有一張table如圖1,想把xuid為null的值補上,填補邏輯為圖2,
想請問不寫function,有內建函數或windows function可以處理嗎?
(歡迎其他sql來解)
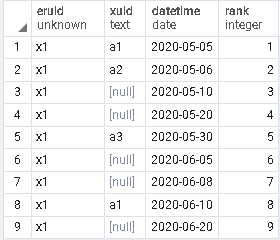
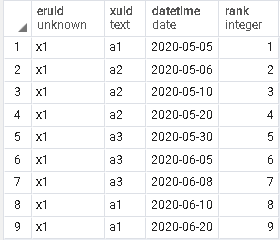
範例table大家可以參考如下。
with temp_1 as
(
select 'x1' eruid,
case
when rank = 1 then 'a1'
when rank = 2 then 'a2'
when rank = 5 then 'a3'
when rank = 8 then 'a1'
else null end xuid,
case
when rank = 1 then '2020-05-05'::date
when rank = 2 then '2020-05-06'::date
when rank = 3 then '2020-05-10'::date
when rank = 4 then '2020-05-20'::date
when rank = 5 then '2020-05-30'::date
when rank = 6 then '2020-06-05'::date
when rank = 7 then '2020-06-08'::date
when rank = 8 then '2020-06-10'::date
when rank = 9 then '2020-06-20'::date
else null end datetime,
rank
from (select generate_series(1,9) rank) a
)
已邀請的邦友 {{ invite_list.length }}/5
要會貼程式碼啊,還浪費了點時間排版.
with temp1 as (
select 'x1' eruid
, case
when rank = 1 then 'a1'
when rank = 2 then 'a2'
when rank = 5 then 'a3'
when rank = 8 then 'a1'
else null end xuid
, case
when rank = 1 then '2020-05-05'::date
when rank = 2 then '2020-05-06'::date
when rank = 3 then '2020-05-10'::date
when rank = 4 then '2020-05-20'::date
when rank = 5 then '2020-05-30'::date
when rank = 6 then '2020-06-05'::date
when rank = 7 then '2020-06-08'::date
when rank = 8 then '2020-06-10'::date
when rank = 9 then '2020-06-20'::date
else null end dt
, rank
from (select generate_series(1,9) rank) a
)
select eruid
, first_value(xuid) over (partition by eruid, grp order by dt) fix_xuid
, dt
, rank
from (select eruid
, xuid
, count(xuid) over (partition by eruid order by dt) as grp
, dt
, rank
from temp1) b;
+-------+----------+------------+------+
| eruid | fix_xuid | dt | rank |
+-------+----------+------------+------+
| x1 | a1 | 2020-05-05 | 1 |
| x1 | a2 | 2020-05-06 | 2 |
| x1 | a2 | 2020-05-10 | 3 |
| x1 | a2 | 2020-05-20 | 4 |
| x1 | a3 | 2020-05-30 | 5 |
| x1 | a3 | 2020-06-05 | 6 |
| x1 | a3 | 2020-06-08 | 7 |
| x1 | a1 | 2020-06-10 | 8 |
| x1 | a1 | 2020-06-20 | 9 |
+-------+----------+------------+------+
(9 rows)
要會貼程式碼啊,
新手如是
來了三年的亦如是
不好意思,昨天太趕著發,忘記排一下!!
先謝謝屠大,晚點來看看。
感謝屠大,非常完美的解決,讓我忍不住說一句好工整阿!!
SQL Command 最好排好,慢慢寫,不要急著寫,擠成一團以後,會很難思考. 沖杯咖啡,放音樂,先寫一部分,然後放著,去洗碗,去洗澡,去散步... 然後靈感出現.
另外補充一下, 還有 NULLS { FIRST | LAST } 可以搭配實際資料情況,或是first_value()的鏡像函數 last_value().
沖杯咖啡,放音樂,去洗碗,去洗澡,去散步
結果我一去就幾個小時
回來就直接上床躺平了
睡一覺,第二天再說,SQL 靠的是靈光乍現,睡的時候腦子會自己組織思考.這個用什麼XX開發,YY開發,都沒法的.
拈花微笑,無法言傳.


 iThome鐵人賽
iThome鐵人賽