資料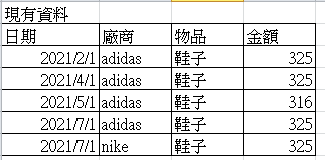
希望結果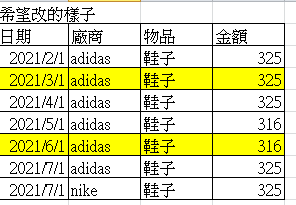
目前卡住的點
我這邊是 拉一個有所有日期的表 然後把資料left join 進去
原本想說用LAST_VALUE 就解決了 結果...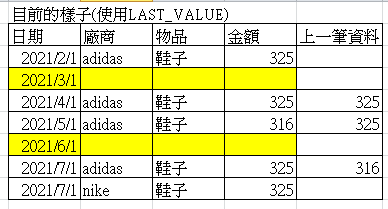
LAST_VALUE(金額 IGNORE NULLS) OVER(
PARTITION BY 廠商,物品
ORDER BY
日期
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
)
目前卡在這裡 想不到下一步 幫個忙 感謝
已邀請的邦友 {{ invite_list.length }}/5
CREATE TABLE TX(
A varchar2(50),
B varchar2(50),
C Nvarchar2(50),
D number(10)
);
INSERT INTO TX (A,B,C,D)
VALUES ('2021/2/1','adidas','鞋子',325);
INSERT INTO TX (A,B,C,D)
VALUES ('2021/4/1','adidas','鞋子',325);
INSERT INTO TX (A,B,C,D)
VALUES ('2021/5/1','adidas','鞋子',316);
INSERT INTO TX (A,B,C,D)
VALUES ('2021/7/1','adidas','鞋子',325);
INSERT INTO TX (A,B,C,D)
VALUES ('2021/7/1','nike','鞋子',325);
CREATE TABLE TY(
A varchar2(50));
INSERT INTO TY (A)
VALUES ('2021/1/1');
INSERT INTO TY (A)
VALUES ('2021/2/1');
INSERT INTO TY (A)
VALUES ('2021/3/1');
INSERT INTO TY (A)
VALUES ('2021/4/1');
INSERT INTO TY (A)
VALUES ('2021/5/1');
INSERT INTO TY (A)
VALUES ('2021/6/1');
INSERT INTO TY (A)
VALUES ('2021/7/1');
SELECT TY.A,
LAST_VALUE(TX.B IGNORE NULLS) OVER (ORDER BY TY.A,TX.B,TX.C) AS B,
LAST_VALUE(TX.C IGNORE NULLS) OVER (ORDER BY TY.A,TX.B,TX.C) AS C,
LAST_VALUE(TX.D IGNORE NULLS) OVER (ORDER BY TY.A,TX.B,TX.C) AS D
FROM TY
LEFT JOIN TX ON TX.A=TY.A
ORDER BY TY.A,TX.B,TX.C
Oracle 不太熟~
MSSQL的話~我是想到這方式@@..
declare @Tab table(
日期 date
,廠商 nvarchar(50)
,物品 nvarchar(50)
,金額 int
)
insert into @Tab
values('2021/2/1','adidas','鞋子','325')
,('2021/4/1','adidas','鞋子','325')
,('2021/5/1','adidas','鞋子','316')
,('2021/7/1','adidas','鞋子','325')
,('2021/7/1','nike','鞋子','325')
declare @TmpDate table(
日期 date
)
insert into @TmpDate
values('2021/2/1')
,('2021/3/1')
,('2021/4/1')
,('2021/5/1')
,('2021/6/1')
,('2021/7/1')
select 設定日
,(
case when 資料日 is null
then (
select top 1 廠商
from @Tab c
where 廠商 = 廠商
and c.日期 < 設定日
order by c.日期 desc
)
else 廠商
end
) 廠商
,(
case when 資料日 is null
then (
select top 1 物品
from @Tab c
where 廠商 = 廠商
and c.日期 < 設定日
order by c.日期 desc
)
else 物品
end
) 物品
,(
case when 資料日 is null
then (
select top 1 金額
from @Tab c
where 廠商 = 廠商
and c.日期 < 設定日
order by c.日期 desc
)
else 金額
end
) 金額
from (
select a.日期 設定日
,b.日期 資料日
,廠商
,物品
,金額
from @TmpDate a
left join @Tab b on a.日期 = b.日期
) k
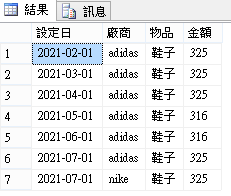
你的 last_value 沒問題. 問題一出在資料庫無法判斷每個商品該出時間與次數. 換句話說, 你先產生完整的表格再讓資料庫作填充題.
