各位大大早安~
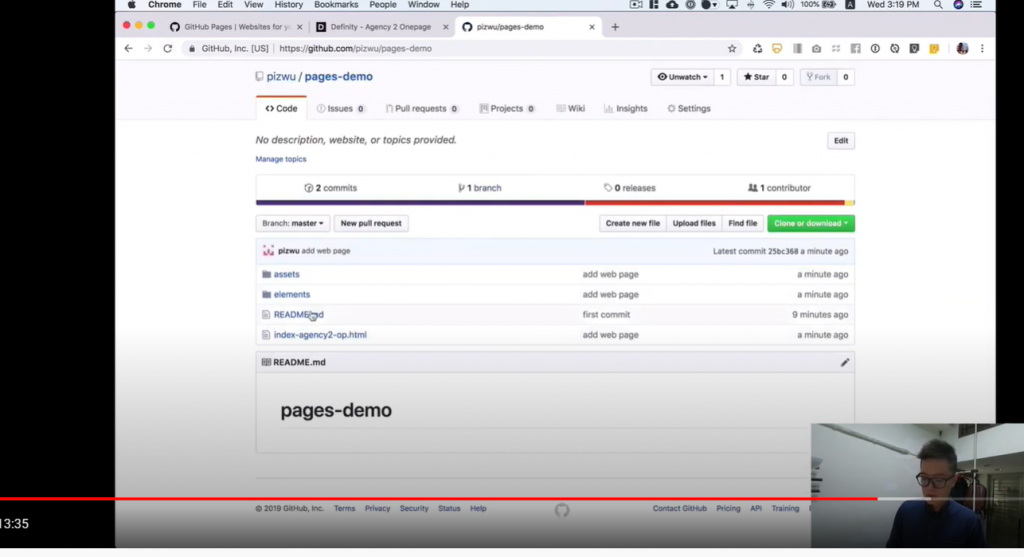
事情是這樣的我在模仿Github Pages / 把做好的網頁秀在網路上【免費!!】
https://www.youtube.com/watch?v=lzEZI9wzPYU
發現從cmd在增加code時就無法與影片同步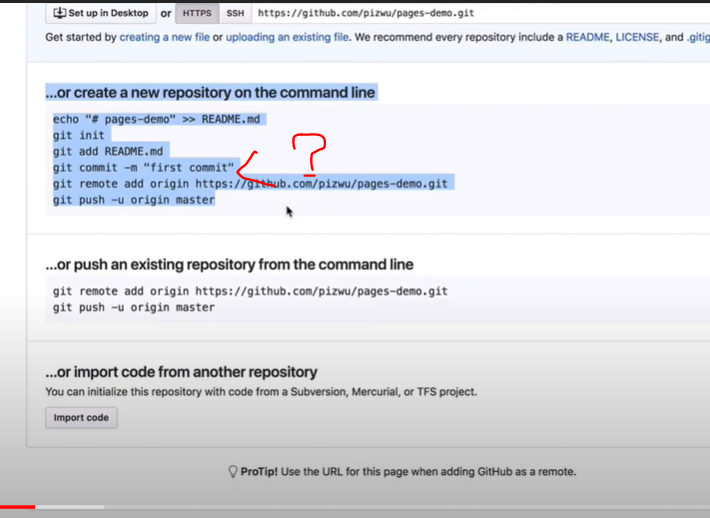
影片的github的上傳code我多了一行
現在發現的問題是我的github無法跟本機的電腦連線
檔案無法新增
不知道為什麼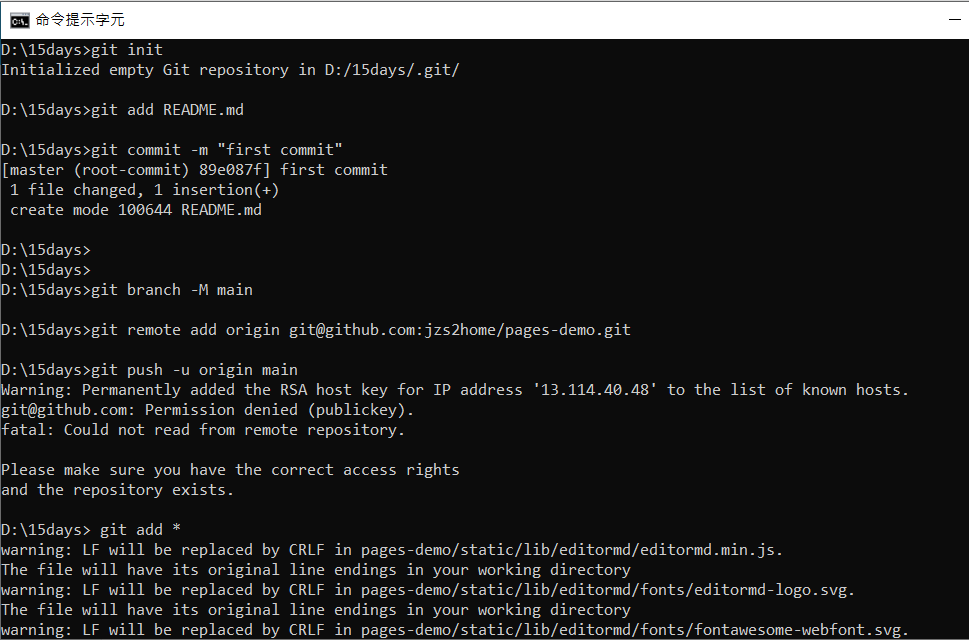
我的cmd語法:
Microsoft Windows [Version 10.0.19042.1237]
(c) Microsoft Corporation. All rights reserved.
C:\Users\User> cd D:\15days
C:\Users\User>D:
D:\15days>mkdir pages-demo
D:\15days>echo "# pages-demo" >> README.md
D:\15days>git init
Initialized empty Git repository in D:/15days/.git/
D:\15days>git add README.md
D:\15days>git commit -m "first commit"
[master (root-commit) 89e087f] first commit
1 file changed, 1 insertion(+)
create mode 100644 README.md
D:\15days>
D:\15days>
D:\15days>git branch -M main
D:\15days>git remote add origin git@github.com:jzs2home/pages-demo.git
D:\15days>git push -u origin main
Warning: Permanently added the RSA host key for IP address '13.114.40.48' to the list of known hosts.
git@github.com: Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
D:\15days> git add *
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/editormd.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/fonts/editormd-logo.svg.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/fonts/fontawesome-webfont.svg.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/AUTHORS.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/LICENSE.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/README.md.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/comment/comment.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/comment/continuecomment.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/dialog/dialog.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/dialog/dialog.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/display/fullscreen.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/display/fullscreen.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/display/panel.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/display/placeholder.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/display/rulers.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/edit/closebrackets.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/edit/closetag.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/edit/continuelist.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/edit/matchbrackets.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/edit/matchtags.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/edit/trailingspace.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/brace-fold.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/comment-fold.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/foldcode.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/foldgutter.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/foldgutter.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/indent-fold.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/markdown-fold.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/fold/xml-fold.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/anyword-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/css-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/html-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/javascript-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/show-hint.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/show-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/sql-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/hint/xml-hint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/coffeescript-lint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/css-lint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/javascript-lint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/json-lint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/lint.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/lint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/lint/yaml-lint.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/merge/merge.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/merge/merge.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/mode/loadmode.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/mode/multiplex.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/mode/multiplex_test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/mode/overlay.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/mode/simple.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/colorize.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/runmode-standalone.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/runmode.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/runmode.node.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/annotatescrollbar.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/scrollpastend.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/simplescrollbars.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/simplescrollbars.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/search/match-highlighter.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/search/matchesonscrollbar.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/search/matchesonscrollbar.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/search/search.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/search/searchcursor.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/selection/active-line.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/selection/mark-selection.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/selection/selection-pointer.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/tern/tern.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/tern/tern.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/tern/worker.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addon/wrap/hardwrap.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/addons.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/bower.json.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/codemirror.min.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/codemirror.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/lib/codemirror.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/lib/codemirror.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/apl/apl.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/apl/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/asterisk/asterisk.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/asterisk/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/clike/clike.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/clike/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/clike/scala.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/clojure/clojure.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/clojure/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/cobol/cobol.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/cobol/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/coffeescript/coffeescript.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/coffeescript/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/commonlisp/commonlisp.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/commonlisp/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/css.