真的不好意思,查看很多方法了,但是都改不出來,再麻煩大家解惑了,感謝
SELECT MIN(last)
FROM Data.system
GROUP BY name
HAVING (COUNT(name) > 1)
查詢出來了 可是以下卻失敗
DELETE FROM Data.system WHERE name IN (
SELECT * FROM (
SELECT MIN(last) FROM Data.system GROUP BY name HAVING (COUNT(name) > 1)
) AS p
)
已邀請的邦友 {{ invite_list.length }}/5
create table it1120 (
id int unsigned not null auto_increment primary key
, name text
, idate date
);
insert into it1120 (name,idate) values
('小島南', '2021-11-01')
,('小島南', '2021-11-01')
,('小島南', '2021-11-03')
,('小島南', '2021-11-03')
,('初川南', '2021-11-01')
,('初川南', '2021-11-01')
,('初川南', '2021-11-02')
,('相澤南', '2021-11-01');
select name
from it1120
group by name
having count(name) > 1;
+-----------+
| name |
+-----------+
| 小島南 |
| 初川南 |
+-----------+
2 rows in set (0.01 sec)
select id, name, idate
, row_number() over(partition by name order by idate) as rn1
from it1120
order by id;
+----+-----------+------------+-----+
| id | name | idate | rn1 |
+----+-----------+------------+-----+
| 1 | 小島南 | 2021-11-01 | 1 |
| 2 | 小島南 | 2021-11-01 | 2 |
| 3 | 小島南 | 2021-11-03 | 3 |
| 4 | 小島南 | 2021-11-03 | 4 |
| 5 | 初川南 | 2021-11-01 | 1 |
| 6 | 初川南 | 2021-11-01 | 2 |
| 7 | 初川南 | 2021-11-02 | 3 |
| 8 | 相澤南 | 2021-11-01 | 1 |
+----+-----------+------------+-----+
8 rows in set (0.00 sec)
with t1(id, rn) as (
select id
, row_number() over(partition by name order by idate) as rn1
from it1120
)
delete
from it1120
where id in (
select id
from t1
where rn > 1);
Query OK, 5 rows affected (0.01 sec)
select * from it1120;
+----+-----------+------------+
| id | name | idate |
+----+-----------+------------+
| 1 | 小島南 | 2021-11-01 |
| 5 | 初川南 | 2021-11-01 |
| 8 | 相澤南 | 2021-11-01 |
+----+-----------+------------+
3 rows in set (0.00 sec)
作為刪除的條件式,你的子查詢中回傳的唯一欄位 MIN(last) 會是一個數值,而不是你要用來當作刪除條件的 name
這個我大概知道你想要做甚麼@@..
你想要把重複資料變成1筆對吧~
若是這樣~我的作法是將資料group後~複製到暫存的新表~
清空原表資料~再從暫存新表新增回來~
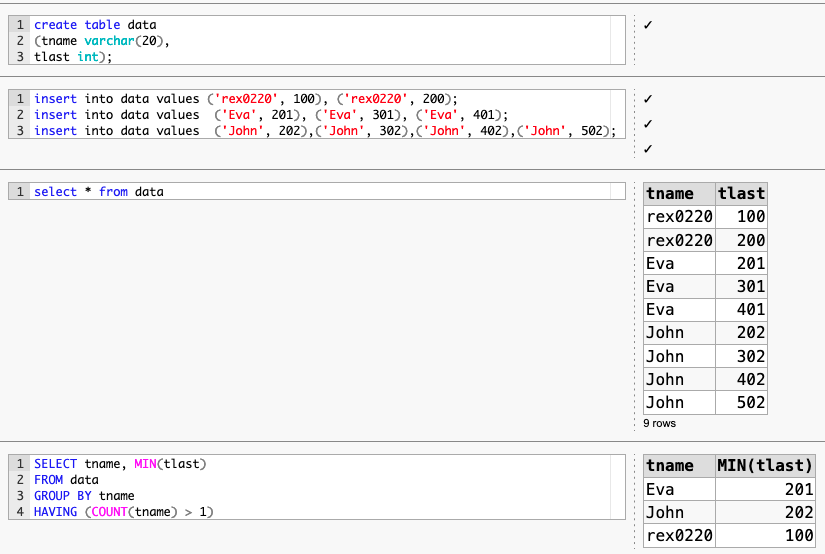
假設如同純真的人說的【要把COUNT(name) > 1的多餘資料刪除】,在借用海綿寶寶建的資料,SQL 如下:
tname = Blue,tlast = 10 要另外處裡
create table data
(tname varchar(20),
tlast int);
insert into data values ('Alex', 50);
insert into data values ('Blue', 10),('Blue', 10);
insert into data values ('Eva', 201), ('Eva', 301), ('Eva', 401);
insert into data values ('rex0220', 100), ('rex0220', 200), ('rex0220', 200);
DELETE FROM data
WHERE tlast NOT IN (
SELECT * FROM (
SELECT MIN(tlast) FROM data
GROUP BY tname
) AS A)
那真的好像動資料庫不是個好方法,畢竟之後還是會有需要刪除的時候,那我決定只從查詢著手的話,select如網址內表二的結果該怎麼做
https://dbfiddle.uk/?rdbms=mysql_5.5&fiddle=eef40c26d93dcfd6a9751257c27307b5
喔~改成先查詢問題資料~再決定刪除吧?
沒有 我只需要顯示出來而已 決定舊資料保留