簡易做法:
drop table sales;
CREATE TABLE sales(
edate date,
ebrand varchar2(20),
eproduct varchar2(20),
eamount number
);
INSERT INTO sales
VALUES (to_date('2021/2/1','YYYY/MM/DD'),'adidas','shoe',325);
INSERT INTO sales
VALUES (to_date('2021/4/1','YYYY/MM/DD'),'adidas','shoe',315);
INSERT INTO sales
VALUES (to_date('2021/5/1','YYYY/MM/DD'),'adidas','shoe',316);
INSERT INTO sales
VALUES (to_date('2021/9/1','YYYY/MM/DD'),'adidas','shoe',456);
INSERT INTO sales
VALUES (to_date('2021/2/1','YYYY/MM/DD'),'nike','shoe',325);
INSERT INTO sales
VALUES (to_date('2021/8/1','YYYY/MM/DD'),'nike','shoe',123);
commit;
with xx as (
select add_months(to_date('01/01/2021','MM/DD/YYYY'),level) edate from dual connect by level<10
), yy as (
select 'adidas' ebrand from dual
union all
select 'nike' ebrand from dual
), zz as (
select 'shoe' eproduct from dual
)
select *
from xx,yy,zz
order by 2,3,1;
select * from sales;
with xx as (
select add_months(to_date('01/01/2021','MM/DD/YYYY'),level) edate from dual connect by level<10
), yy as (
select 'adidas' ebrand from dual
union all
select 'nike' ebrand from dual
), zz as (
select 'shoe' eproduct from dual
), kkk as (
select *
from xx,yy,zz
)
select kkk.*,sales.*
,last_value(sales.eamount ignore nulls) over (partition by kkk.ebrand,kkk.eproduct order by kkk.edate rows between unbounded preceding and current row) yy
from kkk
left join sales on kkk.edate=sales.edate and kkk.ebrand=sales.ebrand and kkk.eproduct=sales.eproduct
order by 2,3,1;
成品: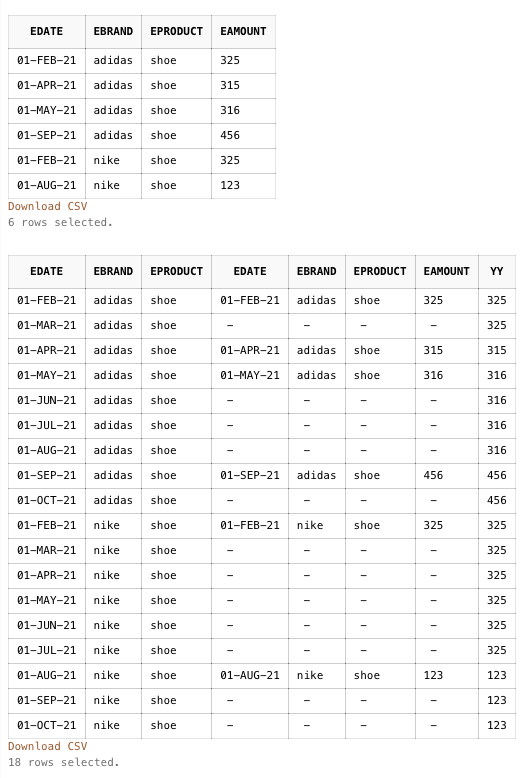
當然你準備填空的表格可以更華麗一點. 上面的範例假設時間, 品牌與產品都一樣要填空. 你可以繼續客製化. (不過我假設你這個大慨率是要給 BI 做表格/圖表的, 所以應該是屬於可直接服用狀態)
好奇問一下 如果我分類有一百多筆
select 'XXX' ebrand from dual 這邊該怎麼做
with xx as (
select add_months(to_date('01/01/2021','MM/DD/YYYY'),level) edate from dual connect by level<10
),kkk as (
select distinct xx.edate,sales.ebrand,sales.eproduct
from xx,sales
)
select kkk.*,sales.*
,last_value(sales.eamount ignore nulls) over (partition by kkk.ebrand,kkk.eproduct order by kkk.edate rows between unbounded preceding and current row) yy
from kkk
left join sales on kkk.edate=sales.edate and kkk.ebrand=sales.ebrand and kkk.eproduct=sales.eproduct
order by 2,3,1;
如果你的分類只有一百多筆, 那通常的做法有
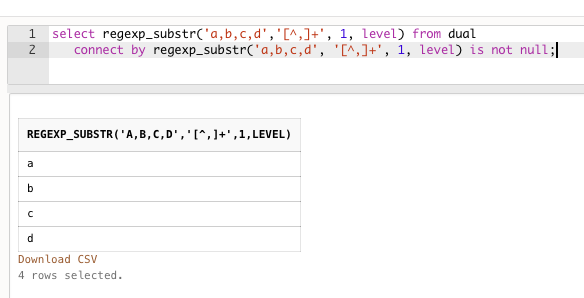
例如:
select regexp_substr('a,b,c,d','[^,]+', 1, level)
from dual
connect by regexp_substr('a,b,c,d', '[^,]+', 1, level) is not null;
如果你的資料更多的話. (如十萬筆以上) 那我會推薦使用暫存表格. Global/Private (18c 以上) temporary table.



 iThome鐵人賽
iThome鐵人賽