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/less.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/less_test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/scss.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/scss_test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/css/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/cypher/cypher.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/cypher/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/d/d.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/d/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dart/dart.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dart/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/diff/diff.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/diff/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/django/django.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/django/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dockerfile/dockerfile.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dockerfile/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dtd/dtd.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dtd/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dylan/dylan.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/dylan/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ebnf/ebnf.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ebnf/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ecl/ecl.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ecl/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/eiffel/eiffel.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/eiffel/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/erlang/erlang.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/erlang/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/forth/forth.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/forth/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/fortran/fortran.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/fortran/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gas/gas.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gas/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gfm/gfm.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gfm/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gfm/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gherkin/gherkin.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/gherkin/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/go/go.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/go/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/groovy/groovy.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/groovy/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haml/haml.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haml/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haml/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haskell/haskell.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haskell/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haxe/haxe.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/haxe/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/htmlembedded/htmlembedded.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/htmlembedded/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/htmlmixed/htmlmixed.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/htmlmixed/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/http/http.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/http/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/idl/idl.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/idl/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/jade/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/jade/jade.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/javascript.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/json-ld.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/typescript.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/jinja2/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/jinja2/jinja2.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/julia/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/julia/julia.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/kotlin/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/kotlin/kotlin.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/livescript/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/livescript/livescript.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/lua/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/lua/lua.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/markdown/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/markdown/markdown.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/markdown/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/meta.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/mirc/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/mirc/mirc.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/mllike/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/mllike/mllike.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/modelica/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/modelica/modelica.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/nginx/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/nginx/nginx.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ntriples/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ntriples/ntriples.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/octave/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/octave/octave.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/pascal/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/pascal/pascal.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/pegjs/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/pegjs/pegjs.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/perl/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/perl/perl.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/php/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/php/php.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/php/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/pig/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/pig/pig.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/properties/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/properties/properties.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/puppet/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/puppet/puppet.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/python/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/python/python.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/q/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/q/q.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/r/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/r/r.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rpm/changes/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rpm/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rpm/rpm.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rst/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rst/rst.