最近在自學python爬蟲,卻遇到了問題,想請求幫解惑,程式碼如下: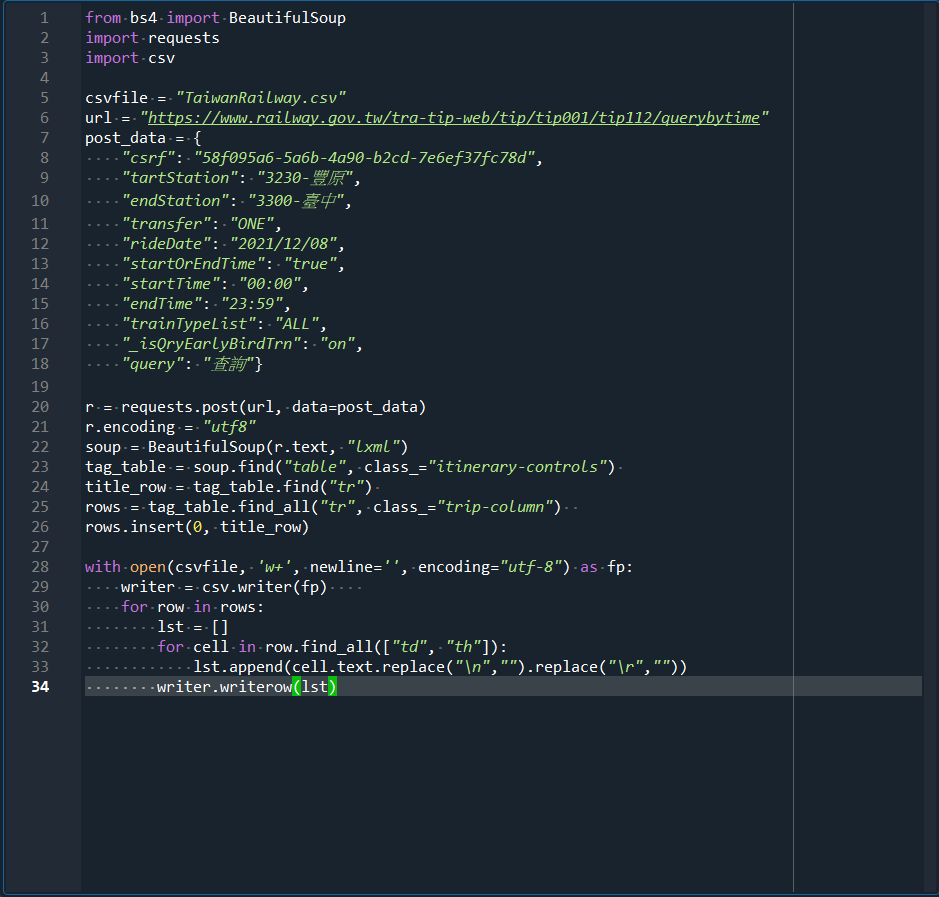
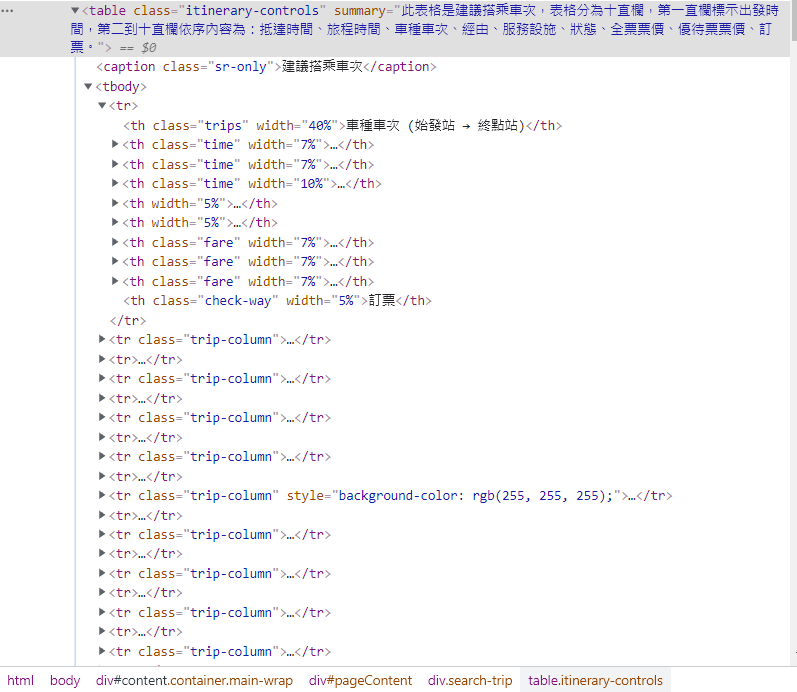
想抓取的是table class="itinerary-controls"底下的第一個tr,但總在第24行出現找不到的錯誤訊息,請問到底是哪裡出錯了?
錯誤訊息如下:
爬蟲的網址:https://www.railway.gov.tw/tra-tip-web/tip/tip001/tip112/querybytime
已邀請的邦友 {{ invite_list.length }}/5
csrf是伺服器動態產生用來擋Cross Site Request Forgery用的token,如果這欄不對,post出去不會得到結果,所以你也找不到你要找的table。
你得到這一頁的前一頁送一次request來取這個token,然後送出post。這個前一頁應該是:https://www.railway.gov.tw/tra-tip-web/tip/tip001/tip112/gobytime
csrf在form標籤裡的樣子:

 iThome鐵人賽
iThome鐵人賽