我是剛開始學爬蟲的新手
想從https://xn--i0yt6h0rn.tw/channel/%E5%8F%B0%E8%A6%96/
得到節目表的文字部分
import requests
import bs4
url = "https://xn--i0yt6h0rn.tw/channel/%E5%8F%B0%E8%A6%96/"
header = {"User-Agent":"Moziilla/5.0 (Windows NT 6.1; WOW64)\AppleWebKit/537.6 (KHTML, like Gecko) Chrome/45.0.2454.101\
Safari/537.36"}
tv_show = requests.get(url, headers = header)
tv_show.encoding = "utf-8"
tv_show = bs4.BeautifulSoup(tv_show.text, "html.parser")
item = tv_show.find_all("div",class_="time ng-binding")
for i in item:
print(i.text)
以上是我的程式碼
一直沒按法成功抓取
請大神幫幫忙 謝謝
已邀請的邦友 {{ invite_list.length }}/5
import requests
from bs4 import BeautifulSoup
import json
import pandas as pd
url = "https://節目表.tw/channel/台視/index.json"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
site_json = json.loads(soup.text)
times = []
names = []
for obj in site_json["list"][0]["values"]:
times.append(obj["time"])
names.append(obj["name"])
data = {"時間":times, "節目":names}
df = pd.DataFrame(data)
print(f'{site_json["list"][0]["key"]}的節目表:')
df = df.set_index("時間")
結果圖: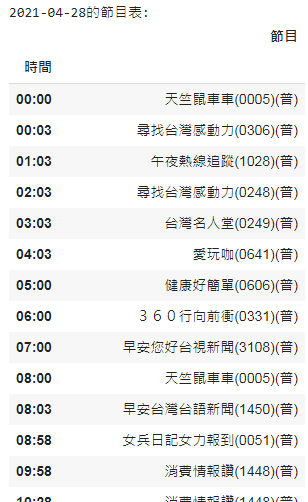
也可以試試改用 requests_html 模組,範例如下:
from requests_html import HTMLSession
url="https://xn--i0yt6h0rn.tw/channel/%E5%8F%B0%E8%A6%96/"
session = HTMLSession()
r = session.get(url)
name_list=list(map(lambda x: x.text, r.html.find('div.name')))
time_list=list(map(lambda x: x.text, r.html.find('div.time')))
for i in range(3,len(name_list)-1):
print(time_list[i],name_list[i])
執行結果如下:
00:03 天竺鼠車車(0005)(普)
01:03 尋找台灣感動力(0306)(普)
02:03 午夜熱線追蹤(1028)(普)
...略...
21:00 加油!美玲(0163)(普)
22:00 加油!美玲(0164)(普)
22:03 天竺鼠車車(0006)(普)
樓主可以在 google 搜 requests_html 可以找到許多教學資源 例如這個: requests-html快速入門
這個庫跟 requests 的差別就是它可以取得 js rendering 之後的頁面內容,當然有些特殊情況下也是抓不到,那種情況下你也許會需要用到selenium+chromedriver,sorry這是題外話了。
太謝謝樓上兩位了!!

 iThome鐵人賽
iThome鐵人賽