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ruby/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ruby/ruby.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/ruby/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rust/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/rust/rust.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sass/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sass/sass.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/scheme/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/scheme/scheme.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/shell/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/shell/shell.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/shell/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sieve/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sieve/sieve.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/slim/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/slim/slim.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/slim/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/smalltalk/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/smalltalk/smalltalk.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/smarty/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/smarty/smarty.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/smartymixed/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/smartymixed/smartymixed.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/solr/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/solr/solr.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/soy/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/soy/soy.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sparql/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sparql/sparql.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/spreadsheet/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/spreadsheet/spreadsheet.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sql/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/sql/sql.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/stex/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/stex/stex.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/stex/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/stylus/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/stylus/stylus.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tcl/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tcl/tcl.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/textile/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/textile/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/textile/textile.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tiddlywiki/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tiddlywiki/tiddlywiki.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tiddlywiki/tiddlywiki.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tiki/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tiki/tiki.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tiki/tiki.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/toml/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/toml/toml.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tornado/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/tornado/tornado.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/turtle/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/turtle/turtle.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/vb/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/vb/vb.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/vbscript/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/vbscript/vbscript.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/velocity/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/velocity/velocity.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/verilog/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/verilog/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/verilog/verilog.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/xml/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/xml/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/xml/xml.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/xquery/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/xquery/test.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/xquery/xquery.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/yaml/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/yaml/yaml.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/z80/index.html.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/mode/z80/z80.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/modes.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/package.json.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/3024-day.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/3024-night.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/ambiance-mobile.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/ambiance.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/base16-dark.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/base16-light.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/blackboard.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/cobalt.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/colorforth.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/eclipse.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/elegant.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/erlang-dark.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/lesser-dark.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/mbo.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/mdn-like.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/midnight.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/monokai.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/neat.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/neo.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/night.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/paraiso-dark.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/paraiso-light.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/pastel-on-dark.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/rubyblue.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/solarized.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/the-matrix.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/tomorrow-night-bright.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/tomorrow-night-eighties.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/twilight.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/vibrant-ink.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/xq-dark.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/xq-light.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/codemirror/theme/zenburn.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/flowchart.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/marked.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/prettify.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/raphael.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/lib/editormd/lib/sequence-diagram.min.js.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/tocbot/styles.css.
