各位前輩好, 小弟我第一次發文
最近因公司需要開始學習程式
做資料處理時遇到以下問題: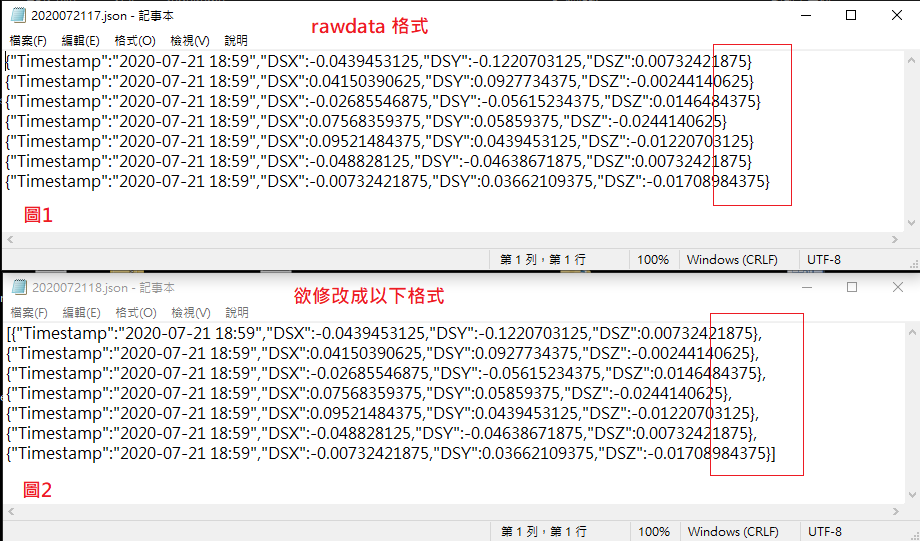
如圖所示, 拿到手上的資料是類似圖1的格式
但是有些地方需要改成圖2那種正常的JSON
開頭與結尾的地方要有[], 每行結束的地方要有,
爬文嘗試用了以下程式碼來執行但卻不如預期
for fn in folder: # 將檔案夾內每個檔案的主檔名與附檔名分開
file_name = os.path.splitext(fn)
if file_name[1] == ".json":
print(file_name[0])
with open(path+fn) as f: #逐步讀取檔案
data = f.readlines()
vl = []
for i in enumerate(data): #修正 json 格式
i.replace("}","},")
請問應該如何下程式碼才能從圖1的格式轉換成圖2的格式
還請各位前輩不吝指教, 會給出最佳解答, 感謝 !!
已邀請的邦友 {{ invite_list.length }}/5
import json
json1 = []
with open(r'D:\\ithelp\20200825.json', 'r') as f:
for item in f.readlines():
json1.append(eval(item))
# json1.append(json.loads(item))
# 也可以
with open(r'D:\\ithelp\20200825-1.json', 'w') as f:
f.write(json.dumps(json1))
把資料來源換成你的資料
japhen 大有提到這樣會變字串
可以用 eval 解決
