import cv2
import imutils
import numpy as np
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
img = cv2.imread('02.jpeg',cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
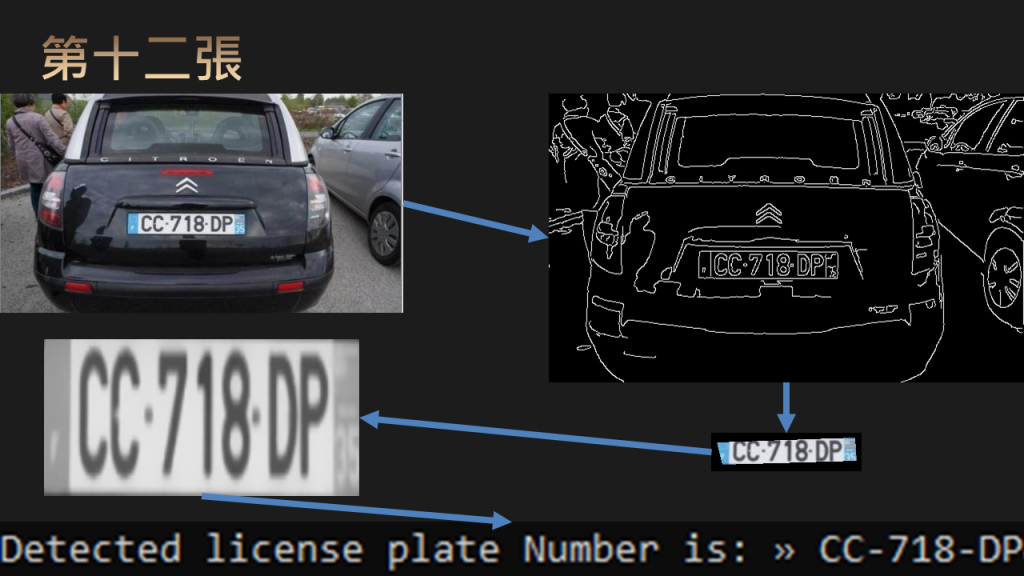
edged = cv2.Canny(gray, 30,150)
cv2.imshow('edged',edged)
cv2.waitKey(0)
contours=cv2.findContours(edged.copy(),cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours,key=cv2.contourArea, reverse = True)[:20]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
print(screenCnt)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
cv2.imshow('new_image',new_image)
cv2.waitKey(0)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("programming_fever's License Plate Recognition\n")
print("Detected license plate Number is:",text)
img = cv2.resize(img,(500,300))
Cropped = cv2.resize(Cropped,(400,200))
cv2.imshow('car',img)
cv2.imshow('Cropped',Cropped)
cv2.waitKey(0)
cv2.destroyAllWindows()
已邀請的邦友 {{ invite_list.length }}/5
想請問,如果tesseract可以達成
怎麼會想用別的辦法?
我自己試過把字元當成物件
用yolov5下去辨識
給你參考。