The file will have its original line endings in your working directory
warning: LF will be replaced by CRLF in pages-demo/static/tocbot/tocbot.css.
The file will have its original line endings in your working directory
D:\15days> git com
我的github也沒有新增檔案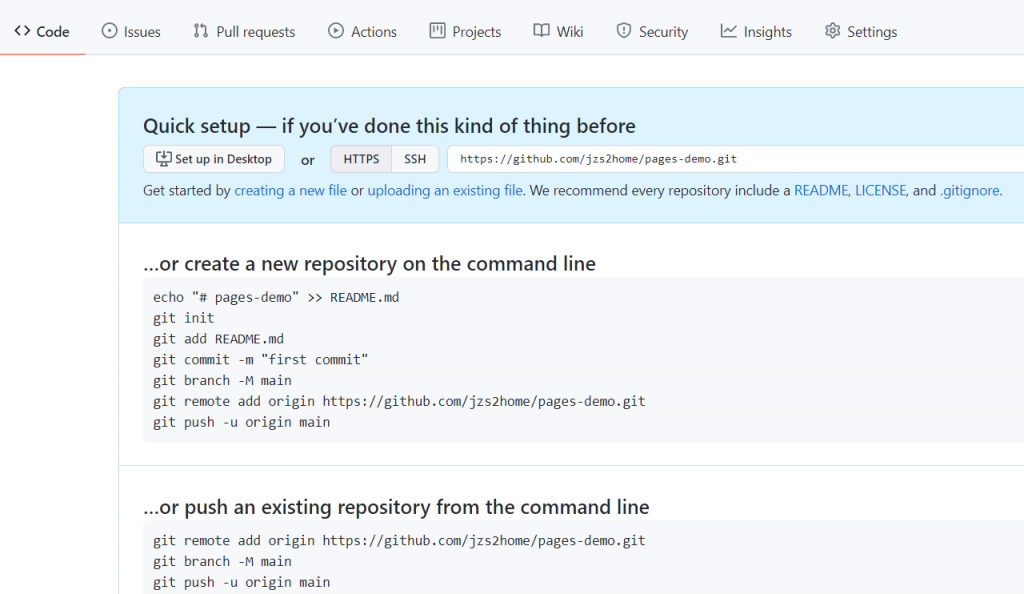
還是空白的阿~
明明資料夾裡面按照語法都有阿~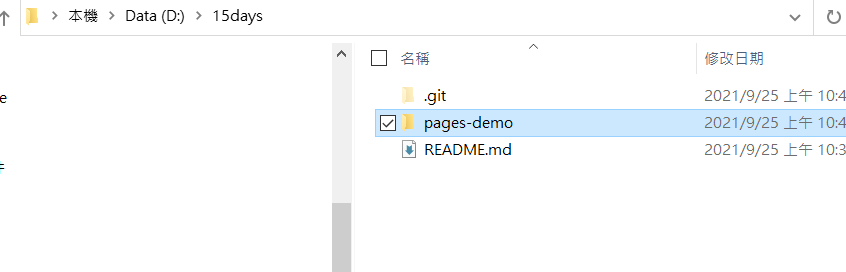
要怎樣才能像影片成功跟git連線
希望有大大可以指點迷津
已邀請的邦友 {{ invite_list.length }}/5
cmd 有提到:
Warning: Permanently added the RSA host key for IP address '13.114.40.48' to the list of known hosts.