所以更新一下XD
樓上大哥的方法會讓原來的Rawdata每行變成字串,輸出會變成
["{.............}","{.............}","{......}"]
比較正確的方法是把讀到的rawdata decode成dict再轉
(個人喜好jsonpickle, 比較不會讓中文看起來怪怪的)
import jsonpickle
import os
dictdata = list()
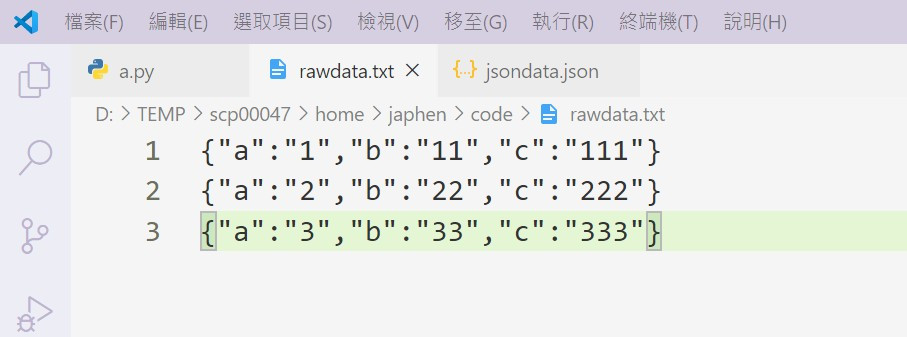
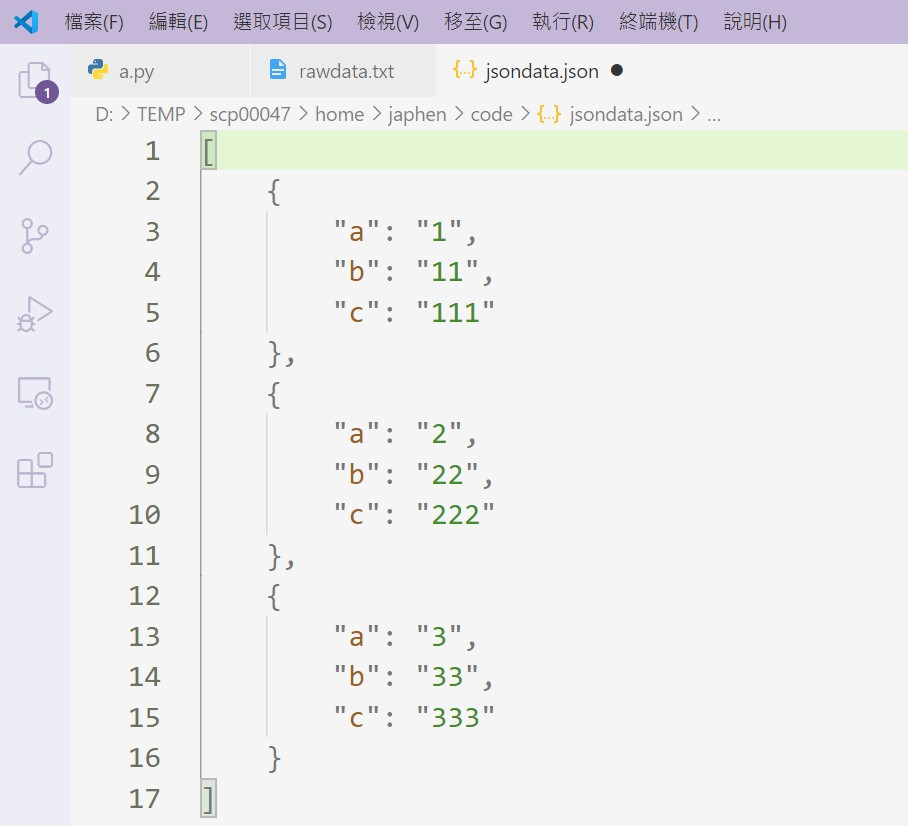
if os.path.exists("rawdata.txt"):
with open('rawdata.txt','r') as rf :
data= rf.readlines()
for line in data:
dictdata.append(jsonpickle.decode(line))
with open('jsondata.json',"w") as wf:
wf.writelines(jsonpickle.encode(dictdata))
我不是大哥
又多學到一招了 不然每次轉中文都變 utf-8
eval 好像也會怪怪的,因為rawdata的{ }跟{ }之間沒有逗點,前後也沒有[ ]
感謝兩位 幫大忙了 ~~
我 rawdata 是一行一行轉
所以是字串轉成 dict 加到陣列裡面
以這個資料來說 這樣轉出來是正常的 XD
咳...一行一行eval沒問題啦,只是個人真的不喜歡eval而已....:P
eval得確保你的資料來源是正常可信任的...
要不然我data插段python code到時候你資料庫怎麼死的都不知道。
尤其python又有script語言的特性...
