各位前輩大家好,有一個問題想請教大家:
目前收到一份PDF, 裡面內容複製出來的文字會變成方塊,
先前遇到此問題通常是電腦安裝相關字型就可解決了,
但這次查看PDF內容的字型集,
是顯示CIDfont+F1,F2,F3,F4...F7,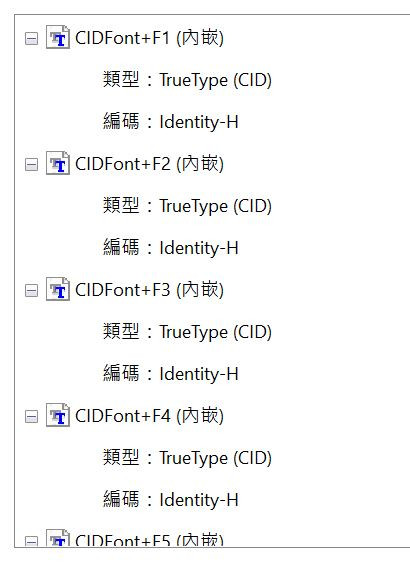
網上查了下資料有點看不太懂,
但感覺是顯示的字體被隱藏了?
以上請教前輩們.
已邀請的邦友 {{ invite_list.length }}/5
但過去我開發能產生 PDF 的軟體時
一開始也是複製後整個都是亂碼的
這是因為那時我只專注在字型的輪廓顯示在螢幕上(可正常列印)
但對於複製後,應該對應哪個 unicode 並沒有處理
也就是說 Identity-H 他有點像是把每個字的輪廓(可以想像類似SVG圖檔)收集起來成一個陣列
當我要在螢幕上顯示這個字時,就用「某陣列的第幾個向量圖」顯示出來
從這個過程可以發現 unicode 的資訊並沒有被定義,所以複製貼上會出問題
(後來有補上 ToUnicode 屬性及相關資料解決)
如果是我上述的狀況,那最快的解決方式是請PDF的提供者重給檔案。
否則就得透過影像辨識或是去解析「字型檔+PDF檔案」,根據PDF檔中字型輪廓的描述,從字型檔中找到原始的 unicode 了。
不過實際上是不是我說的狀況要看到你的檔案才知道。
用文字編輯器打開 PDF 檔案
應該可以找到類似下面的內容
不知道它有沒有如下的 ToUincode 屬性?
(也許有其他形式可以定義複製貼上的映射,這邊僅供參考)
48 0 obj
<<
/Type /Font
/Subtype /Type0
/BaseFont /AAAAAC+NotoSans-MediumItalic
/Encoding /Identity-H
/DescendantFonts [46 0 R]
/ToUnicode 47 0 R
>>
endobj
我大概了解你的意思,謝謝說明.
我剛用文字編輯器看了PDF檔內容,裡面是有ToUnicode的段落,感覺字體應該真的是CIDFont+F1,CIDFont+F2...這些,只是他的編碼特殊(Identity-H),不清楚對方是用甚麼系統導出或者是用甚麼軟體導出的,我目前先請對方重新提供了.