以及
Please make sure you have the correct access rights
and the repository exists.
Try it!
Microsoft Windows [Version 10.0.19042.1237]
(c) Microsoft Corporation. All rights reserved.
C:\Users\User> cd D:\15days
C:\Users\User>D:
D:\15days>git init
Reinitialized existing Git repository in D:/15days/.git/
D:\15days>git add README.md
D:\15days>git commit -m "first commit"
[main 4d3d940] first commit
409 files changed, 77078 insertions(+)
create mode 100644 pages-demo/.idea/.gitignore
create mode 100644 pages-demo/.idea/blog.iml
create mode 100644 pages-demo/.idea/misc.xml
create mode 100644 pages-demo/.idea/modules.xml
create mode 100644 pages-demo/about.html
create mode 100644 pages-demo/admin/blogs-input.html
create mode 100644 pages-demo/admin/blogs.html
create mode 100644 pages-demo/archives.html
create mode 100644 pages-demo/blog.html
create mode 100644 pages-demo/index.html
create mode 100644 pages-demo/static/css/me.css
create mode 100644 pages-demo/static/images/bg_natural_sougen.jpg
create mode 100644 pages-demo/static/images/earth_nature_futaba.png
create mode 100644 pages-demo/static/images/fantasy_pixy2.png
create mode 100644 pages-demo/static/images/kokage_tree_necchusyou_drink.png
create mode 100644 pages-demo/static/images/lucky_yotsuba_clover_girl.png
create mode 100644 pages-demo/static/images/nouka_hiryou_sehi.png
create mode 100644 pages-demo/static/images/wechat.jpg
create mode 100644 pages-demo/static/images/youkai_yukionna.png
create mode 100644 pages-demo/static/lib/editormd/css/editormd.css
create mode 100644 pages-demo/static/lib/editormd/css/editormd.logo.css
create mode 100644 pages-demo/static/lib/editormd/css/editormd.logo.min.css
create mode 100644 pages-demo/static/lib/editormd/css/editormd.min.css
create mode 100644 pages-demo/static/lib/editormd/css/editormd.preview.css
create mode 100644 pages-demo/static/lib/editormd/css/editormd.preview.min.css
create mode 100644 pages-demo/static/lib/editormd/editormd.js
create mode 100644 pages-demo/static/lib/editormd/editormd.min.js
create mode 100644 pages-demo/static/lib/editormd/fonts/FontAwesome.otf
create mode 100644 pages-demo/static/lib/editormd/fonts/editormd-logo.eot
create mode 100644 pages-demo/static/lib/editormd/fonts/editormd-logo.svg
create mode 100644 pages-demo/static/lib/editormd/fonts/editormd-logo.ttf
create mode 100644 pages-demo/static/lib/editormd/fonts/editormd-logo.woff
create mode 100644 pages-demo/static/lib/editormd/fonts/fontawesome-webfont.eot
create mode 100644 pages-demo/static/lib/editormd/fonts/fontawesome-webfont.svg
create mode 100644 pages-demo/static/lib/editormd/fonts/fontawesome-webfont.ttf
create mode 100644 pages-demo/static/lib/editormd/fonts/fontawesome-webfont.woff
create mode 100644 pages-demo/static/lib/editormd/fonts/fontawesome-webfont.woff2
create mode 100644 pages-demo/static/lib/editormd/images/loading.gif
create mode 100644 pages-demo/static/lib/editormd/images/loading@2x.gif
create mode 100644 pages-demo/static/lib/editormd/images/loading@3x.gif
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-favicon-16x16.ico
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-favicon-24x24.ico
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-favicon-32x32.ico
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-favicon-48x48.ico
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-favicon-64x64.ico
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-114x114.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-120x120.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-144x144.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-16x16.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-180x180.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-240x240.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-24x24.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-320x320.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-32x32.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-48x48.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-57x57.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-64x64.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-72x72.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/editormd-logo-96x96.png
create mode 100644 pages-demo/static/lib/editormd/images/logos/vi.png
create mode 100644 pages-demo/static/lib/editormd/languages/en.js
create mode 100644 pages-demo/static/lib/editormd/languages/zh-tw.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/AUTHORS
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/LICENSE
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/README.md
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/comment/comment.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/comment/continuecomment.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/dialog/dialog.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/dialog/dialog.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/display/fullscreen.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/display/fullscreen.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/display/panel.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/display/placeholder.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/display/rulers.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/edit/closebrackets.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/edit/closetag.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/edit/continuelist.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/edit/matchbrackets.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/edit/matchtags.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/edit/trailingspace.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/brace-fold.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/comment-fold.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/foldcode.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/foldgutter.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/foldgutter.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/indent-fold.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/markdown-fold.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/fold/xml-fold.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/anyword-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/css-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/html-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/javascript-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/show-hint.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/show-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/sql-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/hint/xml-hint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/coffeescript-lint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/css-lint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/javascript-lint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/json-lint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/lint.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/lint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/lint/yaml-lint.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/merge/merge.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/merge/merge.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/mode/loadmode.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/mode/multiplex.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/mode/multiplex_test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/mode/overlay.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/mode/simple.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/colorize.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/runmode-standalone.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/runmode.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/runmode/runmode.node.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/annotatescrollbar.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/scrollpastend.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/simplescrollbars.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/scroll/simplescrollbars.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/search/match-highlighter.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/search/matchesonscrollbar.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/search/matchesonscrollbar.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/search/search.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/search/searchcursor.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/selection/active-line.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/selection/mark-selection.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/selection/selection-pointer.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/tern/tern.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/tern/tern.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/tern/worker.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addon/wrap/hardwrap.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/addons.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/bower.json