我是沒測試啦,不過我記得readline應該會連換行都讀進去,或許額外需要處理。
就早期的javascript的eval出過大災難,任意內容都能被eval,誰知道裡面是1+1?還是format("C:") ....... (大誤)
所以我就不喜歡eval 了
前輩再次打擾了, 你的方法我很喜歡
抱歉圖片有點多,今天在使用的時候發生了以下問題
import jsonpickle
import os
path = 'D/0721DATA/'
dictdata = list()
if os.path.exists("2020072119.json"):
with open('D:/0721DATA/2020072119.json','r') as rf :
data= rf.readlines()
for line in data:
dictdata.append(jsonpickle.decode(line))
with open('D:/0721DATA/2020072119_1.json',"w") as wf:
wf.writelines(jsonpickle.encode(dictdata))
else:
print("檔案不存在,請檢查路徑")

回去 rawdata 檢查發現應該是有空行的問題, 如下圖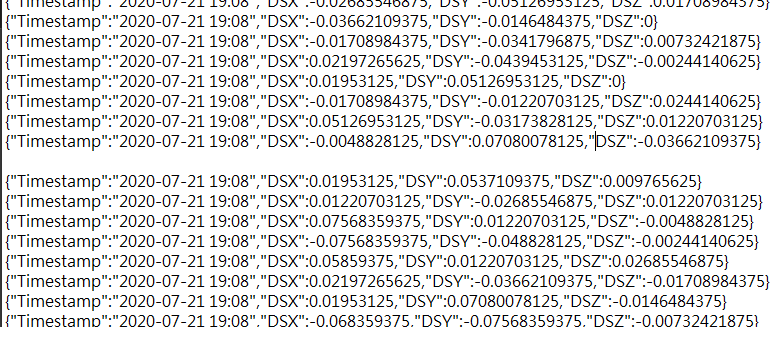
只能讀取空行前的資料, 如下圖
import pandas as pd
df = pd.DataFrame(dictdata)
df
請問前輩在原始資料有這種空行應該要如何解決
是使用 replace 方法將空行取代掉或是有什麼讀取方法呢?
簡單一點
for line in data:
if line.strip() != '' :
dictdata.append(jsonpickle.decode(line))
非常感謝 japhenchen 前輩的幫忙
程式碼順利的完成了 !!
標準一點,麻煩一點,用 re (正則表達式) 檢查語法是否符合dictionary的結構
多一個 import re
import jsonpickle
import os
import re # 正則表達式函式
reDict = re.compile(r'^{([\'\"][^\"^\']+[\'\"]:[\'\"][^\"^\']+[\'\"],*)+}$',re.IGNORECASE)
# 上面我自幹的pattern可以暫時別看懂,我承認正則真的很繞口,但!!!一定要學紮實,這是蹲馬步!用來檢查是否為合法的dictionary字串
path = 'D/0721DATA/'
dictdata = list()
if os.path.exists("2020072119.json"):
with open('D:/0721DATA/2020072119.json','r') as rf :
data= rf.readlines()
for line in data:
if reDict.match(line.strip()): # 避開空行或不合規則
dictdata.append(jsonpickle.decode(line))
with open('D:/0721DATA/2020072119_1.json',"w") as wf:
wf.writelines(jsonpickle.encode(dictdata))
else:
print("檔案不存在,請檢查路徑")
好的, 我再研究看看
謝謝您的補充
不用這麼麻煩吧...
readlines() -> replace("\n", "") -> ",".join() -> 前後加上[] -> json.loads()
下次這種東西最好附測試data。
樓主也說了,中間出現空白行(或許會是有東西不合規則行)
直接load進來或許可能出現無法預期的現象...
CASE BY CASE來寫會比較合乎現況吧
在json的世界裡是允許\n的存在,不用replace也沒關係,不過我還是傾向於逐行檢查再逐行加入新陣列再存檔,因為不可預期的狀況一旦發生,邊際效應下,程式真的難保轉出的資料一定正確(或許可能中途就報錯了)
我的 rawdata 是加速規輸出的資料,檔案很大沒辦法附上
前幾天檢查才發現 rawdata 內會有隔 3 萬筆就出現空行的情形..
依 japhenchen 前輩的方法還蠻順利的,可能資料量大的關係讀取時間稍長(一份 raw data 有 200 萬筆資料),感謝大家的幫忙,初學資料處理,日後有新的問題再請教各位前輩了
