iThome鐵人賽