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/codemirror.min.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/codemirror.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/lib/codemirror.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/lib/codemirror.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/apl/apl.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/apl/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/asterisk/asterisk.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/asterisk/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/clike/clike.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/clike/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/clike/scala.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/clojure/clojure.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/clojure/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/cobol/cobol.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/cobol/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/coffeescript/coffeescript.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/coffeescript/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/commonlisp/commonlisp.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/commonlisp/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/css.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/less.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/less_test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/scss.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/scss_test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/css/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/cypher/cypher.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/cypher/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/d/d.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/d/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dart/dart.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dart/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/diff/diff.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/diff/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/django/django.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/django/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dockerfile/dockerfile.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dockerfile/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dtd/dtd.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dtd/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dylan/dylan.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/dylan/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ebnf/ebnf.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ebnf/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ecl/ecl.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ecl/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/eiffel/eiffel.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/eiffel/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/erlang/erlang.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/erlang/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/forth/forth.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/forth/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/fortran/fortran.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/fortran/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gas/gas.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gas/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gfm/gfm.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gfm/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gfm/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gherkin/gherkin.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/gherkin/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/go/go.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/go/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/groovy/groovy.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/groovy/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haml/haml.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haml/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haml/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haskell/haskell.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haskell/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haxe/haxe.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/haxe/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/htmlembedded/htmlembedded.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/htmlembedded/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/htmlmixed/htmlmixed.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/htmlmixed/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/http/http.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/http/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/idl/idl.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/idl/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/jade/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/jade/jade.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/javascript.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/json-ld.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/javascript/typescript.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/jinja2/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/jinja2/jinja2.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/julia/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/julia/julia.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/kotlin/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/kotlin/kotlin.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/livescript/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/livescript/livescript.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/lua/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/lua/lua.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/markdown/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/markdown/markdown.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/markdown/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/meta.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/mirc/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/mirc/mirc.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/mllike/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/mllike/mllike.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/modelica/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/modelica/modelica.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/nginx/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/nginx/nginx.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ntriples/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ntriples/ntriples.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/octave/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/octave/octave.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/pascal/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/pascal/pascal.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/pegjs/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/pegjs/pegjs.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/perl/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/perl/perl.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/php/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/php/php.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/php/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/pig/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/pig/pig.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/properties/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/properties/properties.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/puppet/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/puppet/puppet.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/python/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/python/python.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/q/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/q/q.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/r/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/r/r.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rpm/changes/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rpm/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rpm/rpm.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rst/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rst/rst.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ruby/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ruby/ruby.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/ruby/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rust/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/rust/rust.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sass/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sass/sass.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/scheme/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/scheme/scheme.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/shell/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/shell/shell.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/shell/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sieve/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sieve/sieve.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/slim/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/slim/slim.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/slim/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/smalltalk/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/smalltalk/smalltalk.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/smarty/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/smarty/smarty.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/smartymixed/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/smartymixed/smartymixed.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/solr/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/solr/solr.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/soy/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/soy/soy.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sparql/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sparql/sparql.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/spreadsheet/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/spreadsheet/spreadsheet.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sql/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/sql/sql.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/stex/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/stex/stex.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/stex/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/stylus/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/stylus/stylus.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tcl/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tcl/tcl.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/textile/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/textile/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/textile/textile.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tiddlywiki/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tiddlywiki/tiddlywiki.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tiddlywiki/tiddlywiki.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tiki/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tiki/tiki.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tiki/tiki.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/toml/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/toml/toml.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tornado/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/tornado/tornado.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/turtle/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/turtle/turtle.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/vb/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/vb/vb.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/vbscript/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/vbscript/vbscript.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/velocity/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/velocity/velocity.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/verilog/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/verilog/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/verilog/verilog.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/xml/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/xml/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/xml/xml.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/xquery/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/xquery/test.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/xquery/xquery.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/yaml/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/yaml/yaml.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/z80/index.html
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/mode/z80/z80.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/modes.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/package.json
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/3024-day.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/3024-night.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/ambiance-mobile.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/ambiance.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/base16-dark.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/base16-light.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/blackboard.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/cobalt.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/colorforth.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/eclipse.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/elegant.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/erlang-dark.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/lesser-dark.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/mbo.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/mdn-like.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/midnight.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/monokai.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/neat.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/neo.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/night.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/paraiso-dark.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/paraiso-light.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/pastel-on-dark.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/rubyblue.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/solarized.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/the-matrix.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/tomorrow-night-bright.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/tomorrow-night-eighties.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/twilight.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/vibrant-ink.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/xq-dark.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/xq-light.css
create mode 100644 pages-demo/static/lib/editormd/lib/codemirror/theme/zenburn.css
create mode 100644 pages-demo/static/lib/editormd/lib/flowchart.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/jquery.flowchart.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/marked.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/prettify.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/raphael.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/sequence-diagram.min.js
create mode 100644 pages-demo/static/lib/editormd/lib/underscore.min.js
create mode 100644 pages-demo/static/lib/editormd/plugins/code-block-dialog/code-block-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/emoji-dialog/emoji-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/emoji-dialog/emoji.json
create mode 100644 pages-demo/static/lib/editormd/plugins/goto-line-dialog/goto-line-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/help-dialog/help-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/help-dialog/help.md
create mode 100644 pages-demo/static/lib/editormd/plugins/html-entities-dialog/html-entities-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/html-entities-dialog/html-entities.json
create mode 100644 pages-demo/static/lib/editormd/plugins/image-dialog/image-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/link-dialog/link-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/plugin-template.js
create mode 100644 pages-demo/static/lib/editormd/plugins/preformatted-text-dialog/preformatted-text-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/reference-link-dialog/reference-link-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/table-dialog/table-dialog.js
create mode 100644 pages-demo/static/lib/editormd/plugins/test-plugin/test-plugin.js
create mode 100644 pages-demo/static/tocbot/styles.css
create mode 100644 pages-demo/static/tocbot/tocbot.css
create mode 100644 pages-demo/static/tocbot/tocbot.js
create mode 100644 pages-demo/static/tocbot/tocbot.min.js
create mode 100644 pages-demo/tages.html
create mode 100644 pages-demo/types.html
D:\15days>git branch -M main
D:\15days>git remote add origin https://github.com/jzs2home/pages-demo.git
fatal: remote origin already exists.
D:\15days>git push -u origin main
Warning: Permanently added the RSA host key for IP address '52.192.72.89' to the list of known hosts.
git@github.com: Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
D:\15days>13.114.40.48 github.com
'13.114.40.48' is not recognized as an internal or external command,
operable program or batch file.
D:\15days>
還沒有找到方法......QQ
查了這篇 現在到這裡~不知道下一步 QQ
D:\15days>git remote add origin https://github.com/jzs2home/pages-demo.git
fatal: remote origin already exists.
D:\15days>git remote set-url origin https://github.com/jzs2home/pages-demo.git
D:\15days>git remote -v
origin https://github.com/jzs2home/pages-demo.git (fetch)
origin https://github.com/jzs2home/pages-demo.git (push)
D:\15days>git pull
There is no tracking information for the current branch.
Please specify which branch you want to merge with.
See git-pull(1) for details.
git pull <remote> <branch>
If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to=origin/<branch> main
Tzu
其實 CMD 都有告訴你錯在哪,像是:
Please specify which branch you want to merge with.
See git-pull(1) for details.
git pull <remote> <branch>
這邊就告訴你要輸入遠端節點與本地分支的名稱:
git pull origin master
不只如此,他還說 If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to origin/master
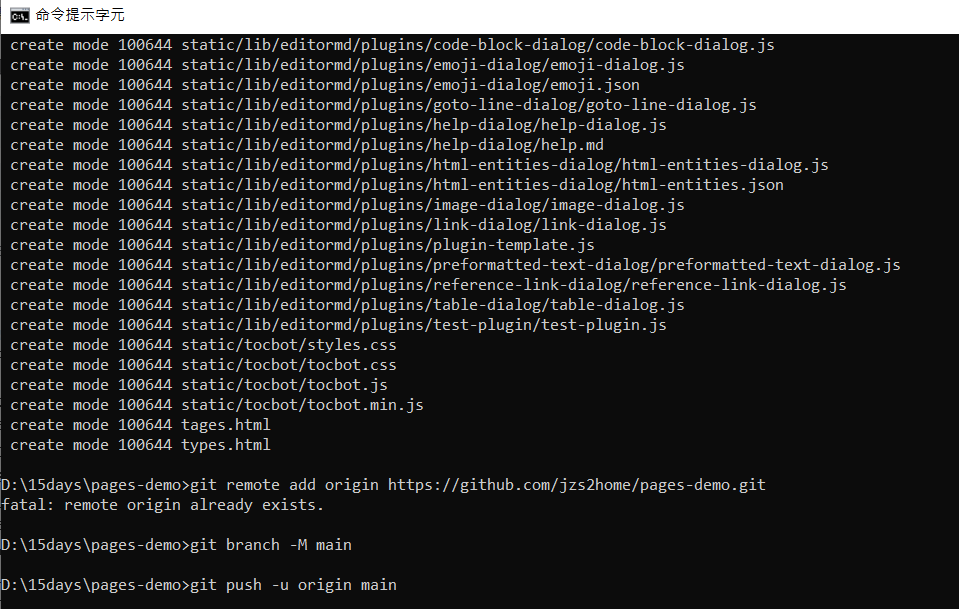
https://blog.csdn.net/weixin_41010198/article/details/119698015
後來發現是密碼變成token
但是還是推不上去
我已經找不到方法了
一直卡在這裡
usage: git remote set-url [--push] <name> <newurl> [<oldurl>]
or: git remote set-url --add <name> <newurl>
or: git remote set-url --delete <name> <url>
--push manipulate push URLs
--add add URL
--delete delete URLs

 iThome鐵人賽
iThome鐵人賽